




前言
聚类是一种存储优化方法,适用于诸如 Apache Hudi、Apache Iceberg 和 Delta Lake 等开源表格式,核心目标是解决数据摄入顺序(如数据到达时间)与查询访问(如事件时间)之间的不一致问题。通过基于频繁查询的字段来组织数据,实现存储优化,使查询引擎能够更有针对性地访问数据。欢迎关注微信公众号:大数据从业者
聚类算法类型
线性排序
线性排序是最简单的聚类技术,它根据特定列(如本例中的员工姓名)对数据进行排序。其目标是提高数据的局部性,确保具有相似值的记录被分组到同一个文件中。这使得查询引擎更容易定位和访问相关数据,通过减少扫描的数据量显著提高性能。
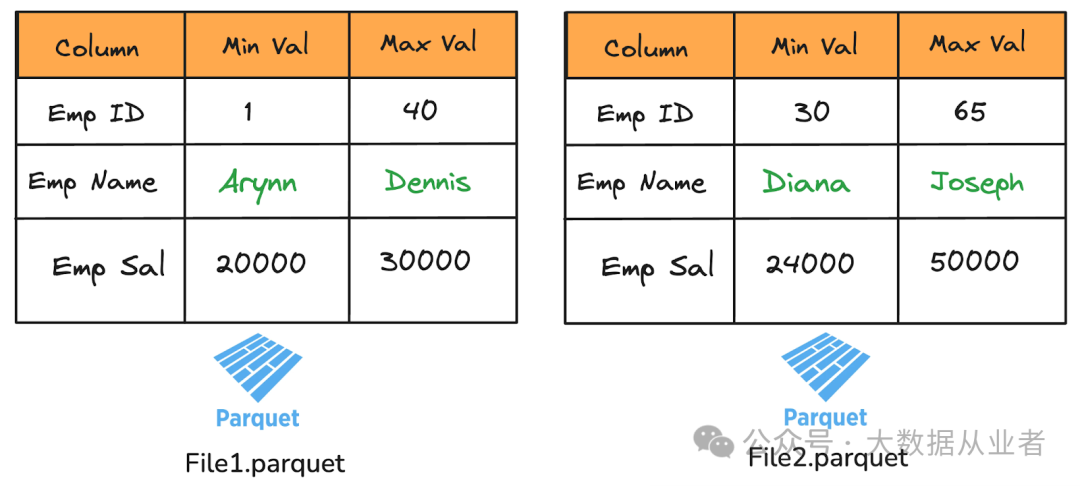
假设我们有按员工姓名字段排序的员工数据,如图所示。这些数据被分割成两个文件:
文件 1 的姓名范围是从Arynn到Dennis,员工 ID 范围是从 1 到 40,薪资在 20,000 到 30,000 之间。 文件 2 的姓名范围是从Diana到Joseph,员工 ID 从 30 到 65,薪资从 24,000 到 50,000。
由于按员工姓名排序,所以每个文件包含唯一的姓名范围,那么任何针对特定姓名的查询只需扫描包含该范围的文件。考虑以下查询:
SELECT * FROM Employee WHERE Emp Name = 'David'
由于 David在文件1这个范围内,查询引擎只需扫描文件 1 来定位数据。文件 2则完全被跳过。
通过使用排序来组织数据,数据文件的布局与查询模式更加匹配,使引擎只需访问一半的文件。这种有选择性的文件读取方式最大限度地减少了 I/O 操作并降低了延迟,这对于具有多个分区的大型数据集尤为有益。
现在,假设查询依据员工薪资和员工 ID 进行过滤。在这种情况下,仅按员工姓名这一列进行线性排序将无法筛选出所有不相关的记录。为了解决这个问题,我们可以使用分层排序,即数据按特定顺序进行排序 —— 首先按员工姓名,然后按员工薪资,最后按员工 ID。例如,如果我们有一个带有如下谓词的查询:
SELECT * FROM Employee WHERE Emp Name='David' AND Emp Sal=25000 AND Emp ID=22
在这种情况下,查询引擎会考虑每个谓词,并比较员工姓名、员工薪资和员工 ID 的最小 - 最大范围,以更精确地筛选文件。然而,分层排序只有在查询包含对第一个排序列(在本例中为员工姓名)的过滤时才有效,如果谓词仅涉及员工薪资或员工 ID 或两者的组合,它的效果就不佳。例如,如果一个查询仅根据员工薪资进行过滤,如:
SELECT * FROM Employee WHERE Emp Sal > 19000
由于主要按员工姓名排序可能会使员工薪资的范围分散在所有文件中,引擎可能仍需要扫描所有文件。因此,虽然分层排序在一定程度上有助于处理多列查询,但其有效性在很大程度上取决于排序列的顺序和查询模式。
总体而言,线性排序对于具有单个谓词的查询(如仅按员工姓名过滤)效果显著,但难以有效处理涉及多个谓词的查询。
多维聚类
多维聚类是一种高级聚类技术,它超越了简单的排序,能够同时基于多个列来组织数据。这种方法对于基于多个字段进行过滤的复杂查询特别有价值,因为它能在多个维度上保持数据的局部性。通过以这种方式对数据进行聚类,查询引擎可以跳过更多文件,减少 I/O 操作,从而显著提高性能。
假如员工信息的数据集,其中包括员工薪资(Emp Sal)和工作年限(YOE)等属性。以下表格展示了部分记录:
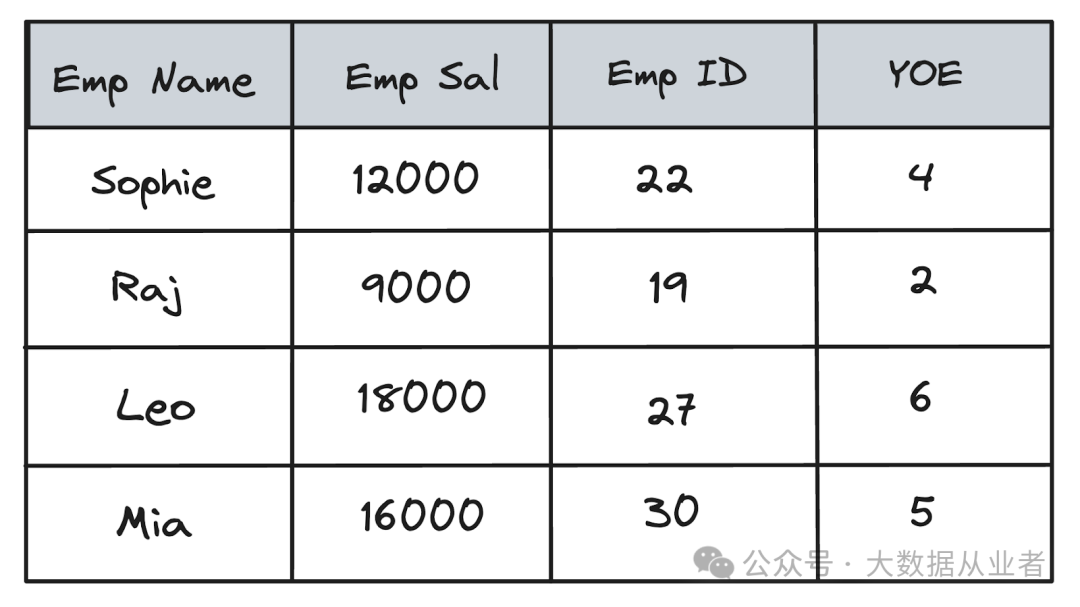
在这个数据集中,像Leo和Mia这样的员工在员工薪资和工作年限这两个属性上具有相似的值。如果我们在一个二维空间中可视化这些数据,将员工薪资放在一个轴上,工作年限放在另一个轴上,我们可以看到利奥和米娅在这个二维空间中彼此更接近,这反映了他们相似的薪资和工作经验水平。
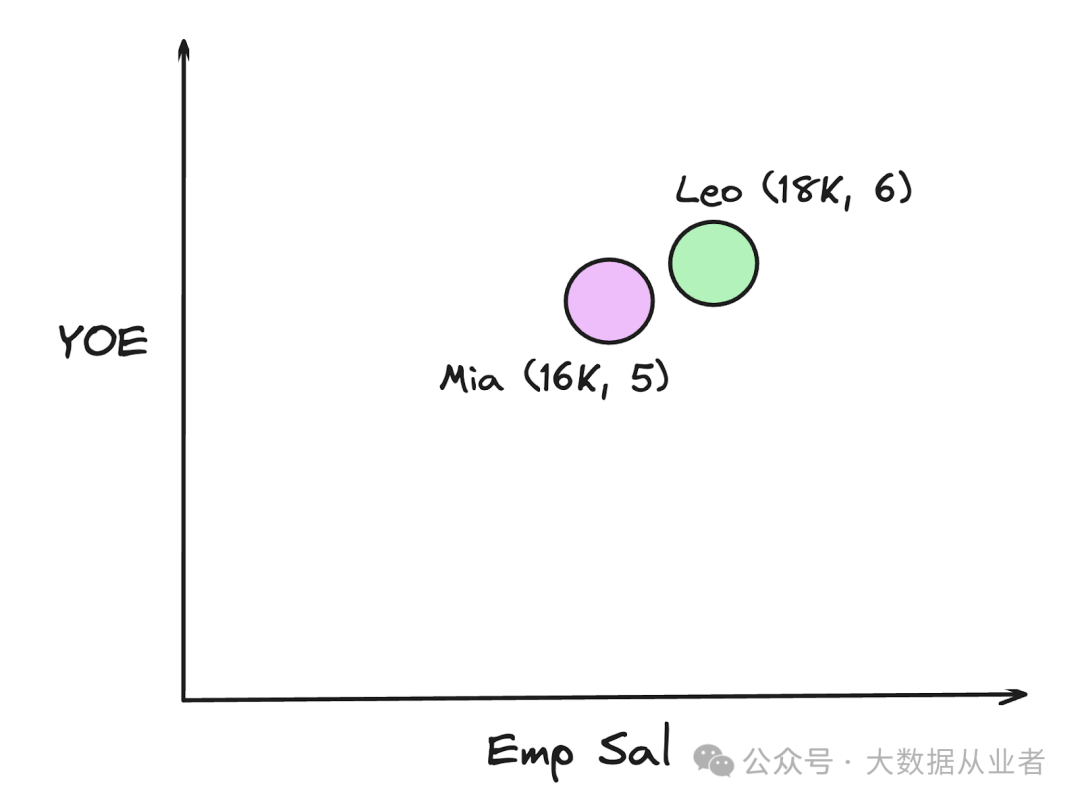
图 2:两名(属性相当相似的)员工在二维空间中的投影
现在,同时根据薪资和工作经验进行过滤的查询:
SELECT * FROM Employee WHERE Emp Sal > 10000 AND YOE > 4
理想情况下,我们希望这两个属性值相似的记录存储在同一个文件中。然而,如果数据没有在多个维度上进行聚类,这些记录可能会分散在多个文件中,查询引擎将不得不再次扫描所有文件来获取它们,这会增加 I/O 操作并降低性能。使用简单排序算法(在上一节中讨论过)无法实现基于多个维度的信息对数据进行排序。多维聚类专门解决了这个问题。
Z-order聚类
Z-order聚类是一种流行的多维聚类技术,它解决了在从高维到低维映射时将相关数据点聚集在一起的挑战。Z-order曲线是一种空间填充曲线,用于将多维(如员工薪资和工作年限)的数据点映射到一维文件结构中,同时保留空间局部性。
将Z-order聚类应用到上述示例中,我们可以组织文件,使其同时利用员工薪资和工作年限这两列进行聚类。当查询引擎处理示例(查找薪资超过 10,000 且工作经验超过 4 年的员工)时,可以快速在单个文件(例如,在这种情况下为 File 1.parquet)中定位数据,如下图所示。
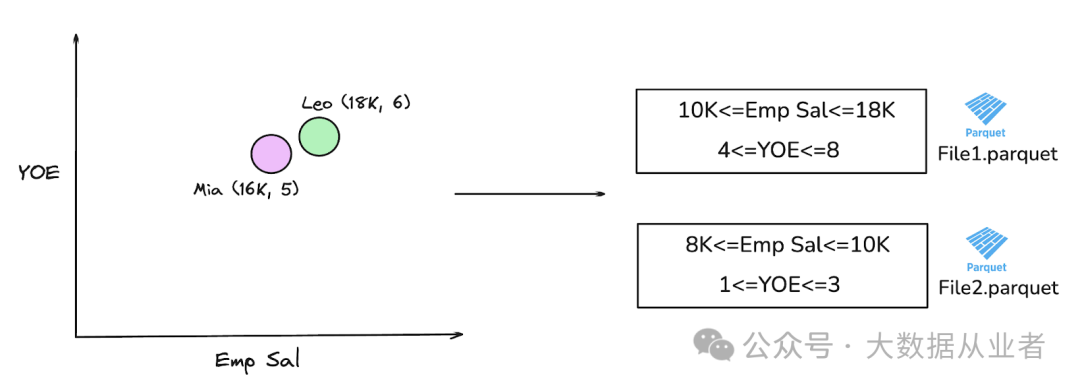
图 3:Z-order聚类为两名员工保留了(一维)局部性
希尔伯特曲线
另一种有效的多维聚类技术是希尔伯特曲线。与 Z-order曲线一样,希尔伯特曲线也是一种空间填充曲线,它将 N 维空间中的数据点映射到一维直线上,同时保留数据的局部性。
当数据访问模式复杂且涉及多个维度时,希尔伯特曲线特别有优势,因为与 Z-order曲线相比,它在高维聚类中能提供更好的空间局部性保留。例如,涉及时间、深度和位置等属性的科学数据,从希尔伯特曲线提供的局部性保留中受益匪浅,因为它允许高效访问在多维空间中接近的数据点。
假设员工数据集有额外的属性,如部门或位置。随着维度的增加,希尔伯特曲线在聚类在所有属性上都相似的数据点方面会更有效,确保在员工薪资、工作年限、部门和位置等属性上值相近的记录存储在一起。这可以最大限度地减少 I/O 操作并加速查询性能。
需要注意的是,虽然希尔伯特曲线在更高维度上提供了更好的局部性保留,使其非常适合具有跨多个属性的复杂访问模式的数据集,但它们的计算成本也更高。在应用此类聚类算法时,必须权衡计算开销、查询模式以及要优化的特定维度等因素。因此,在应用这些聚类算法时需要进行充分考虑。
现在我们对不同的聚类算法有了较为全面的了解,接下来看看这些算法如何应用于开源湖仓格式。
Apache Hudi 中的聚类
虽然三种最流行的开源表格式都提供了聚类功能,但 Apache Hudi 通过不同的策略、部署模式以及使用各种开源计算引擎运行服务的灵活性来实现聚类能力。最重要的是,Hudi 的聚类选项旨在平衡数据摄入性能与优化的数据布局。这些优化可以异步执行,而不会中断正在进行的数据摄入过程,允许用户根据特定的工作负载配置聚类,而无需专门安排维护窗口。
Hudi 支持前面讨论的所有三种存储布局优化策略:线性排序、Z-order排序和希尔伯特曲线。每种策略定义了在聚类过程中如何重新组织记录,以提供量身定制的优化,满足不同的工作负载需求。默认方法是线性排序。
Hudi 的聚类服务
Hudi 的聚类通过表服务进行管理,涉及两个主要阶段:调度和执行。这种两步方法使 Hudi 能够在保持查询性能的同时确保数据一致性。以下是每个阶段的详细分解:
- 调度聚类
:在此阶段,Hudi 创建一个聚类计划,以指定哪些文件将被重新组织。 - 识别符合条件的文件
:根据所选策略,识别文件,例如小文件或碎片化文件。 - 分组文件
:将文件分组以达到目标文件大小,同时可以选择限制组大小以提高并行性。 - 保存计划
:聚类计划以 Avro 格式保存到时间线中,准备执行。 - 执行聚类
:此阶段处理聚类计划,将定义好的策略应用于每个文件组。 - 检索聚类组
:计划指定要重新组织的特定组。 - 应用策略
:Hudi 应用执行策略(例如,排序列),并将数据重写到新文件中。 - 提交更改
:一个 “REPLACE” 提交记录新的布局,并相应地更新元数据。
要点总结:Hudi 支持所有三种聚类算法 —— 线性排序、Z-order排序和希尔伯特曲线。它支持内联和异步两种聚类模式,提供了在聚类和数据摄入工作负载之间进行平衡的灵活性。这些模式由 Spark DataSource Writer、Flink 和 Hudi Streamer 支持。
Apache Iceberg 中的聚类
Apache Iceberg 的聚类是通过 rewrite_data_files
Spark 过程实现的,该过程通常将碎片化或较小的文件合并为优化的组。Iceberg 中的聚类不是一个专门的服务,因此这种方法需要用户手动触发聚类,以确保在需要时应用优化。由于 Iceberg 中的聚类是一个手动且被动的过程,因此没有内置机制通过异步方法来平衡数据摄入性能与优化的数据布局。因此,聚类操作通常在计划的维护窗口期间进行,具体取决于工作负载需求和优化优先级。
Iceberg 支持线性排序和 Z-order聚类,线性排序按单列按字典顺序组织数据,对于简单的单谓词查询非常有效。另一方面,Z-order聚类使用空间填充曲线在多个维度上优化数据,提高了多谓词查询(如地理空间或时间序列工作负载)的空间局部性。这些策略使 Iceberg 能够通过最小化文件扫描来提高查询性能,特别是在对排序列进行过滤时。
要点总结:Apache Iceberg 的聚类技术(线性排序和 Z-order排序)允许用户在计划的维护窗口期间优化数据布局,不过它本身并未与数据摄入过程集成以实现无缝的异步优化。
Delta Lake 中的聚类
Delta Lake 通过线性排序、Z-order排序支持聚类,并且在 Delta Lake 3.1.0 版本中引入了希尔伯特曲线聚类。Delta Lake 中的 Z-order聚类需要用户手动管理聚类列配置。
通过使用希尔伯特曲线聚类,它比 Z-order排序保留了更好的空间局部性,从而加快了多维过滤查询的速度。此外,将聚类信息存储在事务日志中,消除了用户在每次聚类操作时都要记住并指定这些信息的需求,从而减少了用户错误操作的概率、简化了流程。
要点总结:Delta Lake 支持线性和多维聚类,允许对数据文件进行增量聚类,而无需重写已经聚类的数据。不过,它确实需要用户通过 OPTIMIZE
命令手动触发优化。

结论
聚类是数据湖仓架构中的一项关键优化技术,它解决了数据布局与查询访问模式对齐的挑战。通过线性排序和多维聚类等策略,可以少不必要的文件扫描来显著提高查询性能。
Apache Hudi 的聚类功能为数据重组提供了灵活的选项,使用户能够根据性能需求在内联和异步聚类之间进行选择。通过平衡数据摄入和聚类操作,Hudi 帮助用户保持优化的存储,并提供快速、高效的查询,这在大规模数据湖仓环境中至关重要。
