




MVCC 全称叫 多版本并发控制.啥意思呢? 简单地讲就是读写分离,因为读会阻塞写,如果读取数据很快到是无所谓,可现实中读取数据也要200毫秒,建行是这样的规范的.新公司RDS上最快是0.6毫秒!
哈哈 这是非常理想的状态,世界上互联网企业最大值是5秒,管理平台10秒,分析平台10分钟,或许1个小时以上,1天也行.
要是真的这样的话,一个查询跑1天,能阻塞多少生意? 老板会怎么看? 把这个SQL优化到200毫秒都有可能阻塞写, 尤其是读多写少的现实业务.我这公司读请求QPS为250,写请求TPS是50.
为什么读会阻塞写呢?因为有的人希望我读到的数据是最新的,有的人希望我读到的数据是那个时候的,有的人希望我正在修改的数据不要被人读到!
那就离婚哦! 反正合不来,矛盾那么多! 你这人咋那样呢! 劝合不劝离啊,人家小两口还是有感情的.要不再买套房子,两对门如何!
正点,用空间换时间,夫妻分离,哦! 不是 ,是读写分离.我们就同一栋楼,同一个实列里表空间分离,你住正常的数据库表空间, 我住UNDO表空间.
MYSQL 叫 UNDO LOG 不能翻译成UNDO 日志啊! 为啥.因为挂羊头卖狗肉,容易让人晕!
多版本搞定了.那怎么控制呢? 哪些SQL读正常数据库表空间呢? 哪些SQL要去读UNDO LOG 表空间呢?
正常数据库表空间
如:SELECT ... LOCK IN SHARE MODE(共享锁)
,SELECT ... FOR UPDATE、
UPDATE、INSERT、 DELETE(排他锁)
。
当然前面两个SQL一般都不会出现在业务SQL里面,如果出现了你赶紧拿出40米大刀砍过去! 这两个SQL主要是为了兼容标准SQL,同时可以作为DBA实验语句.平时业务是看不到它的身影,若见必然会是造成大量的业务并发等待.
UNDO LOG 表空间
不是上面的其它SQL,基本上都是SELECT
MYSQL 的 多版本控制没有ORACLE复杂, ORACLE主要依靠块的回滚来构造出过去的数据块.这叫一致性读.ORACLE没有MVCC说法.原理却是一样的.
ORACLE 依靠 SCN,块上的信息和UNDO.
同理MYSQL 也依旧如此,依靠的是XID,行上的信息,UNDOLOG READ VIEW
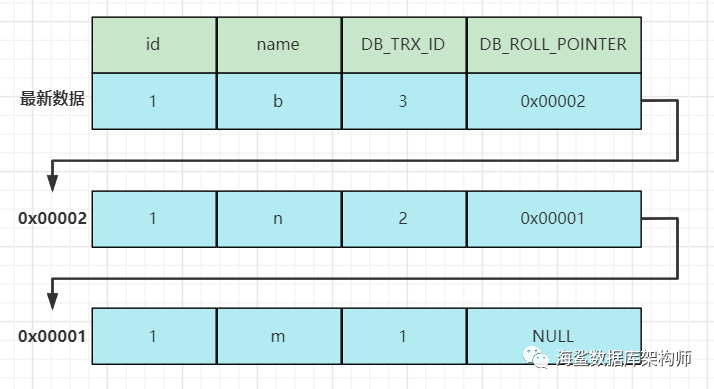
这张图就是行核心MVCC, 每行里面隐藏3个字段,如下表.上图没有隐藏的主键
因为实际上大部分表都有主键.
| 字段 | 含义 |
|---|---|
| DB_TRX_ID | 最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID。 |
| DB_ROLL_PTR | 回滚指针,指向这条记录的上一个版本,用于配合Undo Log,指向上一个版本。 |
| DB_ROW_ID | 隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段。 |
DB_TRX_ID: 这也是挂羊头卖狗肉的命名. 实际上它应该是ROW_TRX_ID,类似UPDATE_TIME意思. 这个事务ID不是以提交的事务, 是不确定状态的事务ID. 是对行下了手的事务ID 也就是XID.
DB_ROLL_PTR: 不用过多解释,类似于ORACLE的UNDO地址. 注意指针就是存放内存地址的变量, 也可以想象成写上内存地址的纸条.
有了行的两个字段结构,我们编程写个简单的算法 就能找到我们所需要的数据.当然我这里不会写,大家想一下,这程序不难!
READVIEW
不是读视图, 不要被MYSQL挂羊头卖狗肉的命名搞晕. 是这样的我们拿到行里的DB_TRX_ID,这个事务ID对应的事务是什么状态,是已提交的, 正在运行的,刚刚新来的,还是我自己的? 目前无法从行里的其它数据来判断.
那怎么搞? 自然我们还需要一批数据来判断, 什么数据呢? 自然是当前事务ID的数据.
把当前所有活跃事务ID,拿过来,放进一个数组里, 那就叫 ACTIVE_XID_ARRAY[250]
MYSQL 这里叫M_IDS. 不过实际运行过程中活跃事务数组太多了,绝对超过250.那就搞动态数组,不设置上限量.
不过百万QPS,万级TPS, 这数组也太长了吧! 每行数据里的DB_TRX_ID(ROW_XID) 都要遍历下百万级的数组. 想必也非常耗时.不花算! 我们拿出里面最大XID和最小XID就行了
当然还有我们自己本家事务的ID.
如下表所示.
| 字段 | 含义 |
|---|---|
| m_ids | 当前活跃的事务ID集合 |
| min_trx_id | 最小活跃事务ID |
| max_trx_id | 预分配事务ID,当前最大事务ID+1(因为事务ID是自增的) |
| creator_trx_id | ReadView创建者的事务ID |
接下来就是简单的 IF 判断了
1 如果 行里面的XID 是我本家事务的, 那就选择这行数据了
if ( DB_TRX_ID == creator_trx_id){return this->rows;}复制
2 如果 行里面的XID 小于 最小的事务ID, 说明行里的事务已经提交了
if ( DB_TRX_ID < min_trx_id){return this->rows;}复制
3 如果 行里面的XID 大于等于,最大事务ID,这里的最大要+1,表示将来的事务
if ( DB_TRX_ID >= max_trx_id){通过 DB_ROLL_PTR 指针去寻找;}
4 如果 行里面的XID 介于最小和最大事务ID中间呢? 同样就行从UNDO 找
if ( DB_TRX_ID < max_trx_id) && ( DB_TRX_ID >=min_trx_id){通过 DB_ROLL_PTR 指针去寻找;}复制
隔离级别 RR && RC
RC隔离级别 读提交级别, 基本上每个语句重新构造自己的READVIEW.也就是获得当前语句开始运行时候的活跃事务数组.
那怕你开启了事务语句,把10个语句包裹在一起,它们也是各自构造自己的活跃事务数组. 事务只是完成一致性撤销而已,要么提交,要么滚回去. 就没有其他啥了
RR级别,叫可重复读. 其实命名也难以理解. 难道行可以读很多次,本来行就可以读很多次的嘛! 为啥呢,多此一举呢.
应该叫 读开始 ! 读取事务开始时候的数据. 事务开始的时候就构造出活跃事务数组. 事务后面的SELECT 都以这个事务数组为标准,大家使用同一个事务数组.
这样我们事务里面所有的SELECT语句读取的数据是一样的,那怕在其中有其他事务提交了数据,我们都视而不见!
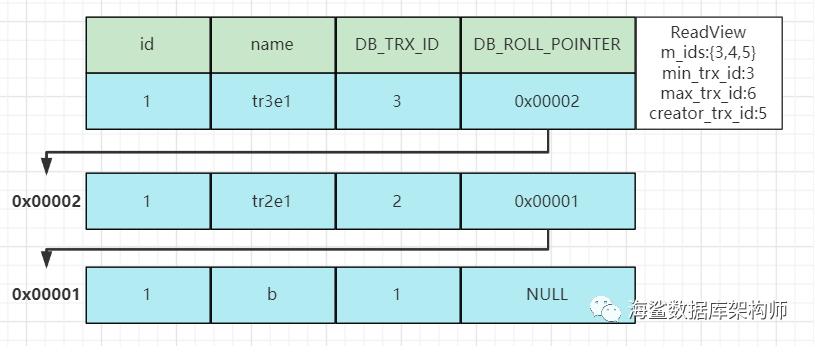
比如上图 本家事务是5,第一行数据是事务3,处于活跃数组里{3,4,5} 不符合
第三行 事务2的, 小于最小事务3 符合.
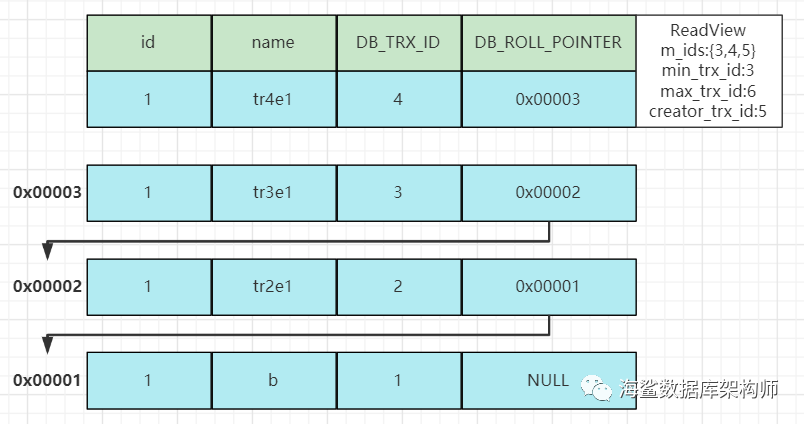
比如上图 本家事务是5,第一行数据是事务4,处于活跃数组里{3,4,5} 不符合
第二行 事务3的,等于最小事务3 不符合
第三行 事务2的, 小于最小事务3 符合.
大家觉得MYSQL MVCC && READ VIEW 有没有问题?
性能的问题? 把你的答案写在评论区里, 周末我也会把自己的看法写在评论区!
觉得好请点广告支持下



