




01
Collect阶段
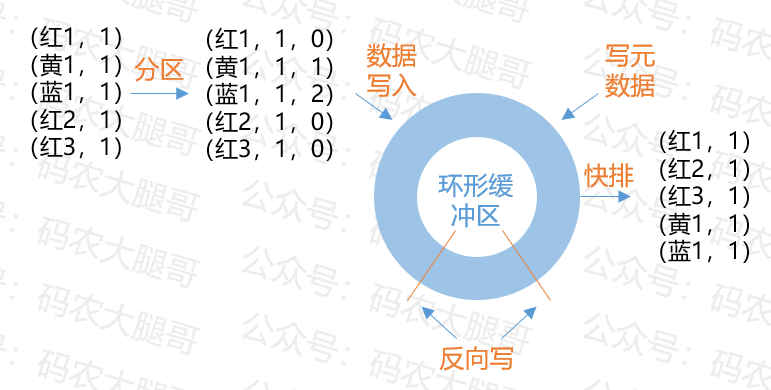
map()方法将数据处理成了(key,value)形式,然后输入到环形缓冲区,在这个过程中经历了以下几步

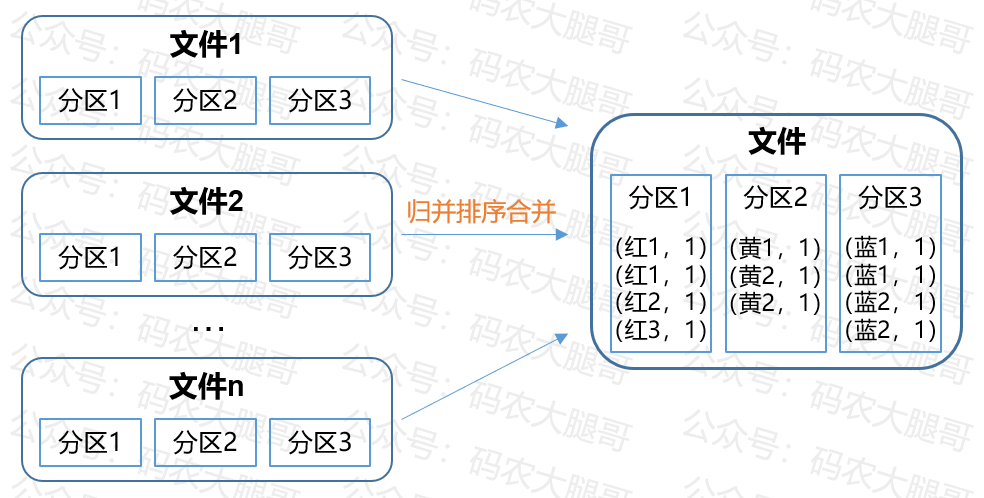
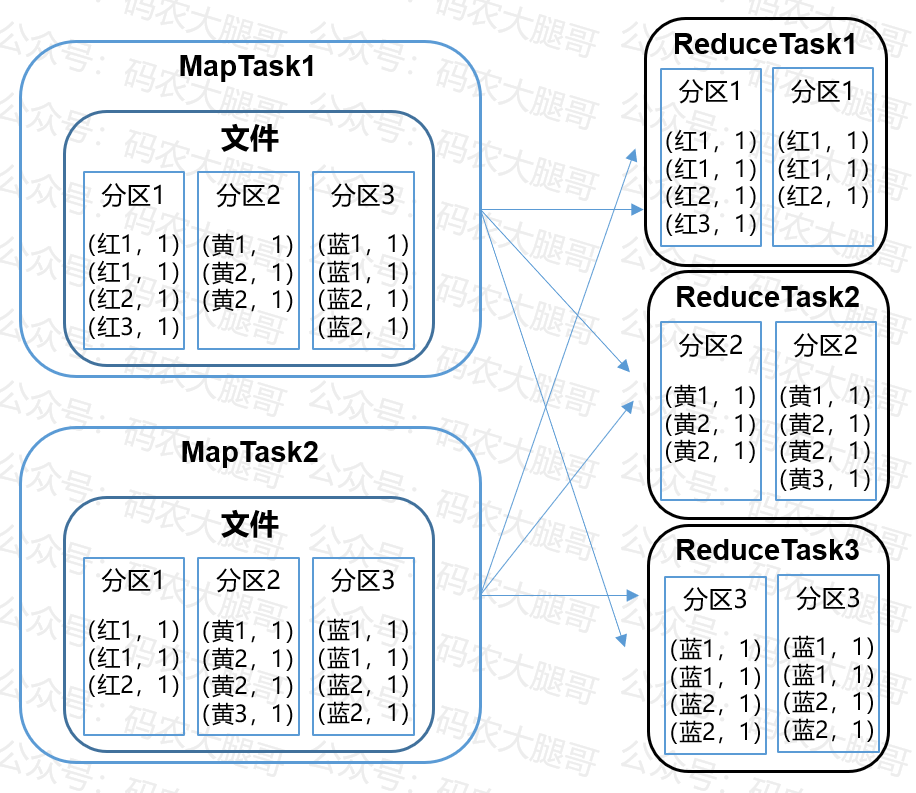
ReduceTask将拉取过来的所有文件进行合并,采用归并排序进行排序,得到最终的同一分区的排好序的数据

合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程
文章转载自码农大腿哥,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
2025年4月中国数据库流行度排行榜:OB高分复登顶,崖山稳驭撼十强
墨天轮编辑部
2509次阅读
2025-04-09 15:33:27
数据库国产化替代深化:DBA的机遇与挑战
代晓磊
1169次阅读
2025-04-27 16:53:22
2025年3月国产数据库中标情况一览:TDSQL大单622万、GaussDB大单581万……
通讯员
850次阅读
2025-04-10 15:35:48
2025年4月国产数据库中标情况一览:4个千万元级项目,GaussDB与OceanBase大放异彩!
通讯员
661次阅读
2025-04-30 15:24:06
数据库,没有关税却有壁垒
多明戈教你玩狼人杀
580次阅读
2025-04-11 09:38:42
天津市政府数据库框采结果公布,7家数据库产品入选!
通讯员
562次阅读
2025-04-10 12:32:35
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
542次阅读
2025-04-14 09:40:20
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
477次阅读
2025-04-17 17:02:24
一页概览:Oracle GoldenGate
甲骨文云技术
460次阅读
2025-04-30 12:17:56
GoldenDB数据库v7.2焕新发布,助力全行业数据库平滑替代
GoldenDB分布式数据库
452次阅读
2025-04-30 12:17:50
