




前言
Flink反压已经是老生常谈的问题。那么如何确定反压的根源呢?在最近的Flink发布版本情况发生了很大的变化(特别是在Flink 1.13中增加了新的度量和web UI)。这篇文章将试图澄清其中的一些变化,并详细介绍如何追踪反压的根源。
什么是反压?
概括来说,反压就是Job Graph中的某些operator处理数据的速率低于接收数据的速率,造成数据积压,积压的数据填充到这些operator子任务的输入缓冲区。一旦输入缓冲区满了,反压就会传播到上游子任务的输出缓冲区。上游子任务也会被迫降低自身数据处理速度,以匹配下游opeartor的处理速度。由此类推,反压一步一步向上游传递,直至到达数据源operator端。
为什么需要关注反压?
反压是服务器或者operator过载的表现。因为数据在被处理之前已经在队列等待很长时间。所以,反压将直接影响系统的端到端延迟。另外,反压将导致对齐的检查点需要更长的时间,也将导致未对齐的检查点越来越大。如果你正在经历检查点障碍问题,关注反压将有助于解决问题。哪怕你只是想优化Flink作业,以降低运行成本,关注反压也很有必要。总之,为了解决的问题,你需要了解它,然后定位和分析它。
为什么不需要关注反压?
坦率地说,也不必太过于关注反压。从定义上来说,一直没有反压,说明集群资源利用率低。如果你想最大限度地减少闲置资源,允许一些反压现象的存在也是合理的,尤其对于批处理作业。
如何发现和追踪反压的根源?
利用metrics可以发现反压现象。不过,从Flink1.13版本开始,通过job graph可以直观的发现是否存在反压的现象,不需要点击进入task内部查看。

如上图示例,不同task有不同的颜色。通过颜色反映两方面信息:task反压程度、task忙碌程度。空闲task颜色为蓝色,全负荷忙碌task颜色为红色,反压全负荷task颜色直接置为黑色。通过这些颜色,可以很容易的发现反压task(黑)、busy task(红)。反压task下游的busy task很可能是反压的根源。
单独点击进入特定task的BackPressure页签,可以更直观的剖析反压问题,检查该task每个subtask的busy/backpressure/idle状态。比如,如果存在数据倾斜,每个subtask资源将不能得到同等的利用。
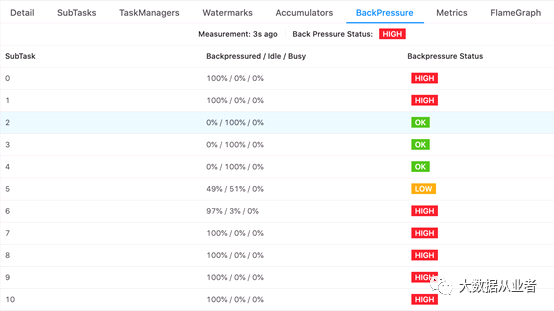
如上图示例,可以很清晰看出哪些subtask空闲、哪些subtask反压、没有subtask繁忙。坦率的说,以上足够定位反压问题了。不过,还有几个细节值得解释。BackPressured/Idle/Busy数据是基于三个新增metrics:
metrics(idleTimeMsPerSecond、
busyTimeMsPerSecond、
backPressuredTimeMsPerSecond)
由subtask计算和提供的。与CPU使用率指标非常相似,这三项数据用于测量每秒内有多少毫秒分别处于空闲、繁忙、反压。除了一些四舍五入误差外,三项数据是相互补充的,总和必须等于1000ms/s。另一个重要细节:三项数据是短时间内(几秒内)平均值,所反映的是subtask内部所有信息:
operators、functions、timers、checkpoint、序列化反序列化、网络堆栈、其他Flink内部开销。如果WindowOperator忙于启动定时器并生成结果,将会报告为busy或backpressure。如果Checkpointed接口类snapshotState方法存在复杂计算任务(如刷新内部缓冲区),也将会报告为busy。
值得一提的是,这里有一个限制:busyTimeMsPerSecond、idleTimeMsPerSecond对于subtask之外线程是不敏感的。存在如下两种场景:Operators内部自定义线程(该做法是官方不推荐的);使用已经不推荐的SourceFunction接口,该类source的busyTimeMsPerSecond数据将报告为NaN/N/A。
由于三项数据是几秒内测量的平均值。所以,在分析动态负载(varying load)类型的jobs或tasks(如subtask有定期触发的WindowOperator)时,一定要记住一点:恒定负载50%的subtask和每秒在fullBusy与fullIdle之间切换的subtask,busyTimeMsPerSecond数据均是500ms/s。
此外,动态负载(varying load)类型的jobs或tasks,尤其是触发窗口时,会将性能瓶颈移动到job graph的其他位置。
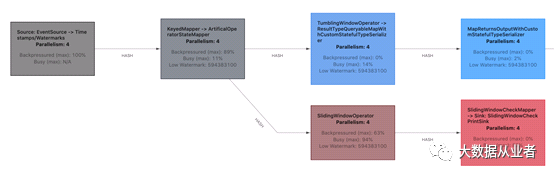

如上示例,SlidingWindowOperator因为积累数据成为性能瓶颈。但是,一旦触发窗口计算(10秒一次),下游task(SlidingWindowCheckMapper-> Sink: SlidingWindowCheckPrintSink)就会成为瓶颈,SlidingWindowOperator出现反压。由于三项数据平均时间超过几秒钟,这种微妙之处并不是立即可见的,需要仔细观察。更重要的是,webUI每10秒只更新一次状态,使得这种现象更不容易察觉。
怎么处理反压?
首先需要分析导致反压的原因:
确认反压真实存在。
找出具体的机器或者subtask、剖析代码确定具体位置、确定哪些资源是稀缺的。
在极少数情况下,网络交换可能是job的性能瓶颈,表现为下游task输入缓冲区为空、而上游的输出缓冲区为满。
简言之,有两种处理方法:
增加资源(更多机器、更快的CPU、更好的RAM、更好的网络、使用SSD等等)。
进行优化以充分利用现有资源(优化代码、调优参数、避免数据倾斜)。
