




一个数据库显示了复制延迟,同一复制层次结构的所有其他实例也是如此,所有这些实例都驻留在Openstack中。
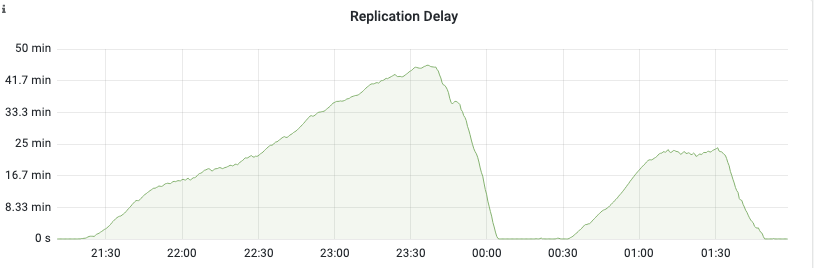
在21:30之前不久,数据库开始延迟,直到23:45左右,这时它开始慢慢地赶上。00:30以后,我们又延迟了一段时间,然后在01:45左右,我们赶上了。
数据库有时正深入到复制延迟中。光金属是不行的。
基本事实
虚拟机是一个不错的硬件刀片模拟,16C/32T,128GB内存。
数据位于由Ceph支持的持久卷上。
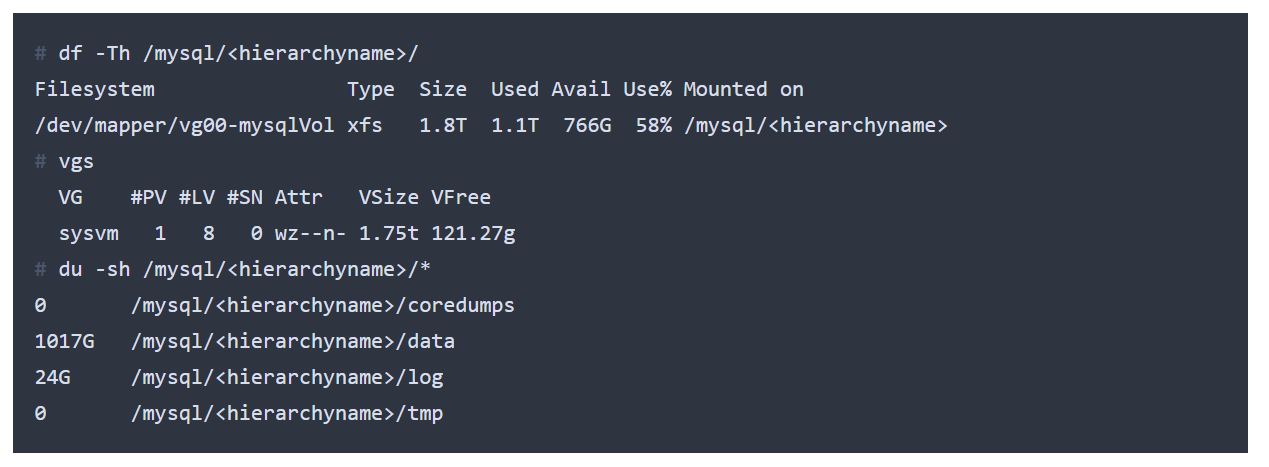
此数据库不适合缓冲池:工作集太大。我们在一个预热的数据库中看到读取流量,速度为几十MB/s。
登记入住information_schema.tables,该数据库中最大的两个表的大小约为200 GB。它们似乎是完全可以访问的,很少或根本没有可利用的引用位置。因此,为了抑制这些读取,我们需要提供三倍于384 GB的内存。既然我们做不到,我们需要处理I/O。
让我们看看I/O:当运行iostat时,使用iostat -x -k 10,并放弃第一个输出。它包含系统启动后收集的数据,平均间隔非常大。我们要一个干净的10秒样品。
膏体:
Device r/s w/s rMB/s wMB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util sdc 4302.00 348.00 67.22 1.22 0.00 0.00 0.00 0.00 1.24 1.91 6.00 16.00 3.58 0.21 99.70 sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sda 0.00 4.00 0.00 0.02 0.00 0.00 0.00 0.00 0.00 2.50 0.01 0.00 4.00 2.75 1.10 loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 dm-0 4304.00 347.00 67.25 1.21 0.00 0.00 0.00 0.00 1.24 1.93 6.02 16.00 3.58 0.21 99.70复制
我们看到繁忙的驱动器是sdc,即持久卷。我们看到服务时间增加了(r_await,单位ms)和队列(阿库sz,单位为“观察间隔内队列中的平均请求数”,即10s)。
我们还看到大约4300个读请求/秒和67 MB/s的读流量。
以前在其他项目中的一些经验表明,可能缺少一个关键的信息。这个复制链不再是在裸机上,而是在Openstack上运行。Openstack中所有到磁盘的流量都是限额的。
Openstack上的任何I/O问题都是不可调试的,除非您知道影响您的配额。实际上:
# openstack volume qos show <uuid>
+--------------+----------------------------------------------------+
| Field | Value |
+--------------+----------------------------------------------------+
| associations | standard-iops |
| consumer | front-end |
| id | <uuid> |
| name | 200MB/s-3000iops |
| properties | total_bytes_sec='209715200', total_iops_sec='3000' |
+--------------+----------------------------------------------------+
复制我们允许最大200 MB/s和最高3000 IOPS。在该系统中,我们可以看到一个67 MB/s的正常带宽,但是IOPS达到了顶峰。
当我们在grafana的Single Instance Info面板中放大复制延迟的一个阶段时,我们就可以直接了解到它的底部。
复制延迟间隔:
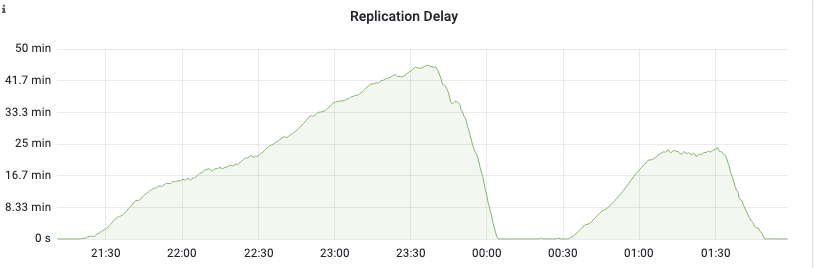
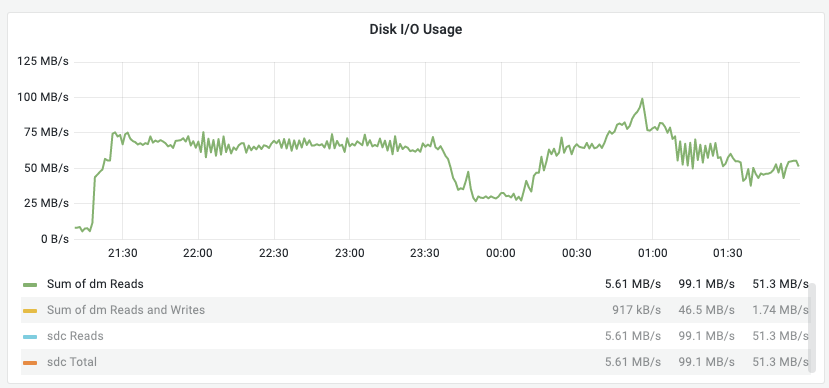
当我们有复制延迟时,我们可以看到70 ish MB/s的dm reads总和是一条直线。这远远低于配额。
看看IOPS:
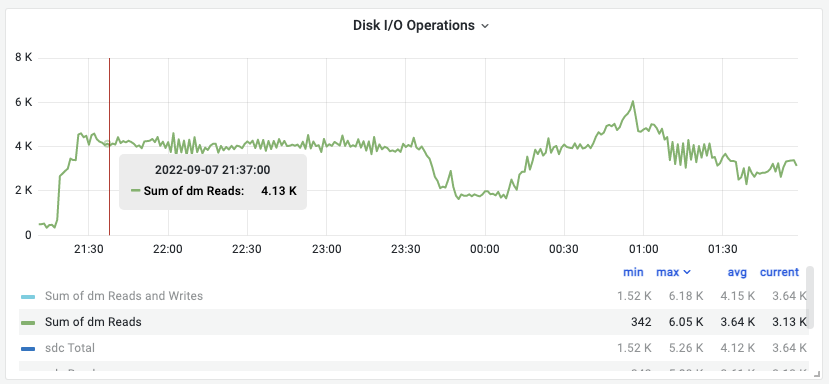
这是所有dm读取的总和,我们只对设备的读取感兴趣。但我们看到了一条直线,或者说是某种资源的极限。另外,该行的读/秒大约为4000,而配额为3000 IOPS。这说明我们在IOPS部门遇到了资源枯竭。
这很糟糕吗?
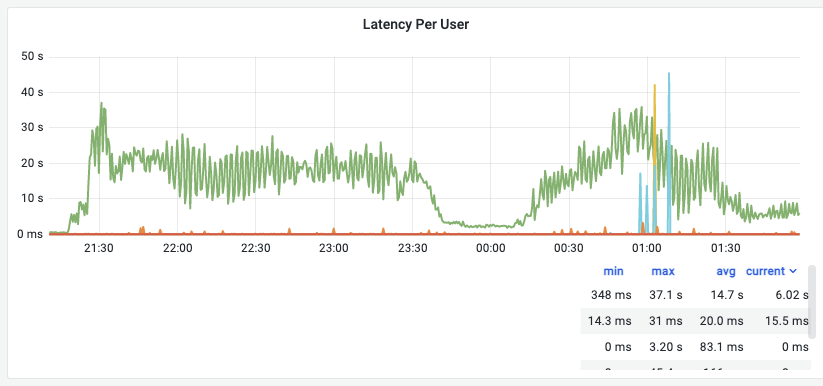
观察到的生产用户的语句延迟从最小348毫秒增加到最大37100毫秒(37.1秒)。这比正常情况差100倍左右。
观察到的语句延迟也在迅速上下跳跃。系统性能不仅不好,而且非常不可预测,在一个宽阔的走廊上有高频振荡。
这通常表明令牌桶配额机制与令牌桶本身的评估周期发生共振:
负载正在流失,然后配额评估检查周期到来,并在超过配额的系统上狠狠地咬了一口,基本上停止了它。系统停止,因为没有I/O的数据库什么也不做。然后它在令牌桶中累积新的性能令牌,并在下一个循环中执行,立即耗尽令牌池并超过配额。然后循环重复。
如果配额适用于consumer=backend .
用户对性能的所有期望都被打破了,系统也可能离线。此外,性能上的差异可能会产生输入信号尖峰相关的系统,如果存在共振,则会影响系统的性能。
如果不知道配额限制并进行检查,这几乎是不可调试的,有时您可能会看到受影响系统下游的次要影响。有了适当的指标和对配额的了解,这是显而易见的。
注意性能图中的直线
负荷是尖的,直线不存在
对于我们的系统来说,这是一个普遍的事实:总的来说,我们的负载是尖头的。它有高峰和低谷,没有高原或直线(除了卡夫卡和其他排队系统和由他们供养的系统之外)。
也就是说,如果你看到一条直线,我会看到一个资源被耗尽并限制了系统性能。
在这种情况下,耗尽的资源是IOPS配额。
在过去的其他情况下,脏缓冲池页面图中的直线表示重做日志空间耗尽,或类似的性能瓶颈。
原文标题:MySQL: Straight lines
原文作者:KRISTIAN KÖHNTOPP
原文地址:https://blog.koehntopp.info/2022/09/08/mysql-straight-lines.html
