




“ hbase是大数据系统中,常见的一个列式存储组件,那么在数仓中,我们该怎么用它。还有和hive的最大区别在哪些地方?”
“ hbase是大数据系统中,常见的一个列式存储组件,那么在数仓中,我们该怎么用它。还有和hive的最大区别在哪些地方?”
什么是HBase
HBASE是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。它是一个实时读写的分布式数据库。它利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为其分布式协同服务,它主要用来存储非结构化和半结构化的松散数据(列存 NoSQL 数据库)。
Hbase特殊的数据模型

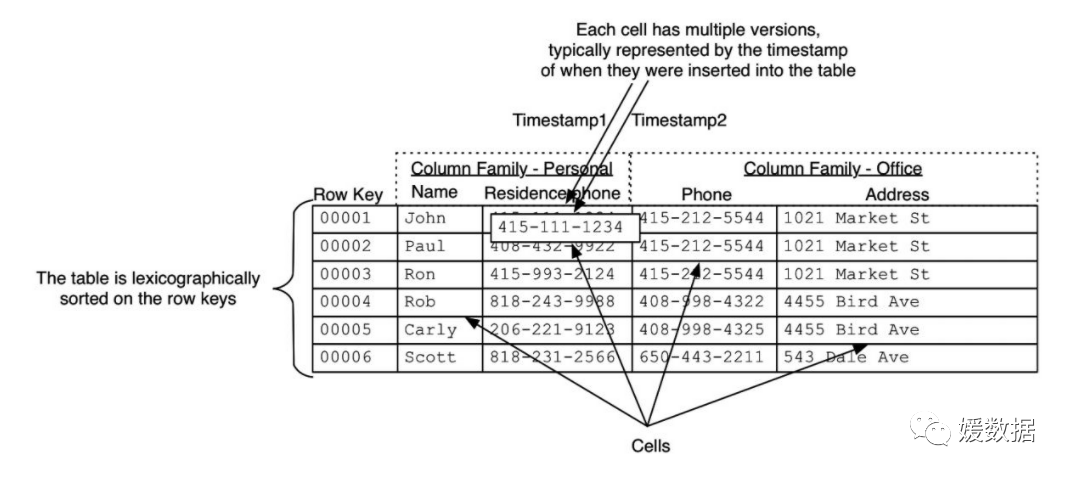
上图中的HBase表只是一个逻辑上的概念,对于没有存储数据的cell并不占用实际的存储空间。而上图中的一行数据可以表示成下面的json结构:
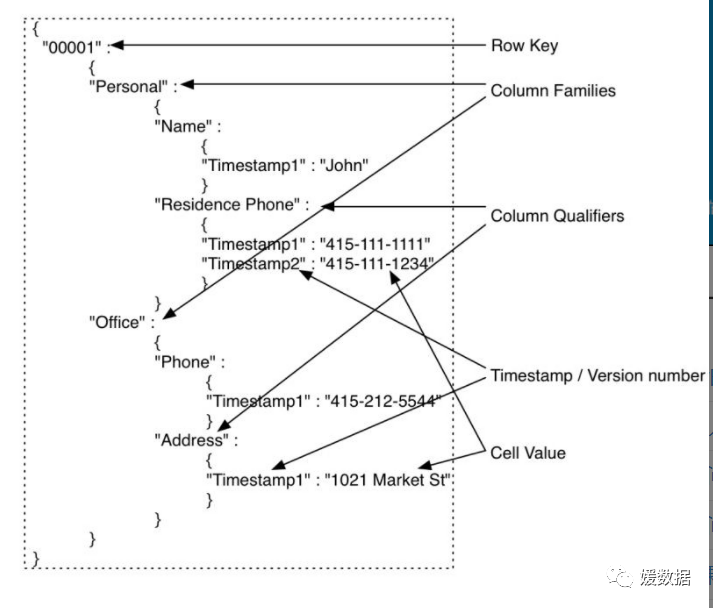
Hbase逻辑存储结构概念:

HBase的数据模型和数据库很类似,但底层的存储结构完全不同。
HBase的数据模型分为:store(相当于表)、列、Row Key(行)、region(列的集合)、列族
(1)store
store就相当于一个表,由多行和多列组成,store中包含memstore,主要用来写数据,每个store对应一个列族。
设置memstore的主要原因是:存储在HDFS上的数据需要按照row key 排序。而HDFS本身被设计为顺序读写,不允许修改。这样的话,HBase就不能够高效的写数据,因为要写入到HBase的数据不会被排序,这也就意味着要存入HDFS中的数据是无序的,这显然不利于存储数据后的数据检索。
所以memstore的作用是当写入数据到store时,数据先写到memstore中,只有当数据量达到一定阈值,之间的时间足够memstore将数据进行排序后再统一写到HDFS中。
(2)列
就是数据的一列,建表时,需要先指定列族才能创建列,每个列都由Column Famile(列族)和Column Qualifier(列限定符即列名)决定
(3)列族
包括多列,设置列族的目的是防止宽表(即有多列数据的表),即当数据列数很多是,设置列族可以大大提高检索效率。
如:要查找一个值,先找到这个值所对应列所在的列族(在HDFS中文件的存储是按store来分的,即文件的存储是按列族来分的)就可以精确的找到这个列族所在的文件进行检索。
(4)Row Key
代表一行数据,一列数据的唯一标识。Row Key的排序是逐位排的,即先比较第一位,若比出大小则不用对后面的进行比较,若第一位未比出大小,则要继续顺位比较下去,直到比较出来为止(注:若这一位为空则比0小)。
如:row_key1<row_key_11 ; row_key11<row_key2
(5)Region
region的作用是防止高表,即防止数据行数过多,可以将数据量大的表切分为多个region
Hbase 物理存储结构概念:

storeFile即为HBase底层存储数据的结构
如图可以清晰地看到在逻辑结构表中的每一个值对应物理存储结构的一行,每个值都有一些其它属性,如:
Row Key代表列的唯一标识,用以标识该数据在这一行中;
Column Family代表这个值所在的列族;
Column Qualifier唯一标识这个值所在的列;
Time Stamp区分不同版本的数据,如当你修改这个数据后,原来的数据并不会直接被删除,而是因为新修改的数据时间戳大于之前数据的时间戳,所以在上层显示的就是新修改的数据;
Type用于鉴别数据的类型(仅有put和out两种)当数据被删除时Type值为out,此时并不会显示时间戳更小的那个值,因为此数据仍然存在,并没有被删除。
HBase底层使用这样的存储模式,可以大大提高数据的读取效率,并且提升了数据的容错率,因为以前的数据都没有被删除而是保存起来了,只不过我们看不到。
01
—

hbase哪些场景用

一、Hbase能做什么?
1. 海量数据存储:
上百亿行 x 上百万列
并没有列的限制
当表非常大的时候才能发挥这个作用, 最多百万行的话,没有必要放入hbase中
2. 准实时查询:
百亿行 x 百万列,在百毫秒以内
二、Hbase在实际场景中的应用:
1. 交通方面:
船舶GPS信息,全长江的船舶GPS信息,每天有1千万左右的数据存储。
2. 金融方面:
消费信息,贷款信息,信用卡还款信息、白名单用户的查询等
3. 电商:
淘宝的交易信息等,物流信息,浏览信息等
4. 移动:
通话信息等,都是基于HBase的存储。
02
—
hbase和hive的最大区别和关系?

最大的应用区别在于,hbase通常用于实时查询,比如,Facebook用Hbase进行消息和实时的分析。它也可以用来统计Facebook的连接数。 Hive是Hadoop数据仓库,严格来说,不是数据库,主要是让开发人员能够通过SQL来计算和处理HDFS上的结构化数据,Hive适用于离线的批量数据计算。Hive通过SQL来处理和计算HDFS的数据,Hive会将SQL翻译为Mapreduce来处理数据。
Hive和Hbase的关系
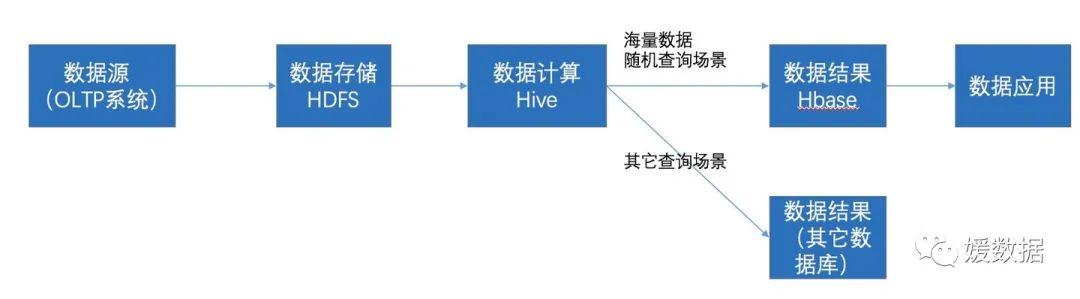
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
通过ETL工具将数据源抽取到HDFS存储;
通过Hive清洗、处理和计算原始数据;
HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
数据应用从HBase查询数据;
03
—
hbase查询特别难,怎么查询?

一般HBase的查询方案:
方案一:hbase shell交互方式
通过RowKey(要把多条件组合查询的字段都拼接在RowKey中显然不太可能),或者全表扫描再结合过滤器筛选出目标数据(太低效)。
方案二:建立hive外部表映射,通过cdh平台,hue中进行查询
CREATE EXTERNAL TABLE cbd_cds.jason_test(
key string,
shop string,
future_end_time string
)STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES("hbase.columns.mapping" =":key,f1:shop,f1:future_end_time")
TBLPROPERTIES("hbase.table.name" = "cbd:test");
方案三:一般通过设计HBase的二级索引来解决这个问题。
HBase本身只提供基于行键和全表扫描的查询,而行键索引单一,对于多维度的查询困难。不论什么实现二级索引基本都是空间换时间,实现倒叙索引。HBase的一级索引就是rowkey,我们只能通过rowkey进行检索。如果我们相对hbase里面列族的列列进行一些组合查询,就需要采用HBase的二级索引方案来进行多条件的查询。二级索引的本质就是建立各列值与行键之间的映射关系。
常见的二级索引方案:
将是否基于Coprocessor方案分为两个方向的方案:
A.基于Coprocessor方案:
开源方案:
华为的hindex :基于0.94版本,当年刚出来的时候比较火,但是版本较旧,看GitHub项目地址最近这几年就没更新过。Apache Phoenix:功能围绕着SQL on hbase,支持和兼容多个hbase版本, 二级索引只是其中一块功能。二级索引的创建和管理直接有SQL语法支持,使用起来很简便, 该项目目前社区活跃度和版本更新迭代情况都比较好。
ApachePhoenix:在目前开源的方案中,是一个比较优的选择。主打SQL on HBase , 基于SQL能完成HBase的CRUD操作,支持JDBC协议。Apache Phoenix在Hadoop生态里面位置:
B.基于非Coprocessor方案:
常见的是采用底层基于Apache Lucene的Elasticsearch(下面简称ES)或Apache Solr ,来构建强大的索引能力、搜索能力, 例如支持模糊查询、全文检索、组合查询、排序等。
比如:
增量索引:日常持续接入的数据源,进行增量的索引更新全量索引:配套基于Spark/MR的批量索引创建/更新程序, 用于初次或重建已有HBase库表的索引
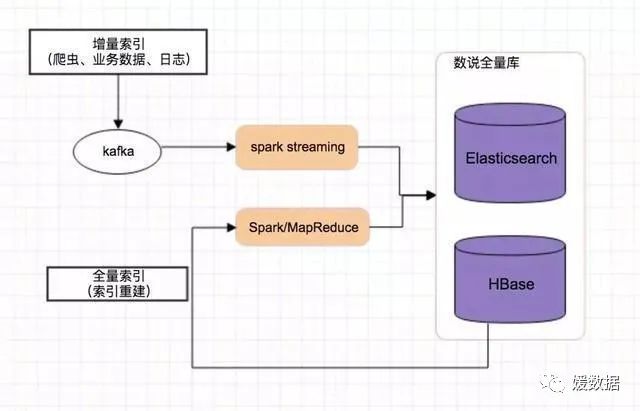
04
—
hbase使用中会有什么问题?


Hbase也会出现数据倾斜或者热点问题!
在使用hbase中,不免会出现热点问题。那么什么叫做热点问题呢?就是某些region的数据量比较大,某些region的数据量比较小,就导致了某几个的region server的负载量较大。
当我们采用默认的配置时,它会默认使用一个region,当region的数据量大到一定程度时,会发生split分成两个region。通常情况下,我们存储的rowkey都是以字典顺序存储,这样的话,由于region存在start key和end key,每次存储新的rowkey都会往新产生的region里存储(因为它的rowkey要大于之前的region的start key),于是就会导致之前的region存储的数据量小,而之后的region存储的数据量大。region默认发生split的条件为:min(flushsizenn,maxFilesize),这里n为(2*split次数-1),而maxFilesize默认为10G。即在第五次split时为10G,之后均为10G。
这里我就给大家讲解一下在工作中比较常用的处理热点问题的一种方法,预分区机制。
预分区机制
先放出代码:
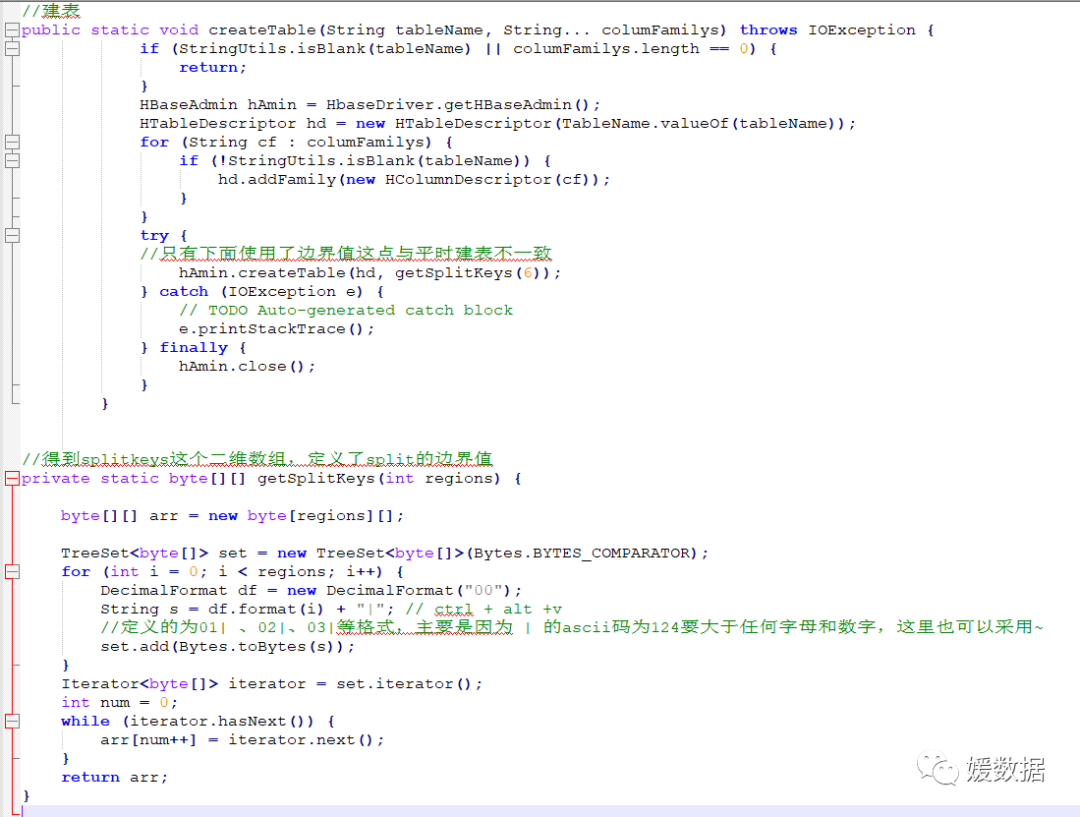
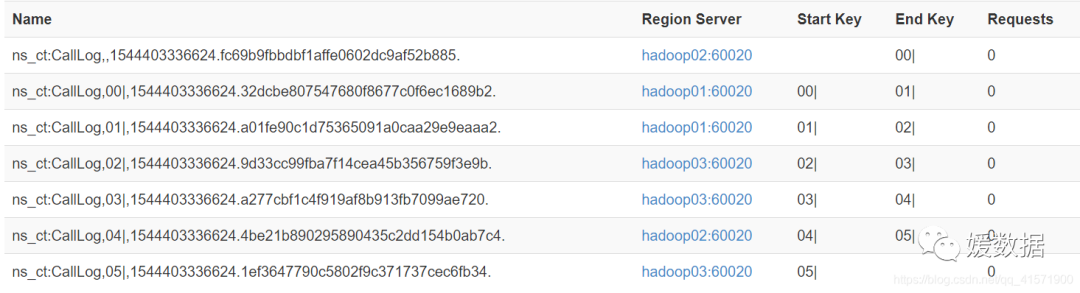
这里采用的原理是,我假设设定了6个region,它会分为7个region,第一个的region的startkey为0,stopkey为 00|;第二个region的startkey为00|,stopkey为001|;以此类推,第七个region的startkey为005|,stopkey为无穷大。这里就会产生疑问,明明建立6个region为什么会生成7个呢,这是因为第七个region用于存放计算错误的数据,当第七个region存在数据了,就说明程序出现了问题。
这时,我对原先设定的rowkey进行hash取值,并对分区数也就是6进行取余,将得到的数通过format格式化成两位数,组合拼接到rowkey上,这样我得到的rowkey就变成了这样:00_rowkey1,01_rowkey2等等。再将数据存储到hbase时,就会将00_rowkey的放到第一个region也就是stopkey为00|中,因为我之前说了|的ascii码值大于任何数字、字母以及下划线,依次类推,01_rowkey2就是放在第二个region,startkey为00|,stopkey为01|中。
当处理好的数据存放入hbase中,就如下图所示:
05
—
hbase一般处理架构的哪一层


Python分布式爬虫爬取数据后,经历kafka消息中间件,直接入hbase
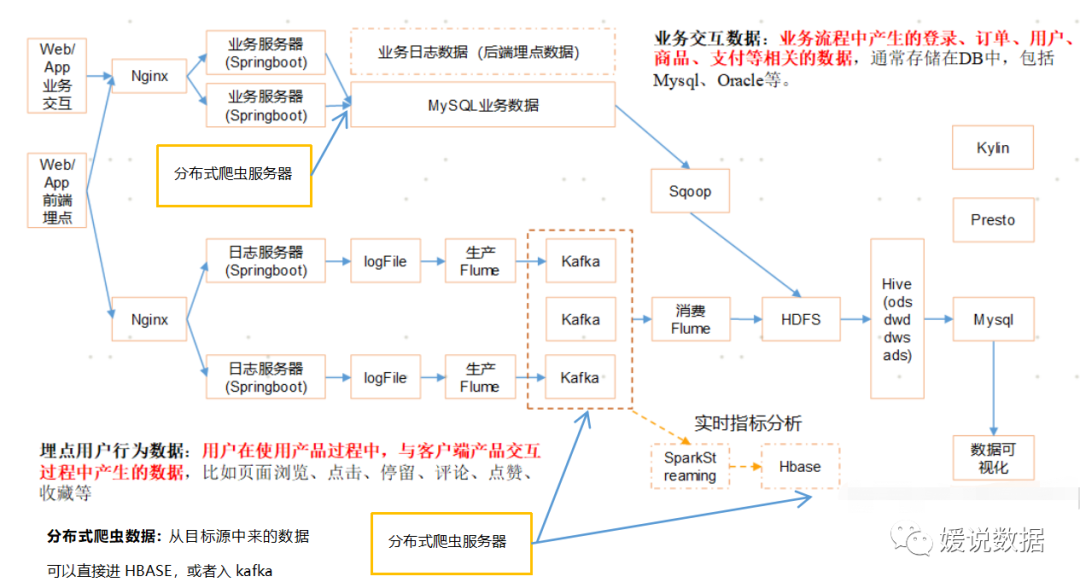
HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase。比如在用户画像场景中,用户标签数据经过ETL将每个用户身上的标签聚合后插入到目标表中,聚合后数据存储为每个用户id,以及他身上对应的标签集合,接下来是将Hive中的数据导入Hbase, 便于线上接口实时调用库中数据。
#我是媛姐,一枚有多年大数据经验的程序媛,打过螺丝搬过砖,关注数仓,关注分析。愿你我走得更远!
点击上方

蓝字
关注我们
