




背景
Hudi可以用于构建实时数据湖,除了使用Spark/Flink计算引擎实时消费Kafka数据写入到Hudi表,也可以使用Hudi提供的基于kafka connect框架实现的hudi-sink-connector,轻松将Kafka数据导入到Hudi表。kafka connect是apache kafka的免费开源组件,它标准化了kafka与其他数据系统的集成,提供将数据从外部系统写入kafka的source connector和将数据从kafka写入到外部系统的sink connector。Kafka connect具备高扩展性、高可靠性、负载均衡、易用性(REST API)等特性。

保证exactly-once语义,无数据丢失或数据重复;支持多任务管理,允许connector按需扩缩容;复制
由于kafka sink connector在分布式环境运行并发执行多个tasks处理多个partitions数据。所以,hudi-sink-connector需要提供一个支持多tasks同时写入Hudi表的并发模型。

实践案例
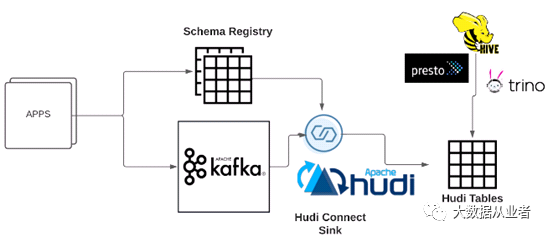
如图所示为hudi-sink-connector端到端部署案例。各种应用程序或者kafka source connector将数据写入到Kafka,可以选择将数据schema注册到Schema Registry。hudi-sink-connector消费Kafka数据写入到Hudi表中,可以选择从Schema Registry获取最新的schema信息。如果配置了Hive集成,hudi-sink-connector将会持续同步Hudi表metadata信息到Hive Metastore。Hudi表能够被多种查询引擎查询,如Presto、Trino等等。
https://github.com/apache/hudi/tree/master/hudi-kafka-connect复制
cd $KAFKA_HOME./bin/kafka-topics.sh --create --topic hudi-control-topic --partitions 1 --replication-factor 1 --bootstrap-server localhost:9092复制
cd $KAFKA_HOME./bin/connect-distributed.sh $HUDI_DIR/hudi-kafka-connect/demo/connect-distributed.properties复制
https://github.com/apache/hudi/blob/master/hudi-kafka-connect/demo/connect-distributed.properties复制

curl -X DELETE http://localhost:8083/connectors/hudi-sink(第一次启动的话,可以跳过)curl -X POST -H "Content-Type:application/json" -d @$HUDI_DIR/hudi-kafka-connect/demo/config-sink.json http://localhost:8083/connectors复制
当使用MOR表时,默认开启异步压缩,可以通过配置hoodie.kafka.compaction.async.enable修改;默认关闭异步clustering,可以通过配置hoodie.clustering.async.enabled修改。
大数据量场景,出于性能考虑,不建议hudi-sink-connector执行compaction和clustering,推荐使用单独的Flink/Spark/Hudi CLI作业执行compaction和clustering。
https://github.com/apache/hudi/tree/master/hudi-kafka-connect/demo复制
总结
实时数据入湖场景,除了利用计算引擎Flink/Spark以外,hudi-sink-connector提供一种可选项。hudi-sink-connector这种架构简单明了,易于维护。可以直接复用Kafka集群资源,不依赖第三方计算引擎,快速构建实时数据湖。用户可以根据实际场景需求,作出选择。


