





问题:主要是 分布式的物理备份 , 我又不能手动来恢复。
思路: 1.要先创建一个实例 ,然后将备份移动到该实例的路径下,然后进行的恢复
1.在赤兔上创建新的实例
2.在hdfs 上根据实例信息 创建相关目录 group_1610847854_45 ,set_1610848126_1 如
hadoop fs -mkdir -p /tdsqlbackup/tdsqlzk/group_1610847854_45/autocoldbackup/s
hadoop fs -mkdir -p /tdsqlbackup/tdsqlzk/group_1610847854_45/autocoldbackup/s
hadoop fs -mkdir -p /tdsqlbackup/tdsqlzk/group_1610847854_45/autocoldbackup/s
hadoop fs -mkdir -p /tdsqlbackup/tdsqlzk/group_1610847854_45/autocoldbackup/s
3.将备份文件,和日志文件拷贝到相应目录 (注意 cp 的时候需要把分片数加上)
cp 物理文件 和 binlog
hadoop fs -cp -d /tdsqlbackup/tdsqlzk/group_1610846781_37/autocoldbackup/set
hadoop fs -cp -d /tdsqlbackup/tdsqlzk/group_1610846781_37/autocoldbackup/set
hadoop fs -cp -d /tdsqlbackup/tdsqlzk/group_1610846781_37/autocoldbackup/set
4.在赤兔上进行恢复 ,注意回档时间如果选择当前的话, 要有相应的binlog
测试好像至少需要在一个binlog的时间点后在, 不然会报 can not get route in th
我的猜想:1.这个时间是必须要一个binlog
2.这个时间点需要新创建的实例后面, 而恢复的时候直接恢复到没有binlog 为
新实例创建结束时间: 在 日志管理 -> 控制台操作日志 的 创建分布式
#原理
1.在还原的时候,点击下一步时,需要去flush log 日志,所需需要一个可用的实例。
2.在恢复的时候是去扫描是否有可用的备份文件,跟文件名无关, 不会去匹配文件名
所以只需要把 备份文件 cp 到 目录就可以了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
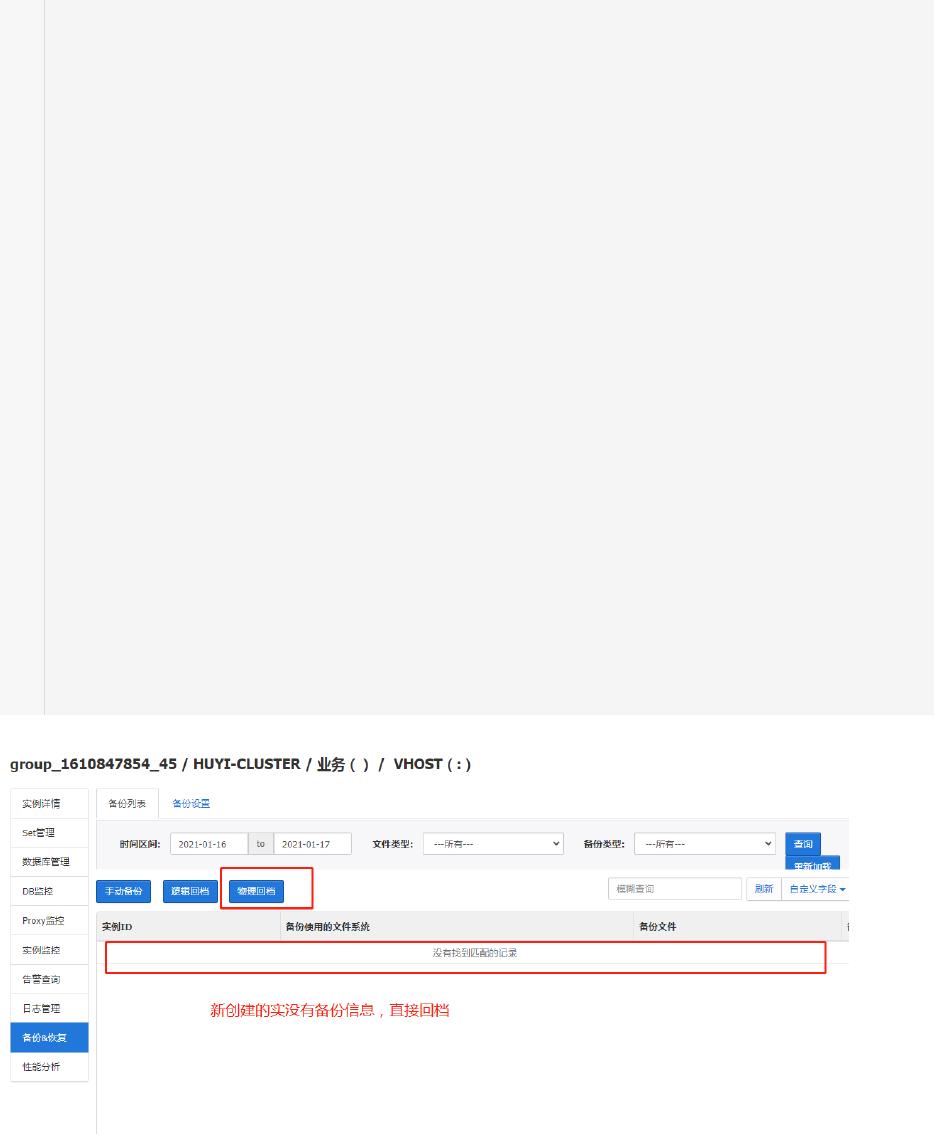
3.在恢复的时候 指定时间点 没有恢复成后, 有待继续 测试
使用当前的时间点(默认的当前的), 恢复成功
4.没有binlog 也是恢复不成功的。
恢复:明确要去找binlog
ERROR 57093,backupfilemgn.cpp:228:pickValidBinlog,tid:0x7f6f16d5e880,serv
ERROR 57093,binlogmgn.cpp:67:getAvailableBinlog,tid:0x7f6f16d5e880,unable
ERROR 57093,recoverset.cpp:161:recover,tid:0x7f6f16d5e880,Binlog Recover
#注意有时候 赤兔上反回
提示: 【-2007】the zookeeper operation timeout
可以等待,后台执行完成在看。 因为任务已经下出下去了。
#总结:
1.恢复的时候选 使用当前的时间点(默认的当前的)
2.恢复的时候至少需要一个binlog 文件。
没有binlog ,备份片的数据也会还原,只是状态不可用, 可以尝试手动调整。
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
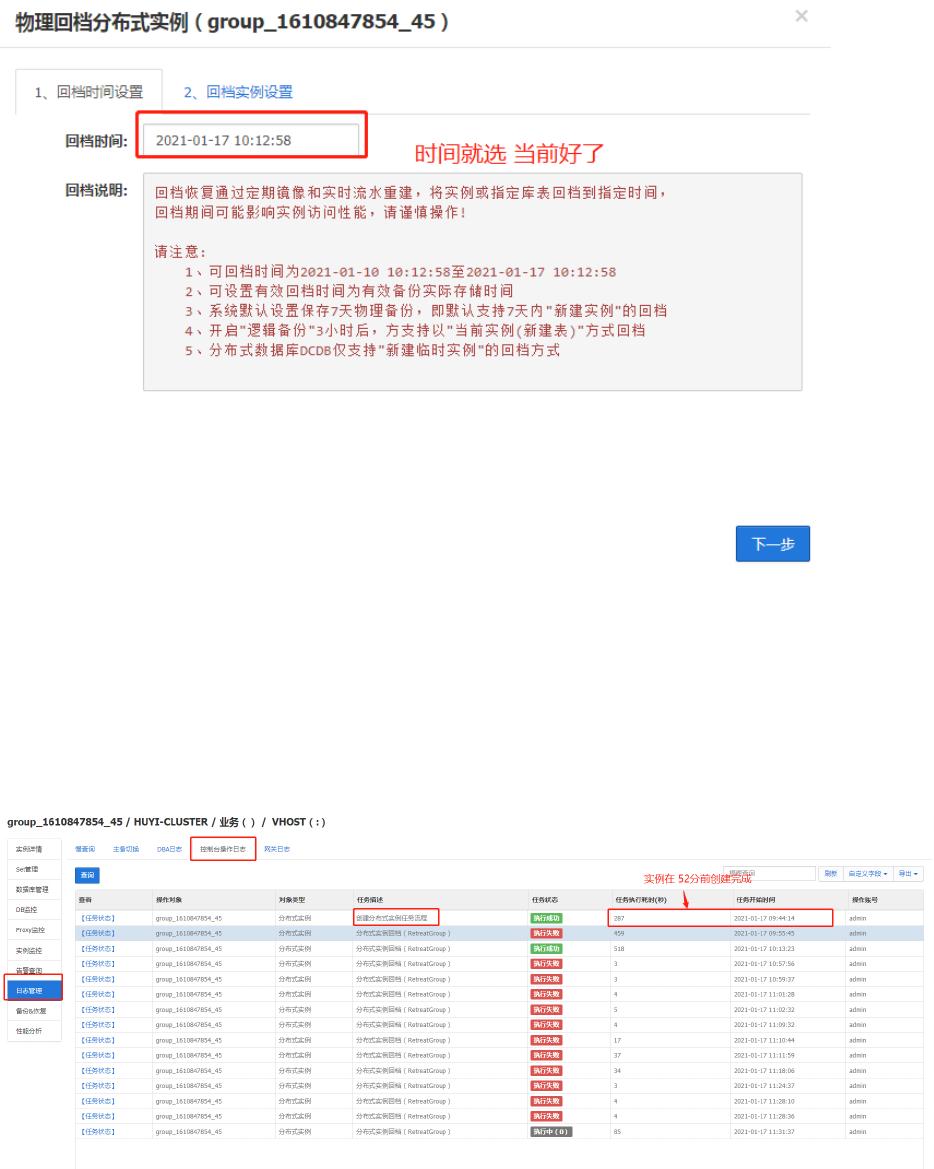
测试1: 回当时间必须设置到, 新实例创建后的时间点
#1. 查看新实例创建完成时间:
#2.回当时间设置在 52分:回档成功
of 6
10墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜
1
2
9-数据库人的进阶之路:从PG分区、SQL优化到拥抱AI未来(罗敏).pptx
3
1-PG版本兼容性案例(彭冲).pptx
4
2-TDSQL PG在复杂查询场景中的挑战与实践-opensource.pdf
5
6-PostgreSQL 哈希索引原理浅析(文一).pdf
6
8-基于PG向量和RAG技术的开源知识库问答系统MaxKB.pptx
7
3-AI时代的变革者-面向机器的接口语言(MOQL)_吕海波.pptx
8
4-IvorySQL V4:双解析器架构下的兼容性创新实践.pptx
9
7-拉起PG好伙伴DifySupaOdoo.pdf
10
《云原生安全攻防启示录》李帅臻.pdf

文档被以下合辑收录
相关文档
评论