




介绍
来自不同来源的数据被带到一个位置,然后转换为数据仓库可以处理和存储的格式。例如,一家公司存储有关其客户、产品、员工、工资、销售的数据。老板可能会询问最新的成本削减措施,而要获得答案将需要分析前面提到的数据。与基本的运营数据存储库不同,数据仓库包含汇总的历史数据(从各种来源获取的有用数据)。
.png)
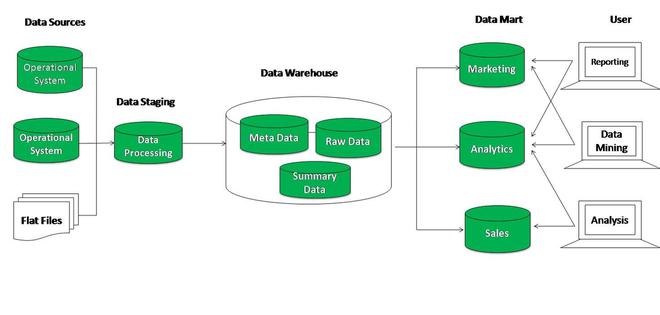
数据仓库
数据仓库 (DW) 存储来自操作系统和各种其他数据源的企业信息和数据。数据仓库旨在通过数据收集、整合、分析和研究来支持决策。它们可以在分析特定领域(例如“销售”)时使用,并且是现代商业智能的重要组成部分。1980 年代开发了一种数据仓库架构,以帮助将数据从操作系统转换为决策支持系统。数据仓库通常是公司大型机服务器的一部分。
穿孔卡片是存储计算机生成数据的第一个解决方案。在 1950 年代,打孔卡是美国政府和企业的重要组成部分。“请勿折叠、钻孔或破坏”的警告最初来自打孔标签。在 1980 年代之前经常使用打孔卡。它仍然用于记录投票和标准化测试的结果。
从 1960 年代开始,“磁存储”逐渐取代了穿孔卡片。磁盘存储是数据存储的下一个进化步骤。磁盘存储(硬盘驱动器和软盘)在 1964 年开始流行,允许直接访问数据,显著改善了笨重的磁带。
IBM 主要负责磁盘存储的早期开发。他们发明了软盘驱动器和硬盘驱动器。他们还因现在支持其产品的多项改进而受到赞誉。IBM 于 1956 年开始开发和制造磁盘存储设备。2003 年,将其“硬盘驱动器”业务出售给了日立。
数据库管理系统
紧随磁盘存储之后的是一种称为数据库管理系统 (DBMS) 的软件。1966 年,IBM 提出了当时称为信息管理系统的 DBMS。DBMS 软件旨在管理“磁盘存储”,包括以下功能:
- 确定数据的正确位置
- 解决多个数据单元映射到同一位置时的冲突
- 允许删除数据
- 当存储的数据不适合特定的有限物理位置时查找位置
- 快速的数据检索(这是最大的优势)
在线申请
20世纪60年代末和70年代初,在磁盘存储和DBMS软件流行后不久,商业在线应用程序进入了游戏领域。一旦发现数据可以直接访问,信息就开始在计算机之间共享。有大量的商业应用程序可以用于在线处理。举例说明
- 索赔处理
- 银行柜员处理
- 自动柜员机 (ATM) 处理
- 航班预订处理
- 零售点处理
- 生产控制处理
尽管有这些改进,但查找特定数据可能很困难,而且不一定值得信赖。找到的数据可能基于“旧”信息。此时,公司产生的数据如此之多,以至于人们无法相信数据的准确性。
4GL 技术与个人电脑
个人计算机技术允许任何人携带他们的计算机工作并在方便时进行处理。它导致了个人计算机软件的出现,并意识到个人计算机所有者可以将他的“个人”数据存储在他的计算机上。随着工作文化的这种变化,人们认为不再需要集中的 IT 部门。同时,开发并推广了一种称为4GL的技术。4GL 技术(开发于 1970 年代至 1990 年)基于这样一种理念,即编程和系统开发应该简单明了,并且任何人都应该能够做到。这种新技术也助长了集中式 IT 部门的解体。
4GL 技术和个人电脑解放了最终用户,使他们能够更好地控制计算机系统并高效、快速地搜索信息。释放最终用户并允许他们访问数据的主要目的是迈出了非常好的一步。4GL 和个人电脑,并在企业环境中迅速普及。但途中发生了意想不到的事情。关系数据库在 1980 年代变得非常流行。它比它的前辈更加用户友好。关系数据库管理系统 (RDBMS) 使用结构化查询语言 (SQL)。在 1980 年代后期,许多企业从大型机转向客户端服务器。员工现在收到了个人电脑,办公应用程序(Excel、Microsoft Word 和 Access)开始受到青睐。
对数据仓库的需求
在 1990 年代,发生了巨大的文化和技术变革。互联网的普及程度越来越高。由于新的自由贸易协定、电子化、全球化和网络化,竞争加剧了。这一新现实需要更高的商业智能,从而需要真正的数据仓库。
到 2000 年,许多企业发现,随着数据库和应用程序系统的激增,他们的系统集成不良,数据不一致。他们发现自己接收和存储了大量零散的数据。需要以某种方式整合数据,以提供在竞争激烈、瞬息万变的全球经济中做出决策所需的关键“商业智能”。企业开发数据仓库来整合他们从各种数据库中收到的数据,并帮助他们做出战略决策。
使用 NoSQL
随着数据仓库的出现,大数据的积累开始演变。这种积累需要计算机、智能手机、互联网和物联网的发展来提供数据。信用 卡和社交媒体也发挥了作用。
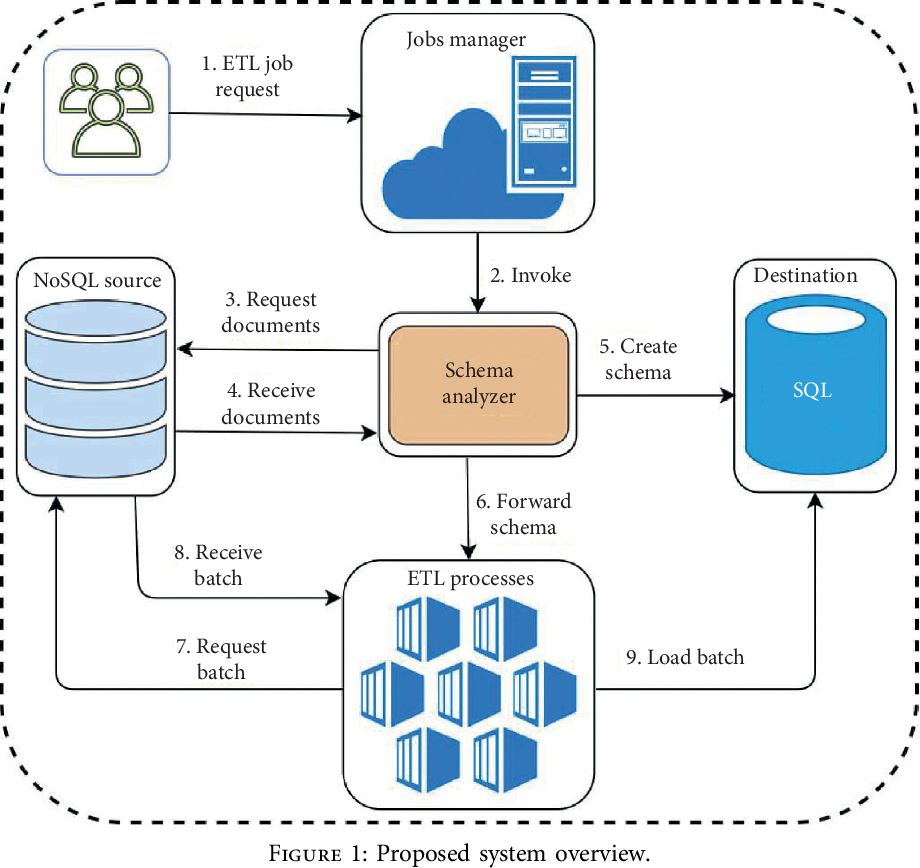
Facebook 于 2008 年开始使用 NoSQL。NoSQL 是一种架构相对简单的“非关系”数据库管理系统。在处理大型数据集时非常有用。NoSQL 数据库系统多种多样,虽然 SQL 系统通常比 NoSQL 系统具有更大的灵活性,但 SQL 中缺乏可扩展性(尽管最近发生了变化)给 NoSQL 系统带来了决定性的优势。非关系数据库(或 NoSQL)使用两个新概念:水平扩展(存储和工作的分布)和消除对结构化查询语言组织数据的需求。NoSql 数据库逐渐演变为包含各种不同的模型。Hadoop 和 Cassandra 是 225 多个可用的 NoSQL 样式数据库的两个示例。
数据仓库替代方案
在每个部门都有不同的目标、职责和优先级的大型组织中,数据孤岛可能是一种自然现象。数据孤岛是单个部门控制下的固定数据存储库,出于隐私和安全原因,已将其与其他部门的访问分开和隔离。当部门竞争而不是就共同目标进行协作时,也会出现数据孤岛。它们通常被视为协作和有效商业实践的障碍。
Data mart(数据集市)是为特定社区或工人群体服务的数据存储区域。它们是具有固定数据的存储库,并且有意受组织内单个部门的控制。
与数据仓库相比,数据湖对传入的数据使用更灵活的结构。数据的组织方式与湖数据库的模式相匹配,并使用更流畅的存储方法。数据湖仅在数据移动到应用层时为其添加结构。数据湖保留了原始数据结构,可用作理论上可以无限扩展的大数据的存储和检索系统。
Data Swamps (数据沼泽)可能是由于设计不当或被忽视的数据湖造成的。数据沼泽描述了无法正确记录存储数据的故障。这种情况使得分析和有效使用数据变得困难。尽管原始数据可能仍然存在,但如果没有上下文的适当元数据,Data Swamp 将无法恢复它。
Data Cube(数据立方体) 是一种将数据存储在三个或更多维度的矩阵中的软件。数据中的转换表示为已处理信息的表格和数组。表匹配数据字符串的行和数据类型的列后,数据立方体交叉引用来自一个数据源或多个数据源的表,增加每个数据点的细节。这种安排使研究人员能够找到比其他技术更深入的见解。
结论
数据仓库 (DW) 存储来自操作系统和各种其他数据源的企业信息和数据。数据仓库旨在通过数据收集、整合、分析和研究来支持决策。它们可以在分析特定领域(例如“销售”)时使用,并且是现代商业智能的重要组成部分。1980 年代开发了一种数据仓库架构,以帮助将数据从操作系统转换为决策支持系统。数据仓库通常是公司大型机服务器的一部分。
- 它比它的前辈更加用户友好。关系数据库管理系统 (RDBMS) 使用结构化查询语言 (SQL)。在 1980 年代后期,许多企业从大型机转向客户端服务器。
- 数据的组织方式与湖数据库的模式相匹配,并使用更流畅的存储方法。数据湖仅在数据移动到应用层时为其添加结构。
- IBM 主要负责磁盘存储的早期开发。他们发明了软盘驱动器和硬盘驱动器。他们还因现在支持其产品的多项改进而受到赞誉。IBM 于 1956 年开始开发和制造磁盘存储设备。2003 年,将其“硬盘驱动器”业务出售给了日立。
原文标题:The Need for Data Warehouse and Its Alternatives
原文作者:Chetan Dekate
原文地址:https://www.analyticsvidhya.com/blog/2022/10/the-need-for-data-warehouse-and-its-alternatives/



