




数据仓库:
1.定义:数据仓库是一个面向主题的、集成的、时变的并且非易失的,用于支持管理者决策过程的数据集合
2.特征:面向主题的、集成的、时变的、非易失的
2.1面向主题的:
围绕重要的主题组织,例如客户、产品、销售额
关注决策者进行数据建模与分析,不关注日常操作及事务处理
通过排除对决策无用的数据,为特定主题提供简单且简洁的视图
2.2集成的:
基于集成多个异构的数据源进行构建:关系数据库、一般文件、联机事务处理记录
应用数据清理及数据集成技术,确保不同数据源中的命名约定、编码结构、属性度量等方面的一致性
当数据被移入数据仓库时将会被转换
2.3时变的:
数据仓库涵盖的时间范围要显著长于业务操作系统数据
数据仓库中的每个关键结构隐式或显式地包括时间元素,但是业务数据库中的关键结构既可包括也可以不包括“时间元素”
2.4非易失的:
数据仓库将业务环境中的数据转换并在物理上分离存储
数据仓库环境下不存在业务上的数据更新:不需要事务处理、恢复及并发控制机制,只需要两种数据访问操作:数据初始装入和数据访问
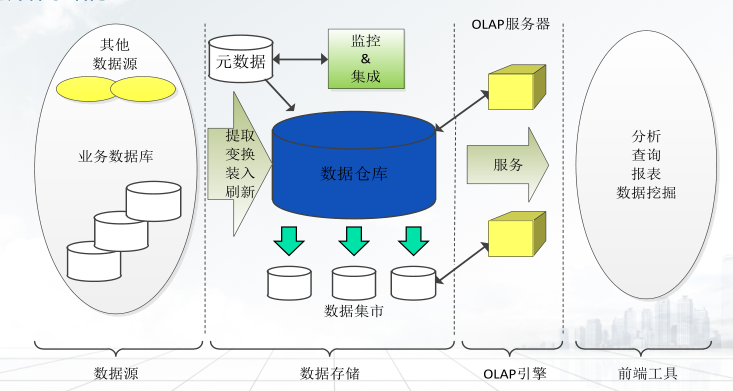
3.底层--数据仓库服务器:使用一些后端工具和实用程序,对其他外部数据源的数据进行提取、清理、变换、装入和刷新,将高质量的数据更新到数据仓库。
数据集市:也叫数据市场,是一个从操作的数据和其他的为某个特殊的专业人员团体服务的数据源中收集数据的仓库,是数据仓库的子集
中间层--OLAP 服务器: 联机分析处理(Online Analytical Processing, OLAP)是数据仓库系统前端分析服务的分析工具,能快速汇总大量数据并进行高效查询分析,为分析人员提供决策支持。使用OLAP相关模型将多维数据上的操作映射为标准的关系操作,或者直接实现多维数据操作。
OLAP操作可以与关联、分类、预测、聚类等数据挖掘功能结合,以加强多维数据挖掘
顶层 --前端客户层:包括数据挖掘工具(如趋势分析、预测等)、数据分析工具和查询与报告工具。用于知识发现相关工作人员(如经理、主管、分析人员等)直接操作获取知识
联机分析处理OLAP 特点:
快速性:系统能在秒级以内对用户的大部分分析要求做出响应
可分析性:能处理与应用有关的任何逻辑分析和统计分析
多维性:提供对数据分析的多维视图和分析,包括对层次维和多重层次维的完全支持
OLAP 体系结构:数据仓库与OLAP的关系是互补的,现代OLAP系统一般以数据仓库作为基础,即从数据仓库中抽取详细数据的一个子集并经过必要的聚集存储到OLAP存储器中供前端分析工具读取
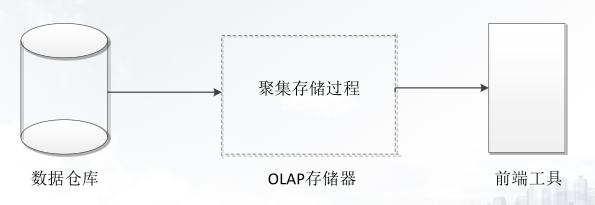
OLAP 实现类型:
关系OLAP(ROLAP)以关系数据库为核心,以关系型结构进行多维数据的表示和存储。
多维OLAP(MOLAP):以多维数据组织方式为核心,使用多维数组存储数据。
混合OLAP(HOLAP): 基于混合数据组织的OLAP实现。如低层是关系型的,高层是多维矩阵型的
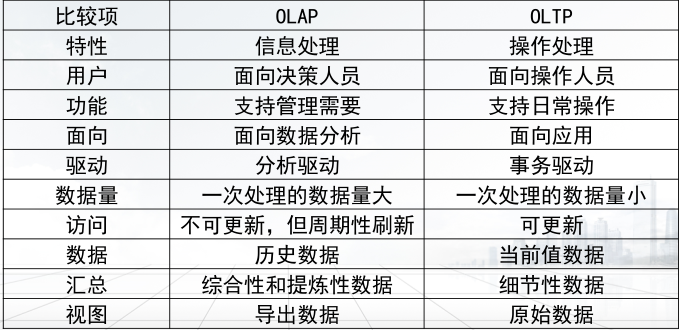
OLAP和OLTP的对比:
4.数据模型:数据模型是数据仓库建设的基础。
一个完整、灵活、稳定的数据模型对数据仓库项目的成功有重要的作用。
数据模型是整个系统建设过程的导航图
特点:
有利于数据的整合
排除数据描述的不一致性
可以消除数据仓库中的冗余数据
三级数据模型:
概念模型:对现实世界中问题域内的事物的描述,不是对软件设计的描述
逻辑模型:对概念模型中的主题进行细化;定义实体与实体之间的关系,以及实体的属性
物理模型: 依照逻辑模型,在数据库中建表、索引等;为了满足高性能的需求,数据仓库可以增加冗余、隐藏表之间的约束等反第三范式操作
粒度:数据仓库的数据单位中保存数据的细化或综合程度的级别
粒度越小,细节程度越高,综合程度越低,查询类型越多
粒度越高,综合程度越高,查询的效率也越高
在数据仓库中可将小粒度的数据存储在低速存储器上,大粒度的数据存储在高速存储器上
5.数据仓库的设计:分为概念模型设计、逻辑模型设计、物理模型设计
概念模型设计:对数据仓库涉及的实体和客观的实体进行抽象、分析,并在此基础上构建一个相对稳固的模型。需要充分了解业务及主要的关系,最终形成一个能够充分刻画对象的主题和关系的模型。 最常用的策略是自底向上的方法,即自顶向下地进行需求分析,然后再自底向上地设计概念结构,主要有以下两个步骤:抽象数据并设计局部视图;集成局部视图,得到全局的概念结构
①界定系统边界,即全方位了解任务和环境,充分理解需求,绘制大致的系统边界,即数据仓库系统设计的需求分析。
②确定主要的主题域,完成对一些属性、主题域公共码以及主题域之间的联系的描述工作,其中的属性能够清楚、充分地代表主题。
③细分具体内容及确定分析维度,维元素对应的是分析角度,通常是一些离散型的数据;度量对应的是指标,实际使用中要根据指标的存储和查询使用的频度来判断分析指标属于维元素还是维属性。
多维数据模型:
特点:简洁、面向主题的;直观的展示数据组织形式,利于数据的访问。包括星形模型、雪花模型、事实星座模型
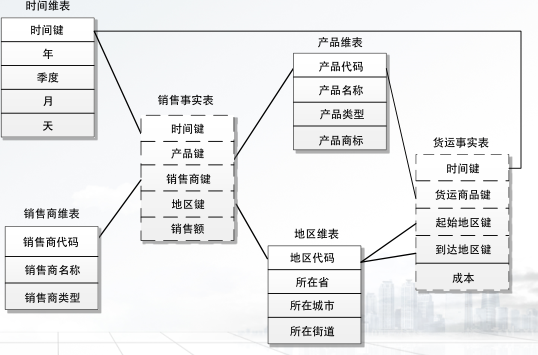
星型模型: 一种使用关系数据库实现多维分析空间的模型,由一个主题事实表和一组维表构成,事实表规模较大,包含大量的数据并且不含冗余
维表是事实表的附属表, 每一维都会有一个附属表,围绕在事实表周围
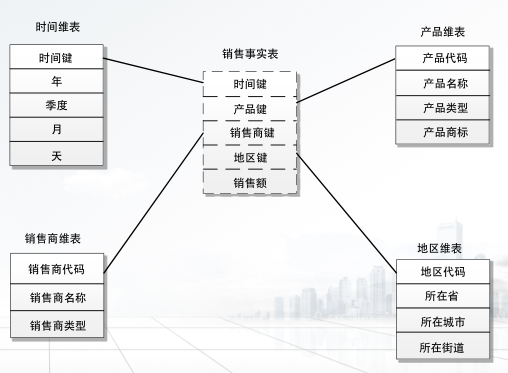
雪花模型: 对星型模型的扩展和延伸以及标准化,同时对星型模型的维表进行规范化,星型模型的维表的基础上进一步进分解出类别维表
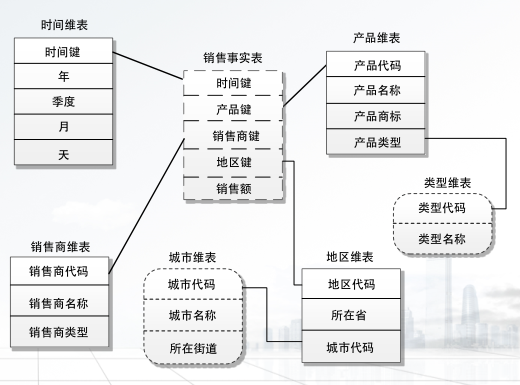
事实星座模型:可以很好的解决复杂应用的模型设计, 可以视为星形模型的集合,故也被称为星系模型
逻辑模型设计:进一步的完善和详细化设计,扩展主题域;奠定数据仓库的物理设计的基础; 通过实体和实体之间的关系勾勒出整个企业的数据蓝图和规划。主要的工作是进行事实表模型设计和维度表模型设计
事实表模型设计:把概念模型中的几个主题域进行分析
维度表模型设计:为用户提供主题的更加详细的具体的信息
主要步骤:
分析主题域,确定要装载到数据仓库的主题
粒度层次划分,通过估计数据量和所需的存储设备确定粒度划分方案
确定数据分隔策略,将逻辑上整体的数据分割成较小的、可以独立管理的物理单元进行存储
定义关系模式,概念设计阶段时基本的主题已经确定,逻辑模型设计阶段要将主题划分成多个表以及确定表的结构
物理模型设计:需要在充分了解数据和硬件配置的基础上确定数据的存储结构、索引策略、数据存放位置等信息
确定数据的存储结构:充分考虑所选择的存储结构是否适合数据的需要;考虑存储时间和存储空间的利用率
构建索引策略:通过索引的构架可以提高查询的效率和数据库的性能;常见的索引策略有B树索引、位图索引、簇索引
数据存放位置:相同主题的数据不需要存放在相同的存储介质;根据数据的使用频率和数据的重要程度以及时间响应要求,将不同数据存放在不同的存储设备上
6.在建立索引时需要注意以下几个通用的原则:
① 索引和加载:当存在大量的索引时,向数据仓库中加载数据速度会非常慢,可以在加载前先删除索引,完成后再建索引。
② 建立大表索引:当表太大时不能建立太多索引,如果必须建立多个索引,建议将大表分成小表再建立多个索引。
③ 只读索引:在数据检索过程中,索引记录是首先读入的,然后再读入对应的数据。也就是说在检索过程中,索引是只能被读取而不能被修改的。
④ 选择索引的列:分析最常用的查询,哪几列经常用来限定查询,那么这几列就是建立索引的候选列。
⑤ 分阶段的方法:一开始只为每个表的主键和外键建立索引,然后监视系统性能,特别是长时间运行的查询,根据监视结果再增加索引。
7.数据仓库实现:是一个信息提供平台;从业务处理系统获得数据,并主要以星形模型和雪花模型进行数据组织;为用户提供各种手段从数据中获取信息和知识;是一个过程而不是一个工程
数据仓库实现步骤:创建Analysis Services项目;定义数据源;定义数据视图;定义多维数据集;部署Analysis Services项目
元数据库:元数据是定义数据仓库对象的数据
元数据包括以下内容
数据仓库结构的描述:模式、视图、维、分层结构、导出数据的定义、数据集市的位置及内容
操作数据源:数据血统(迁移数据的历史和它使用的变换序列),数据流通(主动的、档案的或者净化的)和管理信息(仓库使用的统计量、错误报告和审计跟踪)
特点:用于汇总的算法;由操作环境到数据仓库的映射
关于系统性能的数据:数据仓库模式、视图和导出数据的定义
元数据的类型
根据使用情况不同:
业务元数据:从业务角度对数据仓库的数据进行描述
技术元数据:描述了关于数据仓库技术细节,主要用于开发、管理、和维护数据仓库
根据元数据的状态
静态元数据:主要包括业务规则、类别、索引、来源、生成时间、数据类型等
动态元数据:主要包括数据质量、统计信息、状态、处理、存储位置、存储大小、引用处等
元数据的作用: 数据仓库内容的描述、定义抽取和转化、基于商业事件的抽取调度、数据质量保证
元数据的使用:技术人员、业务人员、高级使用人员
