




Acceleration-Guided Diffusion Model for Multivariate Time Series Imputation.pdf
100墨值下载

Acceleration-Guided Diffusion Model for
Multivariate Time Series Imputation
Xinyu Yang
1
, Yu Sun
1
, Shaoxu Song
2
, Xiaojie Yuan
1
, and Xinyang Chen
3
sxsong@tsinghua.edu.cn
3
School of Computer Science and Technology, Harbin Institute of Technology,
Shenzhen, China
chenxinyang@hit.edu.cn
Abstract. Multivariate time series data are pervasive in various do-
mains, often plagued by missing values due to diverse reasons. Diffusion
models have demonstrated their prowess for imputing missing values
in time series by leveraging stochastic processes. Nonetheless, a persis-
tent challenge surfaces when diffusion models encounter the task of ac-
curately modeling time series data with quick changes. In response to
this challenge, we present the Acceleration-guided Diffusion model for
Multivariate time series Imputation (ADMI). Time-series representa-
tion learning is first effectively conducted through an acceleration-guided
masked modeling framework. Subsequently, representations with a spe-
cial care of quick changes are incorporated as guiding elements in the
diffusion model, utilizing the cross-attention mechanism. Thus our model
can self-adaptively adjust the weights associated with the representation
during the denoising process. Our experiments, conducted on real-world
datasets featuring genuine missing values, conclusively demonstrate the
superior performance of our ADMI model. It excels in both imputation
accuracy and the overall enhancement of downstream applications.
Keywords: Multivariate time series · Data imputation · Self-supervised
learning · Diffusion model.
1 Introduction
Incomplete time series data are common in various fields such as meteorology
[13], traffic [6], and medical treatment [24], impairing the performance of down-
stream analysis [11]. Researchers have developed various methods for imputing
missing values in multivariate time series, based on statistics [23], machine learn-
ing [6, 15], deep learning [22, 14], etc. Because of the powerful data generation
ability, generative models [17, 28] are widely used in imputing missing values.
As one of the most advanced generative models, the diffusion model has
demonstrated impressive results in imputing time series data [28, 1, 14], tak-
ing advantages of the multi-step noise-adding and denoising processes to model
© The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd. 2025
M. Onizuka et al. (Eds.): DASFAA 2024, LNCS 14851, pp. 130, 2025.
https://doi.org/10.1007/978-981-97-5779-4_8
115–
1
College of Computer Science, DISSec, Nankai University, Tianjin, China
2
Tsinghua University, Beijing, China
yangxinyu@dbis.nankai.edu.cn, {sunyu,yuanxj}@nankai.edu.cn
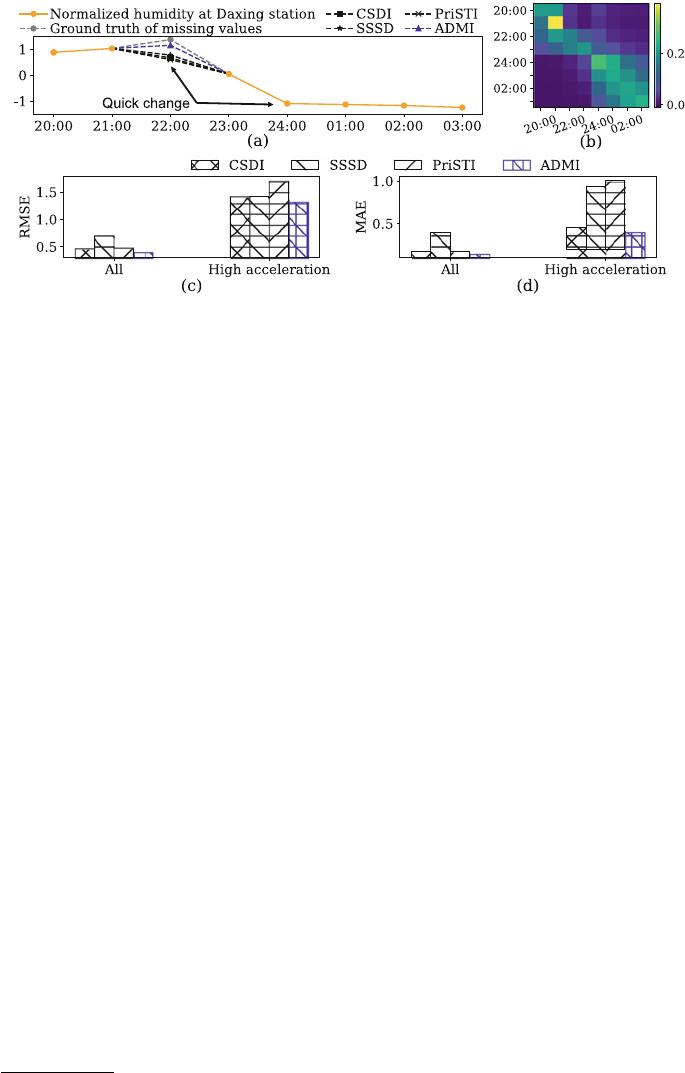
Fig. 1. The imputation performance results over Beijing18 [13] with 10% missing values
of exiting diffusion-based method [28] and our ADMI over Beijing18 [13]. (a) For the
example segment on 2017/09/21-2017/09/22; (b) Temporal attention weights of CSDI
[28]; (c)(d) For all missing values and those with high acceleration (>1).
data distributions. However, as illustrated in Figure 1(a), diffusion-based meth-
ods, e.g., CSDI [28], SSSD [1] and PriSTI [14], face the challenge of imputing
missing values with quick changes, which are prevalent in time series data and
important to a broad range of real-world problems [2]. Moreover, Figure 1(b)
reflects the strength of each timestamp in focusing on other timestamps in the
self-attention mechanism when modeling the time series, with lighter colors rep-
resenting stronger attention. We can find that modeling each timestamp will
affect that for neighboring timestamps as well. Therefore, inaccurate modeling
data with quick changes can impact the global modeling of data changes, leading
to decreased overall imputation performance. The primary reason for aforesaid
two challenges stems from the innate nature of deep neural networks, which tend
to inherently smooth their outputs without specific guidance [21, 27].
Researchers usually utilize the acceleration [25] to describe how fast the time
series data change, by measuring the difference on value changes between neigh-
boring timestamps.
4
In Figures 1(c)(d), we observe that it is more difficult for
existing diffusion-based models [28, 1, 14] to impute missing values with high
acceleration, compared with the whole missing values. Such results show that
constructing a more accurate modeling of high acceleration data is crucial for
improving the imputation accuracy of diffusion models.
Enlightened by this, we present the Acceleration-guided Diffusion model for
MultivariatetimeseriesImputation (ADMI). Our model exploits guidance rep-
resentations that are obtained through an acceleration-guided mask modeling
framework, to guide the diffusion model for imputation. Specifically, we first
introduce a masking mechanism that prioritizes observations with higher accel-
erations to be masked, allowing the guidance representations to extract more
4
Please see the formal definition in Equation 1 in Section 3.1.
116 X. Yan
g
et al.
of 16
100墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论