




介绍
管理和组织大数据有不同的方式和平台。它提供了一个完整且权威的数据存储库,支持数据分析、商业智能和机器学习。
.png)
让我们简单了解一下 数据湖(Data Lake) 在技术世界中的含义。
什么是数据湖?
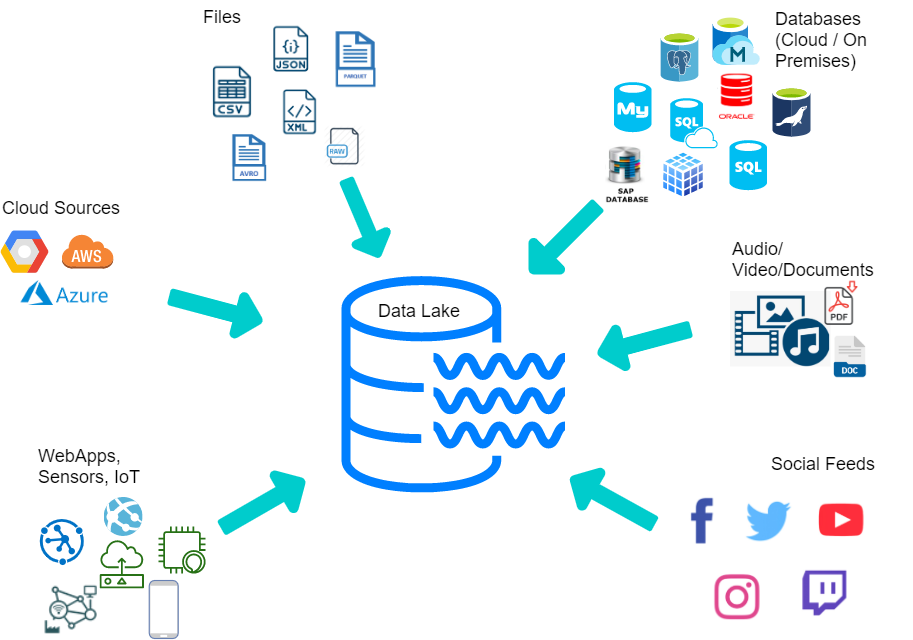
将数据湖想象成一个大型容器,充当存储库,它可以存储各种格式的大量数据,例如非结构化、半结构化和结构化数据。这是一个可以处理其原生格式的每种类型数据的地方,没有硬性帐户或文件大小限制。
数据湖可以处理所有类型的数据,例如图像、视频、音频和文档,这对于当今的机器学习和高级分析案例至关重要。随着人们想要更好的数据探索,尤其是在商业和技术领域,它们变得越来越重要。通过这种方式,公司可以减少搜索和收集数据所花费的时间,从而有更多时间进行分析。将数据合并到一个地方或大部分地方会更容易。与竞争对手相比,最新数据可帮助企业执行高级分析并显示最新信息。
数据的数量、种类和速度
今天数据的三个 V (volume:体积 velocity:速度 variety:种类)促使我们认识到,没有一种万能的数据库可以满足所有数据需求。这些 V 是当今数据的数量、速度和种类。数据量增长巨大;随着5G技术的扩展,由于它提供的广泛可能性,它将变得越来越大。
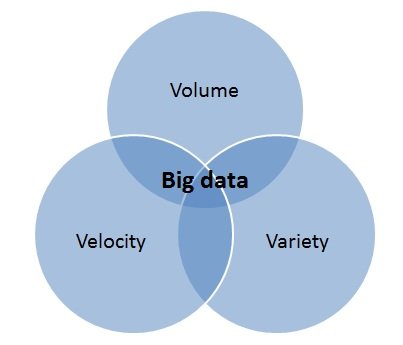
这些变化的速度如此之快,以至于许多统计数据表明,自 2016 年以来已经生成了 90% 的数据。这意味着与过去几年中的大数据一样庞大且意义重大,它只会得到随着技术使世界变得更加紧密,更大。关于多样性,我们知道在 2000 年代初期,流媒体仅限于音频,而宽带主要用于网页浏览、电子邮件和下载。
近十年末,随着互联网的扩展和“智能手机时代”的开始,业务重点转向音频和视频的流媒体服务、社交媒体的广泛使用、视频游戏流媒体平台等各种格式的数据消费。
使用数据湖的优势
下面我们可以看到使用 Data Lake 作为大数据管理解决方案的好处;
- 数据存储的简单性——通过接受所有数据类型,Data Lake 消除了在数据存储期间对数据建模的需要。在搜索和检查数据以进行进一步分析时,我们可能会这样做。所以我们可以在必要时对它们进行过滤和建模。
- 可扩展性——在考虑可扩展性时,提供可扩展性并且与传统数据仓库相比相对便宜。
- 多功能性——数据湖可以存储来自各种来源的多结构化数据。简单地说,数据湖可以存储日志、XML、多媒体、传感器数据、二进制数据、社交数据、聊天、人员数据等等。
- 灵活性——传统模式要求数据采用特定格式。虽然传统的数据仓库产品基于模式,但通过 Hadoop、Databricks、Google BigQuery、Snowflake 和其他平台,Data Lake 允许您无模式,或者您可以为相同的数据定义多个模式,这非常适合分析。
- 多种格式——数据湖为分析提供了不同的能力和语言支持,而传统的数据仓库技术大多支持SQL,适用于简单的分析。
- 高级分析——与数据仓库不同,数据湖擅长利用大量连贯数据的可用性以及深度学习算法。它有助于实时决策分析。
- 单一数据平台——在单一平台上查找每条信息的能力不需要太多解释。根据我们的日常任务,我们可以想象从一个地方到另一个地方只是为了获取与我们感兴趣的一种见解相关的信息的痛苦。
- 这些只是一些主要好处,还有其他重要原因您应该了解它们。
物联网分析中数据湖的好处
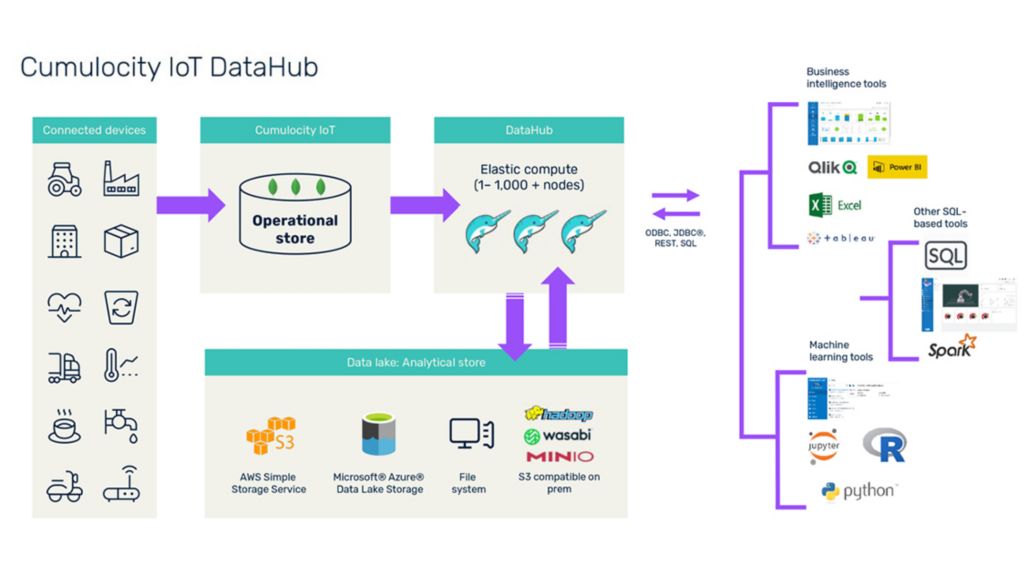
使用 Software AG 的 Cumulocity IoT DataHub 将您的 IoT 数据转化为您的优势。借助 Cumulocity IoT DataHub,我们可以在流式分析和历史分析之间架起一座桥梁,从而简化 IT 管理员的流程,并使企业能够获得对运营和绩效的新见解。
简化长期数据存储管理
Cumulocity IoT DataHub 定期从本地或边缘的运营数据存储中获取数据,并将其转换为对分析查询非常有效的紧凑格式,并将其放置在数据湖中的分析存储中。Cumulocity IoT DataHub 可以支持许多设备,对于每次卸载,Cumulocity IoT DataHub 将每个设备的警报、事件、测量和库存数据移动到数据湖中。
降低物联网数据存储成本
分析存储可以托管在您选择的 Amazon® S3 或 Microsoft® Azure® Data Lake 存储上。云存储极大地降低了创建和管理数据湖的成本。Cumulocity IoT DataHub 还支持文件系统和 Hadoop® 分布式文件系统 (HDFS) 数据存储。
物联网数据的可扩展 SQL 查询
IoT DataHub 旨在支持由任意数量的设备组成的 IoT 解决方案,并且可以扩展以管理每个设备产生的数据。为了分析这种设备数据的冲击,Cumulocity IoT DataHub 几十年来一直提供 SQL,这是数据处理的通用语言。释放 SQL 的力量,将原始 IoT 设备数据快速转换为有意义的信息。
BI的标准接口
IoT DataHub 充当集成层,支持对历史 IoT 数据进行高性能 SQL 查询,这些数据可用于广泛的商业智能或分析应用程序、机器学习培训或其他使用 Arrow Flight 等标准的自定义应用程序, JDBC®、ODBC、REST 和 SQL。
Cumulocity IoT DataHub 是如何工作的?
IoT DataHub 将您的数据从 Cumulocity IoT 中的操作存储移动到数据湖,以将原始 IoT 数据转换为高效 SQL 查询、报告和智能所需的结构化、压缩格式。这种“卸载”过程允许您创建廉价且长期的设备数据存档。
数据湖中的数据是什么样的?这种转换后的表格数据以 Apache Parquet™ 格式存储,为您提供数据的柱状表示,便于分析和高效存储。Parquet 是“大数据”工具中事实上的数据格式,除了使用 Cumulocity IoT DataHub 之外,您还可以使用 Apache Spark™ 等工具独立处理数据。考虑到常见的分析模式,Cumulocity IoT DataHub 将 Parquet 文件组织到一个临时文件夹层次结构中。后台的其他清理机制会定期压缩较小的 Parquet 文件,从而提高整体查询性能(假设硬盘驱动器之前已进行碎片整理)。
下载完成后,您可以使用自己喜欢的 BI 和数据科学工具以交互式速度分析数据并从中获得洞察力。然后,您可以通过准确提取您需要的信息并将信息与其他交易系统的信息集成来获得交易洞察力。
将来自企业系统的洞察与物联网数据相结合
Cumulocity IoT DataHub 允许您将您的 BI 查询和构建工具与您的 IoT 数据连接起来,这样您就可以从数据中提取各种强大的业务洞察力。它提供 SQL 作为查询接口,数据处理和分析的通用语言。Dremio™ 是一个执行 SQL 查询的内部引擎。由于其高度可扩展的特性,Dremio 可以轻松处理各种分析查询。
借助 IoT DataHub,您可以快速连接您选择的工具或应用程序,包括:
- 使用 JDBC 或 ODBC 的 BI 工具
- 使用通过 ODBC 连接的 Python 脚本的数据科学应用程序
- 自定义应用程序使用 JDBC 用于 Java® 生态系统,ODBC 用于 .NET、Python 等,REST 用于 Web 应用程序(Cumulocity IoT)
机器学习模型的训练
ML 因深入了解业务和制造流程而广受欢迎。拥有的数据越多,机器学习模型中的信息就越可靠。Cumulocity IoT DataHub 通过以适合分析的结构良好的格式提供所有 IoT 数据,为训练复杂的机器学习模型铺平了道路。只需通过 ODBC、JDBC 或 REST 连接您最喜欢的数据科学工具,然后开始处理您的数据。例如,您可以根据阀门故障状态训练模型,以查看哪些因素表明阀门即将发生故障。稍后,将这些见解与您在 Cumulocity IoT 中的实时数据结合使用,在阀门主动破裂之前更换阀门。这就是将实时数据与历史数据相结合的力量。
数据湖与数据仓库
数据湖倾向于在人们访问数据时快速接收和准备数据。另一方面,使用数据仓库,您甚至在将数据发布到数据仓库之前都会非常仔细地准备数据。
与将数据存储在文件或文件夹中并用作已为特定目的处理的结构化和过滤数据的存储库的分层数据仓库相比,数据湖使用平面架构以原生原始形式存储数据. 用途尚未定义的格式。存储所有接收到的数据的不可变数据摄取层的另一个好处对于审计、数据发现、可重复性和纠正数据流中的任何错误都很宝贵。
结论
数据湖可以处理任何类型的数据,例如图像、视频、音频和文档,这对于当今的机器学习和高级分析案例至关重要。随着人们想要更好的数据探索,尤其是在商业和技术领域,它们变得越来越重要。通过这种方式,公司可以减少搜索和收集数据所花费的时间,从而有更多时间进行分析。
- 这些变化的速度如此之快,以至于许多统计数据表明,自 2016 年以来已经生成了 90% 的数据。这意味着与过去几年中的大数据一样庞大且意义重大,它只会得到随着技术使世界变得更加紧密,更大。
- 数据湖倾向于在人们访问数据时快速接收和准备数据。另一方面,使用数据仓库,您甚至在将数据发布到数据仓库之前都非常仔细地准备了数据。
- IoT DataHub 充当集成层,支持对历史 IoT 数据进行高性能 SQL 查询,这些数据可用于广泛的商业智能或分析应用程序、机器学习培训或其他使用 Arrow Flight 等标准的自定义应用程序, JDBC®、ODBC、REST 和 SQL。
- 分析存储可以托管在您选择的 Amazon® S3 或 Microsoft® Azure® Data Lake 存储上。云存储极大地降低了创建和管理数据湖的成本。Cumulocity IoT DataHub 还支持文件系统和 Hadoop® 分布式文件系统 (HDFS) 数据存储。



