




01
什么是切片
MapReduce要进行并行计算,就要对数据进行并行读取。也就是说,一整个文件先要分成几部分,然后再并行读取、并行计算
对输入的数据文件进行拆分的过程就叫做切片
2.切片的对象
切片是针对文件切片,就是说切片的最小粒度是文件
如果一个文件分了三个Block存在三台机器上,仍然当作一个文件处理。如果一个数据集包括很多文件,那么每个文件独立进行切片
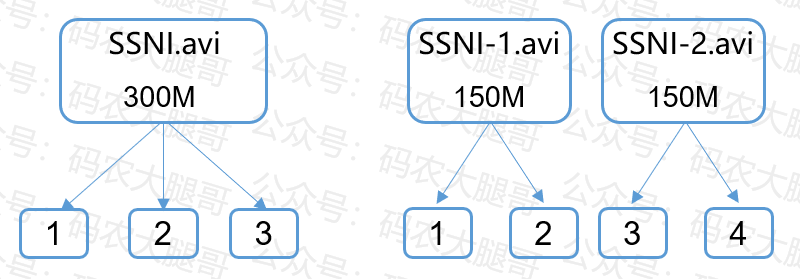
如上图,假设按128MB切片。一个300MB文件会切成3片,启动3个MapTask
如果两个文件300MB,每个文件单独切片,则会生成4个切片,启动4个MapTask
3.切片与Block
但是,切片指定的大小如果不等于Block大小,则会发生下面的情况:
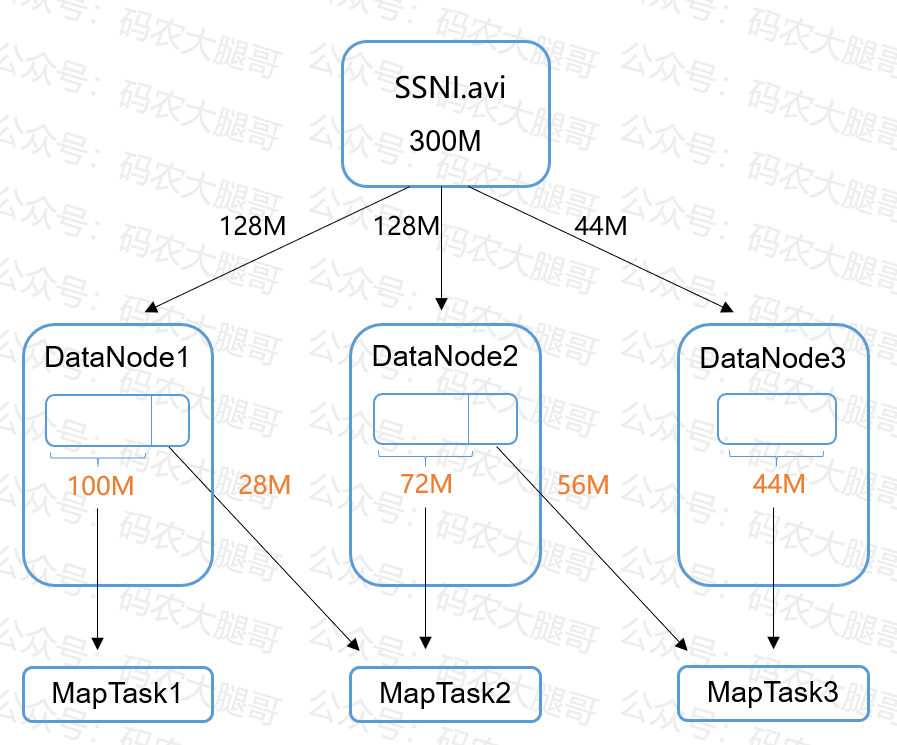
一个300MB的文件存储在HDFS上,则该文件会分成3个Block,存储在不同节点
假设我们指定切片大小为100MB。那么第1个Block就要切成两片,前100MB发往一个MapTask进行计算,后28MB和第2个Block的前72MB发往第二个MapTask进行计算
由于这种情况会产生网络IO,所以切片大小默认和Block大小一致,这样计算效率最高
4.切片大小的设置
默认情况下,切片大小 = BlockSize,即128M。切片大小是可以设置的,在源码中有一段关键代码决定了切片大小的设置。
Math.max(minSize , Math.min(maxSize , blockSize));复制
代码中有两个参数:maxSize、minSize。
maxSize:切片最大值,默认值是Long.MAXValue。maxSize设置的比BlockSize小,则切片变小
minSize:切片最小值,默认值是1。minSize设置的比BlockSize大,则切片变大
5.一个问题:129M的文件切几片?
一个切片的大小默认是128M,按理说129M的文件应该切2片,但实际上只会切一片
当文件大小大于切片大小的1.1倍时,才发生切片,不大于1.1倍就保留一片切片。所以,129M的文件实际上只切1片
02
切片机制剖析
前面说的切片是按照MR默认的切片机制来说的,其实MR提供了多种切片方式。MR程序的输入都要实现InputFormat接口,不同的实现类对应了不同的切片方式
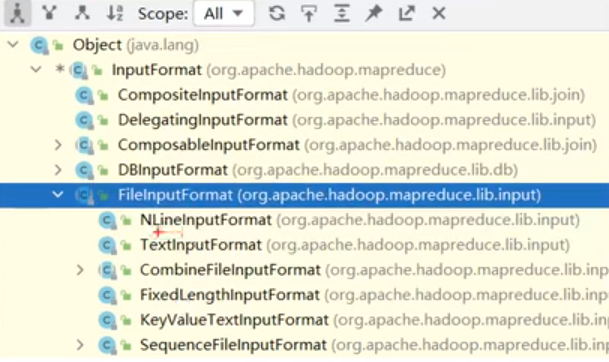
两个常用的实现类是TextInputFormat和CombineTextInputFormat,这两个实现类对应着不同的切片机制,它们和InputFormat的继承关系如下:
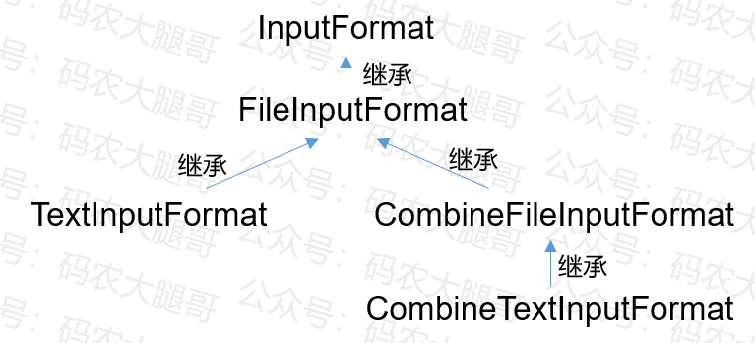
下面通过源码介绍以下两种切片机制
1.TextInputFormat
1)切片机制
按照文件的内容长度进行切片
切片大小默认等于Block大小
切片不考虑数据集整体,针对每个文件单独进行切片
切片时,要判断切完剩下的部分是否大于Block的1.1倍,不大于就不切
2)切片流程
3)源码剖析
TextInputFormat继承了FileInputFormat,但是没有重写getSplit()方法。所以切片逻辑是在FileInputFormat的getSplit()方法中
部分源码如下:
getSplit(){//minSize返回1,maxSize返回long类型的最大值long minSize = Math.max(getFormatMinSplitSize() , getMinSplitSize(job))long maxSize = getMaxSplitSize(job)//循环遍历每个文件for(FileStatus file : files){}//文件是否支持切割,如果压缩格式不支持切片,就只能启动1个mapTaskif(isSplitable(job , path)){}//获取Block大小,128MBlong blockSize = file.getBlockSize();//计算切片大小long splitSize = computeSplitSize(blockSize , minSize ,maxSize) ;computeSplitSize(){return Math.max(minSize , Math.min(maxSize ,blockSize))}}复制
切片大小计算的核心就是:
Math.max(minSize , Math.min(maxSize ,blockSize)
2.CombineTextInputFormat机制
TextInputFormat切片机制是根据文件切片。如果小文件过多,就会切很多片,启动很多MapTask,导致效率低下
CombineTextInputFormat可以将多个小文件从逻辑上规划到一个切片中,交给一个MapTask处理
1)切片机制
通过setMaxInputSplitSize()方法,设置一个切片最大值,小于该值的文件都归入一个切片中,由一个MapTask来计算
2)切片流程


— END —
