




数据重复一直是数据工程的难题,影响存储成本、查询性能和数据完整性。本文介绍湖仓架构中数据重复是如何在数据摄入、存储合并和表管理等环节出现的,并探究像Hudi这类开放表格式所提供的原生去重策略。欢迎关注微信公众号:大数据从业者

以下是一些常见的场景:
- 流式摄入管道
:实时数据管道常常依赖像 Apache Kafka 这样的系统来进行事件流式传输。由于生产者重试、网络延迟或事件处理顺序错乱等原因,可能会出现重复事件。 - 批量数据处理
:定期加载数据的 ETL 作业可能会对相同的数据进行重复处理,特别是在摄入过程中出现故障时,这会导致重复记录被写入存储。此外,同一批次的源数据中也可能存在重复数据。 - 多源数据集成
:从多个上游系统集成数据时,如果这些系统包含冗余记录会产生重复数据。 - 并发写入
:在多个管道同时向同一存储系统写入数据时,可能缺乏并发控制导致重复数据出现。
注意:数据重复不只是一个技术问题,它会直接影响业务运营甚至不必要的成本支出。
数据去重
数据去重是指在任何存储系统中识别并消除重复数据副本的过程。它对于维护数据质量、提高存储效率、优化成本以及确保准确的分析至关重要。如果没有有效的去重策略,会面临以下挑战:
- 数据完整性问题
:重复记录可能会导致值冲突和分析结果不准确,从而影响决策。例如,财务交易表中的重复记录可能会导致同一笔付款被多次处理。 - 存储成本增加
:存储重复记录会使数据仓库和数据湖的存储量膨胀,从而增加成本。例如,大规模物联网应用重复的传感器日志可能会使存储需求增加两倍或三倍。 - 性能下降
:重复记录会增加需要处理的数据量,影响查询和分析的性能。例如,在将 “用户” 表与 “交易” 表进行连接时,如果任一表中存在重复记录,那么连接结果可能会为单个用户包含多次相同的交易,从而不必要地增加查询处理时间。 - 数据治理复杂度增加
:当存在重复数据时,要在存储系统中维护干净、一致的数据会变得更加困难,这会使合规工作和数据质量保障工作变得复杂。从用户角度看,大规模场景下这个问题极具挑战。
湖仓中的去重
湖仓架构基于数据湖存储(如 Amazon S3)上的文件格式(如 Apache Parquet),采用了开放表格式,如 Apache Hudi、Apache Iceberg 和 Delta Lake。首先,了解一下湖仓中常见的数据重复点,然后探究像Hudi这样的开放表格式是如何应对这些挑战的。
输入批次内
在任何摄入管道中,单个输入批次内的重复数据很常见。通常是由于源系统的数据重叠、临时性故障导致的摄入重试,或者缺乏主键或唯一标识符来区分记录所引起的。例如,移动应用摄入用户交互数据时,系统为应对网络故障而发起的重试可能会导致同一事件生成多条记录,影响存储效率,还会增加下游处理的计算负担。为了缓解这些挑战,在摄入阶段实施去重策略至关重要。
记录合并到存储时
即使在输入批次内进行了去重,在将这些记录合并到湖仓格式的过程中,重复问题仍然经常出现。在进行更新或删除操作时,开放表格式会将产生的更改与存储中的现有记录进行合并。由于数据湖中的文件格式本质上是不可变的,因此在合并这些更改时,通常会对文件进行重写(写时复制)。
运行表管理服务(如压缩)时
表管理服务(如压缩、聚类和分区优化)对于提高湖仓系统的查询性能和管理存储成本至关重要。然而,如果这些服务与摄入逻辑不一致,可能会无意中引入重复数据。
读时合并(MoR)表读取时
读时合并(MoR)表通常会将所有传入的更新存储到一个与基础数据文件分开的额外数据文件中。因此,它们需要额外的操作开销,以便在进行行级更新时合并这两个文件。
使用 Apache Hudi 进行去重
上节介绍了湖仓架构中可能出现数据重复的四个方面。接下来深入探讨Hudi是如何从根本上解决上述挑战及如何让用户能够灵活定制去重策略。
输入批次内
同一输入批次内的重复键是最常见的数据重复来源之一。Hudi有主键的概念,它是记录键和可选分区路径的组合。这个主键直接与文件 ID(uuid)相关联,该文件 ID 可以唯一标识 Hudi 中的文件组。由于批次中可能存在相同的主键,Hudi 会根据所选的合并模式,使用记录合并器来确保去重。
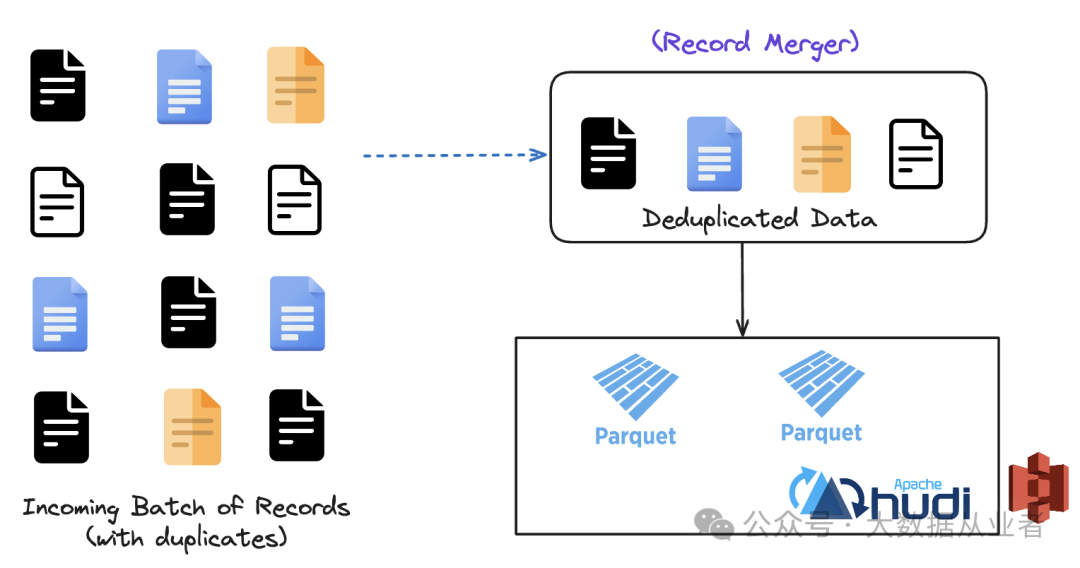
当同一批次中的两条或多条记录具有相同的主键时,记录合并器会决定如何合并这些记录。例如,EVENT_TIME_ORDERING 模式允许用户定义一个预合并字段(如时间戳或版本号),该字段用于确定在遇到重复记录时保留哪条记录。默认情况下,Hudi 会选择预合并字段值最大的记录。这确保了在数据摄入阶段只保留最相关版本的记录。Hudi 还允许将此实现扩展到特定的业务逻辑(即你希望如何进行去重)。这种原生功能在数据管道的第一阶段就减少了重复数据,确保只有唯一的、经过去重的记录进入数据湖。
记录合并到存储时
在将记录合并到存储时,Hudi采用先进的合并算法,即记录合并器,以确保数据一致性并消除重复数据。由于湖仓使用不可变的文件格式(如 Parquet)来存储记录,任何更新或删除操作都需要创建包含最新更改的文件新版本(写时复制)。
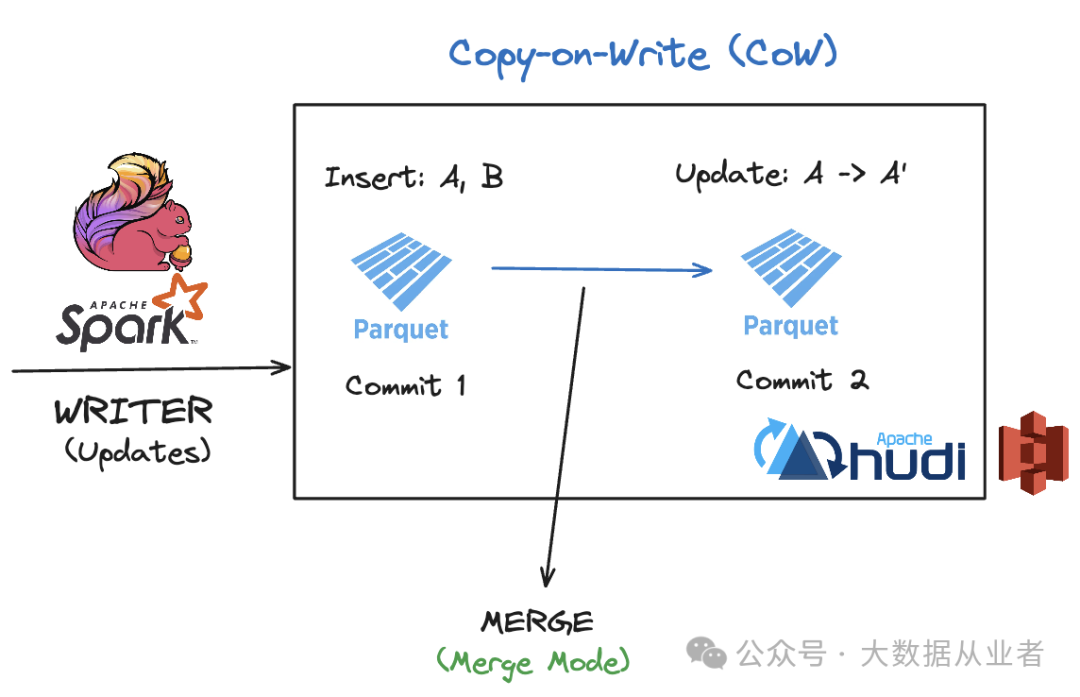
在进行更新、部分更新或删除操作时,Hudi 会将传入的更改与表中的现有记录进行合并。记录合并器决定了如何应用这些更新,确保在存储层保留记录的最新或最相关版本。Hudi 支持三种类型的合并模式:
- COMMIT_TIME_ORDERING
:根据提交顺序进行排序,确保最新提交的更改覆盖早期的更改。 - EVENT_TIME_ORDERING
:根据事件时间进行排序,确保最新的事件决定记录的最终状态。 - CUSTOM
:允许用户自定义合并逻辑。
这些合并模式确保 Hudi 能够处理复杂的场景,如延迟到达的数据、部分更新和重新处理,而不会引入重复数据。例如,在电子商务系统中更新产品价格时,即使更新顺序混乱,Hudi 也能确保只保留最新的价格。
运行表管理服务(如压缩)时
在读时合并(MoR)表中,表管理服务(如压缩)对于合并日志文件(增量更改)和基础文件(实际记录)至关重要。如果压缩逻辑与摄入逻辑不一致,重写的文件中可能会保留重复数据。Hudi 通过遵循摄入期间定义的合并模式,确保压缩过程与摄入逻辑一致,从而避免重写文件出现重复数据。
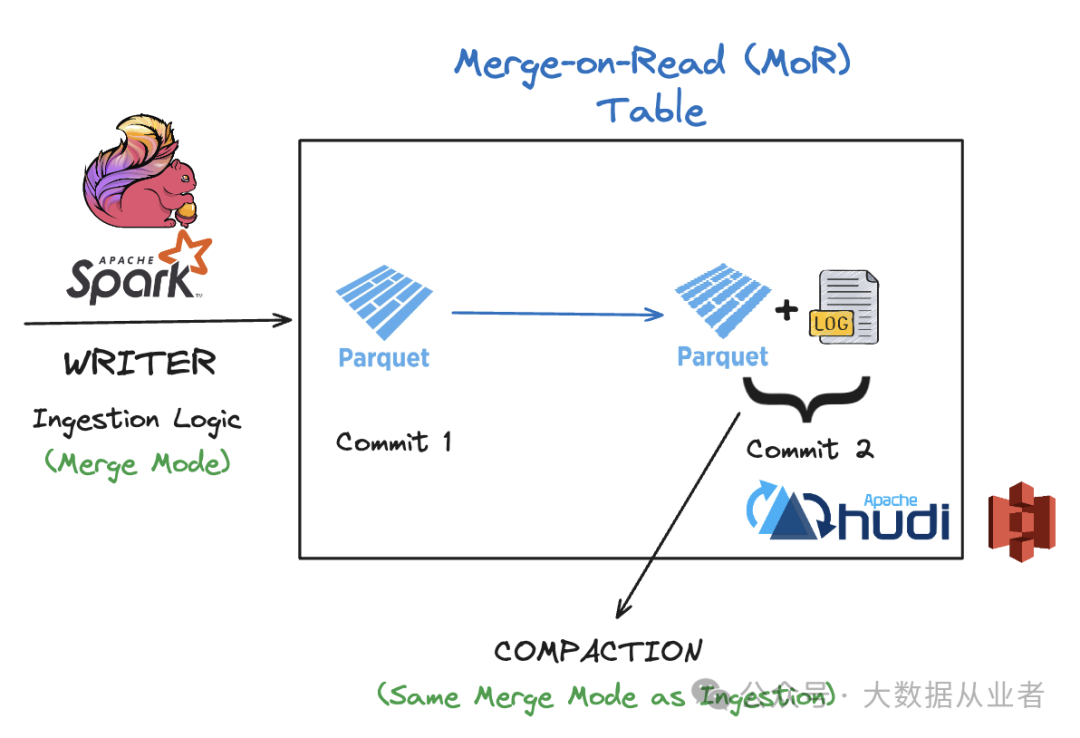
读时合并(MoR)表读取时
查询读时合并(MoR)表会带来额外的复杂性。当对 MoR 表执行快照查询时,Hudi 会在查询时合并日志文件和基础文件中的记录。合并过程同样由上述合并模式控制。
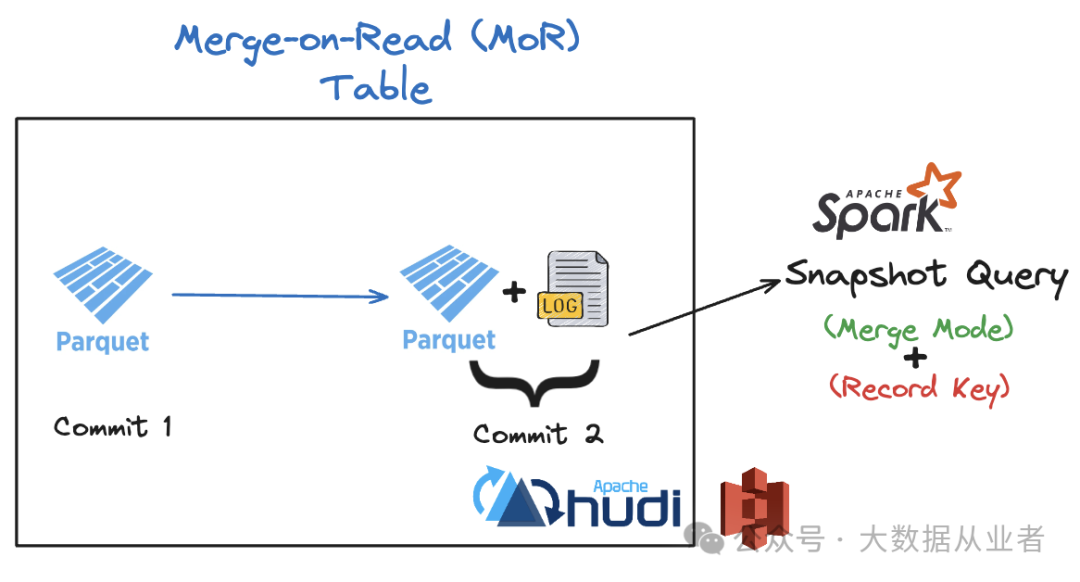
Hudi 中另一个在读取时去重方面起着核心作用的重要设计是记录键(主键)。它可以唯一标识记录,使Hudi能够准确汇总日志文件和基础文件。例如,如果存在多条记录,记录键会确保查询结果中只包含最新版本的记录(基于合并模式)。
示例用例
以广告数字营销为例,准确的点击数据对于评估广告活动的效果至关重要。广告商经常通过点击事件来跟踪用户与广告的交互情况,事件通常包括用户ID、广告ID、时间戳和点击ID等信息。
例如,用户可能会在短时间内多次点击广告,或者由于系统故障或重试机制,同一点击事件可能会被记录两次。代码示例如下,用户ID和广告ID共同构成一个记录键,最终数据集该键应该是唯一的。
# Simulate loading click data into a DataFrame , Note that couple of records exist for user_1 and ad_101click_data = [ ("user_1", "ad_101", "2025-02-01T10:00:00", "click_001", "device_001", "web", "campaign_1", "US", 1.5),("user_1", "ad_101", "2025-02-01T10:00:01", "click_001", "device_001", "web", "campaign_1", "US", 1.5),("user_2", "ad_102", "2025-02-01T10:05:00", "click_002", "device_002", "mobile", "campaign_2", "IN", 0.75),("user_3", "ad_103", "2025-02-01T10:10:00", "click_003", "device_003", "web", "campaign_3", "UK", 2.0) ]# Define schemacolumns = ["user_id", "ad_id", "timestamp", "click_id", "device_id", "platform", "campaign_id", "geo_location", "click_value"]# Create a DataFrame from the raw click dataclick_data_df = spark.createDataFrame(click_data, columns)hudi_options = {"hoodie.upsert.shuffle.parallelism": "2", # Number of partitions for parallelism during upsert"hoodie.insert.shuffle.parallelism": "2", # Number of partitions for inserts"hoodie.table.name": "clicks_table", # Table name for Hudi"hoodie.datasource.write.recordkey.field": "user_id,ad_id", # Composite primary key (RecordKey)"hoodie.datasource.write.precombine.field": "timestamp", # Field to deduplicate (PreCombineKey)"hoodie.record.merge.mode" : "EVENT_TIME_ORDERING"}click_data_df.write.format("hudi").options(**hudi_options).mode("append").save(hudi_table_path)spark.read.format("hudi").load(hudi_table_path).show()+-------------------+--------------------+--------------------+----------------------+--------------------+-------+------+-------------------+---------+----------+--------+-----------+------------+-----------+|_hoodie_commit_time|_hoodie_commit_seqno| _hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|user_id| ad_id| timestamp| click_id| device_id|platform|campaign_id|geo_location|click_value|+-------------------+--------------------+--------------------+----------------------+--------------------+-------+------+-------------------+---------+----------+--------+-----------+------------+-----------+| 20250202112241380|20250202112241380...|user_id:user_2,ad...| |a320f380-2864-408...| user_2|ad_102|2025-02-01T10:05:00|click_002|device_002| mobile| campaign_2| IN| 0.75|| 20250202112241380|20250202112241380...|user_id:user_1,ad...| |a320f380-2864-408...| user_1|ad_101|2025-02-01T10:00:01|click_001|device_001| web| campaign_1| US| 1.5|| 20250202112241380|20250202112241380...|user_id:user_3,ad...| |a320f380-2864-408...| user_3|ad_103|2025-02-01T10:10:00|click_003|device_003| web| campaign_3| UK| 2.0|+-------------------+--------------------+--------------------+----------------------+--------------------+-------+------+-------------------+---------+----------+--------+-----------+------------+-----------+复制
上述代码展示了在将数据写入 Hudi 表之前,如何在传入批次中进行去重。具体来说,如果用户 user_1 在 1 秒内为广告 ad_101 生成了多条点击记录,由于它们在同一批次中到达,这些记录将根据时间戳进行去重。
click_data = [("user_1", "ad_101", "2025-02-01T10:10:00", "click_001", "device_001", "web", "campaign_1", "US", 1.5),("user_2", "ad_102", "2025-02-01T10:00:00", "click_002", "device_002", "mobile", "campaign_2", "IN", 0.50)]click_data_df = spark.createDataFrame(click_data, columns)# Write the data to Hudi tableclick_data_df.write.format("hudi") \.options(**hudi_options) \.mode("append") \.save(hudi_table_path)# Read and show the data from Hudi tablespark.read.format("hudi").load(hudi_table_path).show()+-------------------+--------------------+--------------------+----------------------+--------------------+-------+------+-------------------+---------+----------+--------+-----------+------------+-----------+|_hoodie_commit_time|_hoodie_commit_seqno| _hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|user_id| ad_id| timestamp| click_id| device_id|platform|campaign_id|geo_location|click_value|+-------------------+--------------------+--------------------+----------------------+--------------------+-------+------+-------------------+---------+----------+--------+-----------+------------+-----------+| 20250202112241380|20250202112241380...|user_id:user_2,ad...| |a320f380-2864-408...| user_2|ad_102|2025-02-01T10:05:00|click_002|device_002| mobile| campaign_2| IN| 0.75|| 20250202112241380|20250202112241380...|user_id:user_1,ad...| |a320f380-2864-408...| user_1|ad_101|2025-02-01T10:00:01|click_001|device_001| web| campaign_1| US| 1.5|| 20250202112241380|20250202112241380...|user_id:user_3,ad...| |a320f380-2864-408...| user_3|ad_103|2025-02-01T10:10:00|click_003|device_003| web| campaign_3| UK| 2.0|+-------------------+--------------------+--------------------+----------------------+--------------------+-------+------+-------------------+---------+----------+--------+-----------+------------+-----------+复制
上述示例,第二批数据被摄入到Hudi,Hudi会根据记录键自动对记录进行去重。对于用户user_1和广告ad_101,有两条具有不同时间戳的记录到达。记录合并器使用 EVENT_TIME_ORDERING 策略,将时间戳作为预合并键。对于每个记录键,只保留基于事件时间的最新记录,从而有效地处理延迟到达的数据并保持一致性。
Apache Iceberg 和 Delta Lake 中的去重
Apache Iceberg 和 Delta Lake 的去重策略与 Hudi 有根本的不同。与 Hudi 提供具有记录合并器 API 等功能的内置机制以及感知摄入的表服务不同,Delta 和 Iceberg 依赖于显式的合并操作,并且要求用户在表格式之外处理去重。
Delta Lake 依赖于标准的 MERGE INTO 操作来将传入数据与现有数据集进行去重,但它不会自动对源数据集中的记录进行去重 —— 用户必须手动处理。例如:
MERGE INTO customer_transactions AS targetUSING newTransactions AS sourceON target.transaction_id = source.transaction_idWHEN NOT MATCHED THEN INSERT *复制
MERGE语句确保目标表中具有匹配交易 ID 的交易不会重复,但它不会对 newTransactions 数据集中的交易进行去重。如果 newTransactions 包含同一交易 ID 的重复交易记录,除非在 MERGE 操作之前进行显式处理,否则所有重复记录都会被插入到表中。这意味着用户必须在执行 MERGE 之前手动对 newTransactions 进行去重,因为 Delta Lake 没有提供消除源数据集中重复数据的内置逻辑。此外,与 Hudi 等格式不同,Delta Lake 没有可配置的逻辑来控制如何解决合并冲突,Hudi 提供了不同的合并模式来定义更新行为。复制
Apache Iceberg 在处理去重方面与 Delta Lake 采用类似的方法,依赖于 MERGE 语句来协调新数据与现有记录。在摄入时没有原生的去重机制,也没有可配置的合并逻辑,用户必须在将记录写入 Iceberg 表之前对其进行去重。
总结
去重对于湖仓架构至关重要,它可以确保数据一致性、降低存储成本并提高查询性能。Apache Hudi、Delta Lake 和 Apache Iceberg 在处理重复记录方面采用了不同的方法。
Delta Lake 和 Iceberg 依赖于显式的 MERGE 操作,要求用户在摄入之前从外部对数据进行去重。它们缺乏可配置的合并策略,并且一旦数据存入存储,就没有内置的去重机制。
Apache Hudi 提供内置的去重框架,能够在数据生命周期的多个阶段消除重复数据。在摄入和合并过程中,Hudi 提供了可配置的策略,允许用户控制如何处理更新和冲突。此外,Hudi 的表管理服务(如压缩)与摄入时的合并逻辑一致,确保在进行存储优化时不会重新引入重复数据。
