




Graph_Convolutional_Neural_Network_for_Intelligent_Fault_Diagnosis_of_Machines_via_Knowledge_Graph.pdf
免费下载

7862 IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS, VOL. 20, NO. 5, MAY 2024
Graph Convolutional Neural Network for
Intelligent Fault Diagnosis of Machines
via Knowledge Graph
Zehui Mao , Senior Member, IEEE, Huan Wang , Bin Jiang , Fellow, IEEE, Juan Xu , Member, IEEE,
and Huifeng Guo
Abstract—Considering the challenge of deep mining of
root causes in machine failures, a knowledge aggrega-
tion fault diagnosis (KAFD) model is proposed, in which
the graph convolutional network (GCN) GraphSAGE is im-
proved and introduced into the knowledge graph (KG)-
based fault diagnosis. Historical maintenance data of ma-
chines is used to construct a fault phenomenon-FBG,
which is then combined with the fault diagnosis knowledge
graph (FDKG) to form a collaborative FDKG. A single-layer
knowledge aggregation network (KAN) that incorporates
sensitivity factors and configures different types of GCN
aggregators is constructed in the proposed KAFD. Based
on deep neighbor aggregation operations on collaborative
FDKG, KAFD obtained by stacking multiple KANs, can cap-
ture the higher order structural information and semantic
information, which results in the multihop reasoning, im-
provement of the rationality and diversity of fault cause
tracing. The KAFD is experimentally validated through two
fault diagnosis datasets, which are constructed by the
maintenance data of an industrial enterprise, and the re-
sults demonstrate the excellent performance.
Index Terms—Fault diagnosis, graph neural networks,
industrial machines, knowledge graph (KG).
I. INTRODUCTION
I
NDUSTRIAL machines have been becoming more complex
and expensive with the high performance, as the advanced
intelligent devices and monitoring technologies are introduced
Manuscript received 23 October 2023; revised 10 December 2023;
accepted 6 February 2024. Date of publication 29 February 2024; date
of current version 6 May 2024. This work was supported in part by the
National Key Research and Development Program of China under Grant
2021YFB3301300 and in part by ZTE Industry-University-Institute Co-
operation Funds. Paper no. TII-23-3628. (Corresponding author: Juan
Xu.)
Zehui Mao, Huan Wang, and Bin Jiang are with the College of
Automation Engineering, Nanjing University of Aeronautics and As-
tronautics, Nanjing 210016, China (e-mail: zehuimao@nuaa.edu.cn;
wanghuan233@nuaa.edu.cn; binjiang@nuaa.edu.cn).
Juan Xu is with the College of Computer Science and Technology,
Nanjing University of Aeronautics and Astronautics, Nanjing 210016,
China (e-mail: juanxu@nuaa.edu.cn).
Huifeng Guo is with the State Key Laboratory of Mobile Network and
Mobile Multimedia Technology, Shenzhen 518000, China, and also with
the ZTE Corporation, Shenzhen 518000, China (e-mail: guo.huifeng2
@zte.com.cn).
Color versions of one or more figures in this article are available at
https://doi.org/10.1109/TII.2024.3367010.
Digital Object Identifier 10.1109/TII.2024.3367010
into them. However, this leads to an increasing requirement on
reliability and safety of industrial machines subjected to faults
and failures [1]. Fault diagnosis that detects the occurrence of a
fault as early as possible and identifies the location and type of
the fault as accurately as possible, is a key mean to ensure the
safety of industrial machines [2], [3].
With the development of technology, the fault diagnosis
methods are receiving more and more attention, including the
model-based methods [4], [5], data driven-based methods [6],
[7], [8], [9], and knowledge-based methods [10]. As a significant
amount of maintenance records can be accumulated during the
long-term maintenance and repair processes of industrial ma-
chines, which contain the valuable knowledge and information
related to machine fault diagnosis.
Knowledge-based fault diagnosis methods commonly include
expert systems, fault tree analysis, and knowledge graphs (KGs).
By automating the acquisition, organization, and analysis of
various machine information, including maintenance history and
expert experience, KG-based fault diagnosis methods can iden-
tify fault root causes and provide solutions. Existing research
mainly utilizes KG reasoning techniques [11], [12], [13], which
can make inferences about potential causes or solutions based
on entities and relations. During the machine operating, the
new data and information reflecting new faults often emerge
often generates. Incorporating new data and information into
existing KGs and reasoning requires offline updates, difficult to
be updated and improved dynamically.
Recommendation systems, by continuously collecting feed-
back from maintenance personnel during the maintenance pro-
cess, can achieve dynamic updates and continuously improve
the accuracy of fault cause recommendations, addressing the
issue of dynamic updates in KG-based fault diagnosis. Fusing
the KGs and recommendation algorithms can address the issue
of dynamic updates in KG-based fault diagnosis, which can be
primarily achieved through the propagation-based methods [14],
[15]. Propagation-based methods can expand the depth of infor-
mation reception by following the deep aggregation, thereby
fully utilizing the information in the KG to better predict fault
causes and locate potential fault causes. Deep aggregation is
the core of graph convolutional neural networks (GCN) [16],in
which GraphSAGE [17] is a representative model. But GCNs
like GraphSAGE is not feasible for weighted graphs, as they
can only perform equally weighted aggregations of neighboring
1551-3203 © 2024 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.
See https://www.ieee.org/publications/rights/index.html for more information.
Authorized licensed use limited to: ZTE CORPORATION. Downloaded on November 26,2024 at 06:05:55 UTC from IEEE Xplore. Restrictions apply.
MAO et al.: GRAPH CONVOLUTIONAL NEURAL NETWORK FOR INTELLIGENT FAULT DIAGNOSIS OF MACHINES VIA KNOWLEDGE GRAPH 7863
nodes. In addition, GraphSAGE imposes limitations on the
number of sampled neighbors, leading to the loss of important
local information for some nodes and making it unsuitable
for representation learning tasks in KGs and requiring further
improvements.
This article aims to address the challenges of difficult fault
knowledge mining and low real-time performance by combining
KGs with recommendation systems. To tackle these challenges,
a novel knowledge aggregation fault diagnosis (KAFD) model
is proposed. The main contributions of this article are as follows.
1) As KGs and recommendation algorithms are combined
and introduced into the industrial machine fault diagnosis,
a new knowledge aggregation network (KAN) is de-
signed, which incorporates sensitivity factor to make the
GCN suitable for the structure of fault diagnosis knowl-
edge graph (FDKG). This design allows for weighted
operations on different nodes of the FDKG, considering
the importance of different neighboring entities.
2) The deep aggregation idea is applied, and the KAFD
model is constructed. By stacking KAN, KAFD expands
the depth of information reception, facilitating multihop
reasoning in the KG and further exploration of potential
fault causes.
The rest of this article are organized as follows. Section II
describes the fault diagnosis problem based on KGs. Section III
introduces the structure of the KAFD model. Section IV presents
and analyzes the performance of the KAFD model. Finally,
Section V concludes this article.
II. P
ROBLEM FORMULATION
This section analyzes the task of KG-based fault diagnosis
for industrial machines, and provides a formulation to describe
the fault diagnosis problem achieved by recommending the fault
root cause from the fault phenomenon.
A. Fault Phenomenon-Fault Root Cause Bipartite Graph
(FBG)
For fault diagnosis, recommendation system determines the
root cause of the fault from the fault phenomenon. In the
recommendation system, associations between fault phenom-
ena and causes are represented as an FBG defined as U =
{y
fs
|f ∈F,s∈S}, where F is the set of fault phenomena,
S is the set of fault root causes, and y
fs
correlation between
fault root causes and fault phenomena as
y
fs
=
1,fand s have connection in history
0, otherwise.
. (1)
Due to the sparsity problem of the practical fault data from
the industrial machines, numerous node in the generated fault
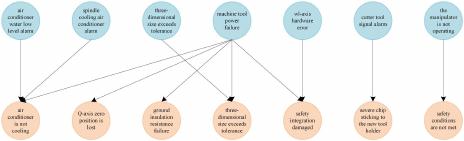
bipartite graph only have a few correlative connections, as shown
in Fig. 1, where blue circles are the fault phenomenon and red
circle are the fault root causes. The sparse correlative connec-
tions cause some information missed in the recommendation
system, and the associations between fault phenomena and fault
root causes cannot be accurately expressed, which effect the
Fig. 1. Example of an FBG sparsity problem.
accuracy of fault diagnosis. However, the FDKG, established us-
ing the triples obtained by the knowledge extraction technology,
contains the substantial knowledge about faults. An extra KG can
help supplement the information and improve the representation
of the associations in FBG [18].
B. Fault Diagnosis Knowledge Graph
The method of taking FDKGs as auxiliary information of the
recommendation system contributes to enrich the representation
of fault phenomena and root causes, relieves the sparsity problem
of fault data, and enhances the accuracy and interpretability of
the model.
Similar to the generic KG, FDKG consists of a large number of
triples (h, r, t) as the basic units, denoted as G = {(h, r, t)|h, t ∈
E,r ∈R}, where E is the set of all entities, and R represents
the set of all relations. In the KG, facts are expressed as triples
(head entity, relation, tail entity), which are interconnected to
express real-world knowledge and facilitate computer under-
standing. In the FDKG, facts are expressed as triples (head
entity, relation, tail entity), which interconnect each other to
express knowledge for computer understanding. In this study, the
FDKG is constructed by unstructured data of industrial machines
accumulated during the production process.
C. Collaborative Knowledge Graph (CKG)
As the FDKG and the FBG are established using the different
and independent information of fault data, a CKG which can
associates these two graphs into a unified relational network to
unify the two parts of information, is necessary. The associations
between the fault phenomenon and the fault root cause are
expressed in the form of triples (phenomenon, connect, cause)
in the CKG, where y
fs
= 1 denotes as an additional relation
connect between f and s. Define the alignment set as A, which
denotes that the root cause s of the fault in the FBG can be
aligned to the entity e in the FDKG. Based on the alignment
set A, the FBG and the FDKG are combined into a unified
CKG G
= {(h, r, t)|h, t ∈E
,r ∈R
}, where E
= E∪Fand
R
= R∪{connect}.
D. High-Order Relation
In a unified CKG, high-order relations between fault phe-
nomena and root causes could be established by bridging two
entities that not directly connected. Define the L-order connec-
tion between nodes as a high-order relation path e
0
r
1
−→ e
1
r
2
−→
···
r
L
−→ e
L
, where r
l
∈E
, r
l
∈R
, l ∈ L. More correlation
information between entities could be obtained. As illustrated
Authorized licensed use limited to: ZTE CORPORATION. Downloaded on November 26,2024 at 06:05:55 UTC from IEEE Xplore. Restrictions apply.

7864 IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS, VOL. 20, NO. 5, MAY 2024
Fig. 2. Example of CKG.
in Fig. 2, the path f
1
− s−
1
− e
1
− e
3
− e
2
− s
2
reveals the
potential connection between f
1
and s
2
, which is difficult to
reflect in a single FBG. The high-order relation from one entity to
another entity requires the connection of multiple relationships,
which is the so-called multihop.
E. Fault Diagnosis Task
For the fault diagnosis model that recommends root causes
by the fault phenomena, the input is the historical records of the
FBG and the FDKG generated by fault records, while the output
is a sequence of fault root causes corresponding to the observed
fault phenomena.
Given the FBG U and the FDKG G of industrial machine fault,
the probability ˆy
fs
of predicting the candidate fault root cause s
that is the potential cause of the observed fault phenomenon f,
can be expressed as
ˆy
fs
= Func(f,s|Θ, U, G) (2)
where Θ is the parameters of the prediction function. Then, the
fault root causes is sorted according to the prediction probability.
Based on the predicted probabilities, the fault root causes are
ranked, which serves as the result of fault diagnosis to enhance
the efficiency of troubleshooting for operational personnel.
III. M
ETHOD
In order to improve the accuracy of fault diagnosis, we will
propose a new KG-based fault diagnosis model named KAFD,
to obtain the high-order relations between fault phenomena and
fault root causes, in which the KAN incorporated. Through
the KAN, multihop connections of fault phenomena and root
causes are revealed, which makes the KAFD can learn the fault
diagnosis knowledge from the CKG, to obtain the reason from
observed phenomena to potential root causes.
A. Overall Framework
The KAFD model, shown in Fig. 3, includes multiple KANs
and a prediction module. The KAN module primarily serves
to aggregate t he neighboring entities and enable to the update
of central entity features. Through stacking of h layers KAN,
KAFD can aggregate information from multiple-hop entity,
resulting in more comprehensive fault root cause features. The
prediction module is responsible for calculating the probability
of each pair of fault phenomena f and fault root causes s. KAFD
ultimately outputs the top-k fault root causes with the highest
probabilities as the fault diagnosis results.
B. Knowledge Aggregation Network
KAN is a revised version of GCN GraphSAGE to meet
the needs of KG-based fault diagnosis tasks. There are three
improvements, including the following.
1) Design sensitivity factors to address the issue that differ-
ent fault root causes have diverse importance for the fault
phenomena, achieving weighted aggregation of different
neighbor entities.
2) Propose sampling strategy with controllable depth and
quantity for the scale differences of FDKGs in different
diagnosis tasks, so as to adjust the size of receptive field
flexibly for exploring potential fault root causes.
3) Exploit three aggregation functions for various fault di-
agnosis tasks, satisfying the features of different FDKGs.
The structure of KAN is illustrated in Fig. 4.
The specific measures for the three improvements are shown
as follows.
1) Sensitivity Factors: Considering the varying sensitivity of
fault phenomena to different fault r oot causes, certain fault root
causes are more prone to trigger the fault phenomena, exerting
greater influence on the fault phenomena features. In order to
prioritize the influence of fault root causes on fault phenomena
features, sensitivity factors are designed to enable weighted
aggregation of neighboring entities.
For each pair of fault phenomena f and fault root cause s,the
set of neighboring entities adjacent to the fault root cause entity is
defined as N (s), and r
a,b
denotes the relation between entities a
and b. If a fault phenomenon f has been triggered by the s pecific
fault root cause s in fault records, the entities associated with this
fault root cause are searched in the FDKG, and neighbor entity
aggregation is performed. During the aggregation process, the
sensitivity factors are calculated using the inner product function
g to bias the aggregation
ζ
f
r
= g(f , r) (3)
where f ∈ R
d
and r ∈ R
d
are the representations of the fault
phenomenon f and the relation r, respectively, and d is the
dimension of the representations. The parameter ζ
f
r
indicates
the importance level of the relation r to the fault phenomenon
f. It can be employed to depict the propensity of a specific fault
phenomenon being triggered by different types of causes.
To describe the topological neighborhood structure of fault
root cause s in FDKG, it is necessary to compute the linear
combination of sensitivity factors for its neighborhood
s
f
N(s)
=
e∈N(s)
ζ
f
r
s,e
e (4)
where e is the representation of neighboring entities of the
root cause entity in the FDKG, and
ζ
f
r
s,e
is the normalized
representation of ζ
f
r
ζ
f
r
s,e
=
exp
ζ
f
r
s,e
e∈N(s)
exp
ζ
f
r
s,e
. (5)
Through the application of sensitivity factors, the neighborhood
representation s
f
N(s)
of the root cause can be obtained, which
Authorized licensed use limited to: ZTE CORPORATION. Downloaded on November 26,2024 at 06:05:55 UTC from IEEE Xplore. Restrictions apply.
of 9
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
待就业 闲聊
最新上传
HIndex-FLSM_Fragmented_Log-Structured_Merge_Trees_Integrated_with_Heat_and_IndexHIndex-FLSM:分段日志结构合并.pdf
2024-11-27
A刊-Fluid-Shuttle_Efficient_Cloud_Data_Transmission_Based_on_Serverless_Computing_CompressionFluid-Shuttle.pdf
2024-11-27
C刊-Research_on_Quantum_SSL_Based_on_National_Cryptography.pdf
2024-11-27
下载排行榜
1
2
9-数据库人的进阶之路:从PG分区、SQL优化到拥抱AI未来(罗敏).pptx
3
1-PG版本兼容性案例(彭冲).pptx
4
2-TDSQL PG在复杂查询场景中的挑战与实践-opensource.pdf
5
6-PostgreSQL 哈希索引原理浅析(文一).pdf
6
8-基于PG向量和RAG技术的开源知识库问答系统MaxKB.pptx
7
3-AI时代的变革者-面向机器的接口语言(MOQL)_吕海波.pptx
8
4-IvorySQL V4:双解析器架构下的兼容性创新实践.pptx
9
7-拉起PG好伙伴DifySupaOdoo.pdf
10
《云原生安全攻防启示录》李帅臻.pdf

文档被以下合辑收录
相关文档
评论