




1.分类:分类就是根据以往的数据和结果对另一部分数据进行结果的预测。模型的学习在被告知每个训练样本属于哪个类的“指导”下进行新数据使用训练数据集中得到的规则进行分类
分类的基本过程:
学习阶段:建立一个分类模型,描述预定数据类或概念集。评估模型的预测准确率,如果准确率可以接受,那么使用该模型来分类标签为未知的样本。
分类阶段:即使用分类模型,对将来的或未知的对象进行分类。
数据集:训练集、测试集、预测数据集
2.分类与预测:
不同点:分类是预测类对象的分类标号(或离散值),根据训练数据集和类标号属性,构建模型来分类现有数据,并用来分类新数据。预测是建立连续函数值模型评估无标号样本类,或评估给定样本可能具有的属性值或值区间,即用来估计连续值或量化属性值,比如预测空缺值。
相同点:分类和预测的共同点是两者都需要构建模型,都用模型来估计未知值。预测中主要的估计方法是回归分析

3.过拟合:通常,模型为了较好拟合训练数据会变得比较复杂,模型复杂的表现就是参数过多。虽然模型在训练数据上有较好的效果,但是对未知的测试数据可能结果会不好,这种现象叫做过拟合。
过拟合的原因
(1)样本里的噪声数据干扰过大,达到模型过分记住了噪声特征,反而忽略了真实的输入输出间的关系;
(2)样本抽取错误,包括(但不限于)样本数量太少,抽样方法错误,抽样是没有足够正确考虑业务场景或业务特点等,导致抽出的样本数据不能有效足够代表业务逻辑或业务场景;
(3)建模时使用了样本中太多无关的输入变量。
4.决策树:决策树算法的基础是二叉树,但不是所有的决策树都是二叉树,还有可能是多叉树
决策树算法过程:
(1)构造决策树:决策树构造过程:
①输入数据,主要包括训练集的特征和类标号。
②选取一个属性作为根节点的分裂属性进行分裂。
③对于分裂的每个分支,如果已经属于同一类就不再分了,如果不是同一类,依次选取不同的特征作为分裂属性进行分裂,同时删除已经选过的分列属性。
④不断的重复③,直到到达叶子节点,也就是决策树的最后一层,这时这个节点下的数据都是一类了。
⑤最后得到每个叶子节点对应的类标签以及到达这个叶子节点的路径。
(2)决策树的预测
得到由训练数据构造的决策树以后就可以进行预测了,当待预测的数据输入决策树的时候,根据分裂属性以及分裂规则进行分裂,最后即可确定所属的类别
5.属性分裂的三种情况:
设 A 是分裂属性,根据训练数据, A 具有 n 个不同值{ a1 ,a2 ,…,an },选取 A 作为分裂属性进行分裂时有如下三种情况。
① A 是离散值:对 A 的每个值 a j 创建一个分支,分区 Dj 是 D 中 A 上取值为 aj 的类标号元组的子集
② A 是连续的:产生两个分支,分别对应于A≤split_point 和 A>split_point ,其中 split_point 是分裂点,数据集 D 被划分为两个分区, D 1 包含 D 中 A≤split_point 的类标号组成的子集,而 D 2 包括其他元组。
③ A 是离散值且必须产生二叉树(由属性选择度量或所使用的算法指出):结点的判定条件为“ A∈S A ?”,其中 S A 是 A 的分裂子集。根据 A 的值产生两个分支,左分支标记为 yes ,使得 D 1 对应于 D 中满足判定条件的类标记元组的子集;右分支标记为 no ,使得 D 2 对应于 D 中不满足判定条件的类标记元组的子集。
6. ID3算法:在分裂节点处将信息增益作为分裂准则进行特征选择,递归的构建决策树。
ID3算法的步骤:
①输入数据,主要包括训练集的特征和类标号。
②如果 所有实例都属于一个类别,则决策树是一个单结点树,否则执行③。
③计算训练数据中每个特征的信息增益。
④从根节点开始选择最大信息增益的特征进行分裂。依次类推,从上向下构建决策树,每次选择具有最大信息增益的特征进行分裂,选过的特征后面就不能继续进行选择使用了。
⑤不断的构建决策树,至没有特征可以选择或者分裂后的所有元组属于同一类别时候停止构建。
⑥决策树构建完成,进行预测
ID3算法倾向于选择数值较多的特征,对于每个属性均为离散值属性,如果是连续值属性需先离散化
7. C4.5算法:
C4.5算法在构建决策树的时候,分类属性选择的是具有最大信息增益率的特征,这样通过分裂属性的信息,一定程度上避免了由于特征值太分散而造成的误差,C4.5算法过程:
①如果所有实例都属于一个类别,则决策树是一个单结点树,否则执行步骤②。
②从根节点开始选择最大信息增益率的特征进行分裂。
③依次类推,从上向下构建决策树,每次选择具有最大信息增益率的特征进行分裂,选过的特征后面就不能继续进行选择使用了。
④重复步骤③,直至没有特征可以选择或者分裂后的所有元组属于同一类别时候停止构建。
⑤决策树构建完成,进行预测
C4.5连续值处理:根据连续属性值进行排序,用不同的值对数据集进行动态划分,把数据集分为两部分,一部分大于某值,一部分小于某值,然后根据划分进行信息增益计算,最大的那个值作为最后的划分。假设属性 A 是连续值,必须确定 A 的“最佳”分裂点,其中分裂点是 A 上的阈值。将 A 的值按递增序排序,每对相邻值的中点被看做可能的分裂点。当 A 具有 n 个值时,需要计算 n-1 个可能的划分。对于 A 的每个可能分裂点,计算信息增益,具有信息增益最大的点选做 A 的分裂点 split_point ,产生两个分支,分别对应于 A≤split_point 和 A>split_point ,数据集 D 被划分为两个分区, D 1 包含 D 中 A≤split_point 的类标号组成的子集,而 D 2 包括 A>split_point 元组
.过拟合的原因:样本问题
(1)样本里的噪声数据干扰过大,达到模型过分记住了噪声特征,反而忽略了真实的输入输出间的关系;
(2)样本抽取错误,包括(但不限于)样本数量太少,抽样方法错误,抽样是没有足够正确考虑业务场景或业务特点等,导致抽出的样本数据不能有效足够代表业务逻辑或业务场景;
(3)建模时使用了样本中太多无关的输入变量。
8.<1>构建决策树:在决策树模型构建中使用的算法对决策树的生长没有合理的限制和修剪,决策树的自由生长有可能使得每个叶子结点里只包含单纯的事件数据或非事件数据,这种决策树可以很好地拟合训练数据,但对于新的业务真实数据的效果却很差
<2>解决方法:
样本问题:合理、有效地抽样,用相对能够反映业务逻辑的训练数据构建决策树。
构建决策树的方法问题:主要方法是剪枝,即提前停止树的增长或者对已经生成的树按照一定的规则进行剪枝
<3>决策树的剪枝:
先剪枝:在构建决策树的过程中进行剪枝,当决策树高度达到最大高度、或达到某个结点的实例具有相同的特征向量、或达到某个结点的实例个数阈值、或达到信息增益阈值等条件即停止决策树的生长。以ID3算法构建决策树为例,就是当信息增益达到预先设定的阈值时候就不再进行分裂,直接将这个结点作为叶子结点,取叶子结点中出现频率最多的类别作为此叶子结点的类标签。
后剪枝:决策树建好之后,再对整个树进行剪枝操作,具体方法就是计算每个内部的结点剪枝前和剪枝后的损失函数,按照最小化损失函数的原则进行剪枝即用叶子结点代替该分支结点,该叶子结点的类标号用该结点子树中最频繁的类标记,或者保留此内部结点
9.贝叶斯分类:

10. 惰性学习法并不急于在收到测试对象之前构造分类模型。当接收一个训练集时,惰性学习法只是简单地存储或稍加处理每个训练对象,直到测试对象出现,才构造分类模型。主要包括以下几种方法:K最邻近分类法(KNN)、局部加权回归法、基于案例的推理
(1) K邻近算法的思想:从训练集中找出k个最接近测试对象的训练对象,再从这k个对象中确定主导类别,将此类别值赋给测试对象。假设训练对象有 n 个属性,每个对象由 n 维空间的一个点表示,则整个训练集处于n 维模式空间中。每当给定一个测试对象 c ,K近邻算法计算 c 到每个训练对象的距离,并找到最接近 c 的 k 个训练对象,这 k 个训练对象就是 c 的 k 个“最近邻”。然后,将测试对象 c 指派到“最近邻”中对象数量最多的类。当 k =1时,测试对象被指派到与它最近的训练对象所属的类。
K近邻算法进行分类时4个关键要素:
①被标记的训练对象的集合,即训练集,用来决定一个测试对象的类别。
②距离(或相似度)指标,用来计算对象间的邻近程度。一般情况下,采用欧几里德距离或曼哈顿距离
③最近邻的个数 k 。k 的值可以通过实验来确定。对于小数据集,取 k =1常常会得到比其他值更好的效果,而在样本充足的情况下,往往选择较大的 k 值。
④从 k 个“最近邻”中选择目标类别的方法。
K邻近算法的性能受影响因素:
<1>K值的选择:如果k值选择过小,结果会对噪声点的影响特别敏感;反之,k值选择过大,那么近邻中就可能包含太多种类别的点。
<2>目标类别的选择:最简单的做法是如之前所述的投票方式,然后对每个投票依据距离进行加权
<3>距离指标的选择:最佳测距方法应该满足这种性质:对象之间距离越小,它们同属于一个类别的可能性越大。
11. 神经网络:神经网络从信息处理角度对人脑神经元网络进行抽象, 建立某种简单模型,按不同的连接方式组成不同的网络。神经网络是一组连接的输入/输出单元,其中每个连接都与一个权重相关联。在学习阶段,通过调整这些权重,能够正确预测输入样本的类标号
神经元可以看作一个多输入、单输出的信息处理单元n个输入xi 表示当前神经元的输入值,n个权值wi 表示连接强度。f是一个线性输出函数,又称激活函数或激励函数。y表示当前神经元的输出值。
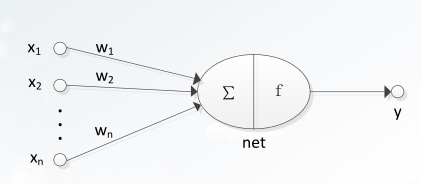
神经元的工作过程:1.输入端接受输入信号xi。2.求所有输入的加权和。3.对net做非线性变换后输出结果
神经网络由三个要素组成:拓扑结构、连接方式和学习规则
神经网络拓扑结构可以分为单层、两层或者三层。其中单层神经网络只有一组输入单元和一个输出单元。两层神经网络由输入单元层和输出单元层组成。三层神经网络用于处理更复杂的非线性问题,在这种模型中,除了输入层和输出层外,还引入了中间层,也称为隐藏层,隐藏层可以有一层或多层。每层单元的输出作为下一层单元的输入。
单层:
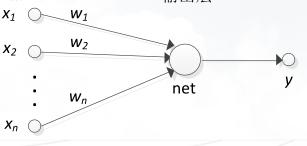
两层:

三层:
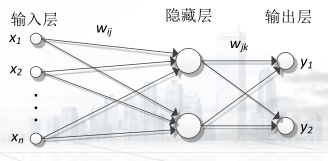
<1>输入层单元的个数由样本属性的维度决定,对输入单元所对应的各属性取值进行规格化,将有助于加快学习过程。通常,对输入值规格化,使得它们落入 0.0 和1.0 之间。
<2>输出层单元的个数由样本分类个数决定,一个输出单元可以表示两个类,如果多于两个类,则每个类使用一个输出单元
<3>隐藏层的层数和每层的单元个数由用户指定。对于“最好”的隐藏层单元数,没有明确的规则。
<4>网络设计是一个反复试验的过程,并可能影响结果训练网络的准确性。权重的初值也可能影响结果的准确性。一旦网络经过训练,并且其准确率不能被接受,通常用不同的网络拓扑或使用不同的初始权重集,重复训练过程
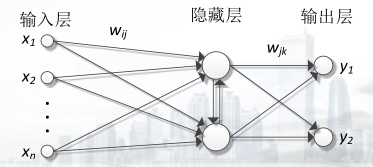
神经网络连接方式:神经网络的链接包括层之间的连接和每一层内部的连接,连接的强度用权表示。根据连接方式的不同分为前馈神经网络、反馈神经网络和层内有互连的神经网络。
<1>前馈神经网络也称前向神经网络,其中单元分层排列,分别组成输入层、隐藏层和输出层,每一层只接受来自前一层单元的输入,无反馈。
<2>反馈神经网络除了单向连接外,最后一层的单元的输出返回作为第一层单元的输入。
<3>层内有互联的神经网络是指在一个层内的神经元之间有互连。
前馈神经网络:

反馈神经网络:

层内有互联的神经网络:
神经网络的学习分为离线学习和在线学习两类:
离线学习是指神经网络的学习过程和应用过程是独立的
在线学习是指学习过程和应用过程是同时进行的
12. BP 神经网络算法过程:Back-Propagation Network,简称BP网络,是一种神经网络学习算法。对于一个训练样本,迭代过程:调用工作信号正向传递子过程,从输入层到输出层产生输出信号,这可能会产生误差,然后调用误差信号反向传递子过程从输出层到输入层传递误差信号,利用该误差信号求出权修改量,以便更新权值,这是一次迭代过程。当误差或权修改量仍不满足要求时,以更新后的权重复上述过程。
初始化权重:网络的权重被初始化为小随机数(例如,由-1.0到1.0)。每个单元都有一个相关联的偏移,偏移也初始化为小随机数。
BP神经网络算法过程
①向前传播输入:训练元组提供给网络的输入层。
②计算隐藏层和输出层的每个单元的净输入和输出。
③向后传播误差:通过更新权重和反映网络预测误差的偏移,向后传播误差。
④更新权重和偏倚,以反映误差的传播。
⑤终止条件:训练停止,如果前一周期所有的𝛥W𝑖𝑗都太小,小于某个指定的阈值,或前一周期误分类的元组百分比小于某个阈值,或超过预先指定的周期数

13. 向后传播算法
1. 后向传播通过迭代地处理训练元组数据集,把每个元组的网络预测与实际已知的目标值相比较进行学习。
2. 对于每个训练样本,修改权重使得网络预测和实际目标值之间的均方误差最小。
3. 这种修改“后向”进行,即由输出层,经由每 个隐藏层,到第一个隐藏层(因此称作后向传播)。
4. 一般地,权重将最终收敛,学习过程停止
后向传播算法在多层前馈神经网络上学习:网络是前馈的,因为其权重都不回送到输入单元,或前一层的输出单元。网络是全连接的,如果每个单元都向下一层的每个单元提供输出
14. 二分类问题,即分类目标只有两类,正类(positive)即感兴趣的主要类和负类(negtive)即其他类,正例即为正类的实例或元组,负例即为负类的实例或元组。
分类模型的评价指标:
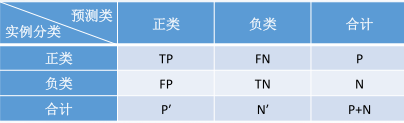
①真正例(True Positives, TP ):被正确地划分为正类的实例数,即实际为正例且被分类器划分为正例的实例数。
②假正例(False Positives, FP ):被错误地划分为正类的实例数,即实际为负例但被分类器划分为正例的实例数。
③假负例(False Negatives, FN ):被错误地划分为负类的实例数,即实际为正例但被分类器划分为负例的实例数。
④真负例(True Negatives, TN ):被正确地划分为负类的实例数,即实际为负例且被分类器划分为负例的实例数。
①准确率(accuracy):又称为分类器的总体识别率,准确率表示分类器对各类元组的正确识别情况,它定义为被正确分类的元组数占预测总元组数的百分比,
accuracy= (TP+TN)/(P+N)
②错误率(error rate):又称为误分辨率,错误率表示分类器对各类元组的错误识别情况,是1-accuracy。
error rate=(FP+FN)/(P+N)
③特效性(specificity):又称为真负例识别率(True Negative Rate,TNR),特效性表示分类器对负元组的正确识别情况,它定义为正确识别的负元组数量占实际为负元组总数的百分比。
specificity= 𝑇𝑁/𝑁
④灵敏度(sensitivity):灵敏度也被称为真正例识别率(True Positive Rate,TPR),即正确识别的正元组的百分比,衡量了分类器对正类的识别能力。
𝑠𝑒𝑛𝑠𝑖𝑡𝑖𝑣𝑖𝑡𝑦 = 𝑇𝑃/𝑃
⑤精度(precision):精度可以看做精确性的度量,即正确识别的正元组数量占预测为正元组总数的百分比。
𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑃/(𝑇𝑃 + 𝐹𝑃)
⑥召回率(recall):召回率用来评价模型的灵敏度和识别率,是完全性的度量,即正元组被标记为正类的百分比,即为灵敏度(或真正例率)。
𝑟𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑃/𝑇𝑃 + 𝐹𝑁 = 𝑇𝑃/𝑃
⑦ 综合评价指标(F度量):将精度和召回率组合到一个度量中,即为F度量(又称为F 1 分数或F分数)和F β 度量的方法。
𝐹 =(2× 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 × 𝑟𝑒𝑐𝑎𝑙𝑙)/(𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + 𝑟𝑒𝑐𝑎𝑙𝑙)
⑧假负例识别率:假负例识别率(FalseNegative Rate,FNR),它定义为错误识别为负类的正元组数量占实际为正元组总数的百分比。
𝐹𝑁𝑅 = 𝐹𝑁/(𝑇𝑃 + 𝐹𝑁) = 𝐹𝑁/𝑃
⑨假正例识别率:假正例识别率(False Positive Rate,FPR),它定义为错误识别为正类的负元组数量占实际为负元组总数的百分比。
𝐹𝑃𝑅 = 𝐹𝑃/(𝐹𝑃 + 𝑇𝑁)𝐹𝑃/𝑁
⑩ROC曲线:ROC曲线(Receiver Operating Characteristic Curve)是指接收者操作特征曲线,是反映灵敏度和特效性连续变量的综合指标,是用构图法揭示灵敏度和特效性的相互关系
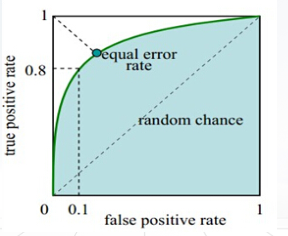
ROC曲线图中的四点一线:
①(0,1):即FPR=0,TPR=1。此时假负类率为0,假正类率为0,表示该分类器正确分类了所有样本;
②(1,0):即FPR=1,TPR=0。此时真负类率为0,真正类率为0,表示该分类器避开了所有的正确答案;
③(0,0):即FPR=0,TPR=0。此时假负类率为0,真正类率为0,表示该分类器将所有样本划分为负类;
④(1,1):即FPR=1,TPR=1。此时真负类率为0,假正类率为0,表示该分类器将所有样本划分为正类;
⑤虚线y=x:该线上的点表示一个采用随机猜测策略的分类器结果,表示该分类器随对于一半样本划分为正类,另一半为负类。
AUC:(Area Under Curve)被定义为ROC曲线下的面积,这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC值是一个概率值,当随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
<1>AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
<2>0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
<3>AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
<4>AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
15.交叉验证:交叉验证(Cross Validation,CV)是用来验证分类器性能的一种统计分析方法,基本思想是在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set)。首先用训练集对分类器进行训练,再利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标。交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合。交叉验证还可以从有限的数据中获取尽可能多的有效信息。
常见交叉验证的方法:
① 留出法 (holdout cross validation):将原始数据随机分为两组独立的数据集,一组做为训练集,一组做为验证集,通常2/3的数据分配到训练集,1/3数据分配到验证集。利用训练集训练分类器,利用验证集验证模型,分类模型的准确率使用验证集估计。
②k 折交叉验证(k-fold CrossValidation):初始数据随机地划分成k个互不相交的子集或“折” 𝐷1 , 𝐷2 ,..., 𝐷𝑘,每个折的大小大致相等。训练和验证进行k次。在第i次迭代,分组 𝐷𝑖用做验证集,其余的分组一起用作训练模型。即在第一次迭代,子集 𝐷2 ,... , 𝐷𝑘一起作为训练集,得到第一个模型,并在 𝐷1 上验证;第二次迭代在子集 𝐷1 , 𝐷3 ,..., 𝐷𝑘上训练,并在 𝐷2 上验证;如此下去迭代k次,得到k个模型。此方法中每个样本用于训练的次数相同,并且用于验证一次。对于分类,准确率估计是k次迭代正确分类的元组总数除以初始数据中的元组总数,即k个分类
模型验证集分类准确率的平均值。k一般大于等于2,实际操作时一般从3开始取, 10 折交叉验证最常用 。当数据量小的时候,k可以设大一些,这样训练集占整体比例就比较大,同时训练的模型个数也增多;数据量大的时候,k可以设小一些。
③ 留一法(Leave-One-Out Cross Validation):留一法是k等于N(N为样本总数)时的k k 折交叉验证 ,即每个样本单独作为验证集,其余的N-1个样本作为训练集。留一法得到N个模型,用这N个模型最终的验证集的分类准确率的平均数作为分类器的性能指标
自助法:在统计学中,自助法(Bootstrap Method,Bootstrapping或自助抽样法)是一种从给定训练集中有放回的均匀抽样,也就是说,每当选中一个样本,它等可能地被再次选中并被再次添加到训练集中。有多种自助方法,最常用的是.632自助法。假设给定的数据集包含 d 个样本。该数据集有放回地抽样 d 次,产生 d 个样本的训练集。这样原数据样本中的某些样本很可能在该样本集中出现多次。没有进入该训练集的样本最终形成验证集。显然每个样本被选中概率是 1/d ,因此未被选中的概率就是 (1-1/d) ,这样一个样本在训练集中没出现的概率就是d次都未被选中的概率,即(1−1 /𝑑 )^𝑑。当 d 趋于无穷大时,这一概率趋近于 𝑒^−1 −1=0.368 ,所以留在训练集中的样本大概就占原来数据集的63.2%。可以重复抽样过程k次,其中在每次迭代中,使用当前的验证集得到从当前自助样本得到的模型的准确率估计。模型的总体准确率估计公式:

