




继续回归干货,探索一下TF的内核,建议阅读时对着代码梳理。
1
异构框架与执行器
TensorFlow是一个异构的并行执行框架,本身就必须要对各种类型的Device做统一管理,还需要针对不同Backend的特性设计不同的执行器。凡是涉及到专用计算Device,无一例外和CPU都是异步的关系,既要最大化Device的并行度,又要在适当的地点与CPU同步,实在是一件非常繁琐的事情。因此,必须将执行器这一层抽象成中间层,甚至是中间件,用以隔离这种管理的复杂性。
Stream
先了解Stream的概念。存在于计算机相关的各种技术中,比如在操作系统、流式计算、计算机网络传输或是CUDA编程中都有涉及。Stream从抽象角度来看其本质是定义了一个操作序列。
处于同一个Stream的操作必须按顺序执行
不同Stream之间的并无顺序关系。
StreamExecutor简介
StreamExecutor本身就是一个在Google内部为并行编程模型开发的单独的库。在TensorFlow中的StreamExecutor是一个开源StreamExecutor的简版,并且并不是以第三方库的形式出现,而是在源码中单独放了一个stream_executor的文件夹,在下面这个位置。
StreamExecutor为TensorFlow的执行层面提供了较为统一的抽象,而在底层各种Device的执行管理细节却完全不同。可以看到stream_executor下面有cuda和host两个子目录,他们分别是GPU执行引擎和CPU执行引擎所使用的子模块。下面我们先从统一的抽象层面来梳理该框架的结构。
2
重要的Handler——Stream对象
为了隐藏StreamExecutor框架管理的复杂性,它对外暴露的handler必须足够简单。StreamExecutor通过暴露Stream对象作为操作底层的handler,通过Stream,用户可以调用底层计算库(CuDNN,CuBLAS等),也可以做Device间拷贝。
举例说明,Stream对象的ThenMemcpy即可完成异步的数据传输拷贝过程,调用ThenConvolveXXX等函数即可完成DNN库中的卷积调用。
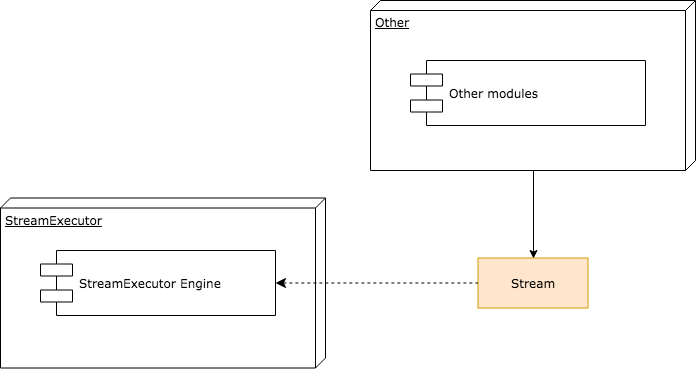
事实上,TensorFlow中很多Op的C++实现中,其Compute函数内就是通过使用Stream对象来完成某些实际计算或数据拷贝的过程,下图展示了Stream对象、StreamExecutor框架以及其他模块的关系。
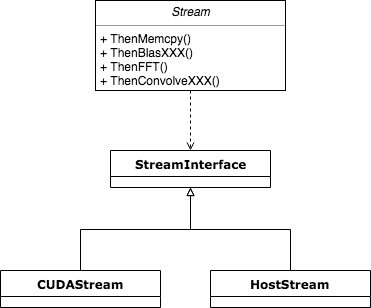
Stream对象是通过持有StreamInterface的具体实现对象来获得实际平台的Stream,进而通过Stream这个统一的handler完成与底层的交互,下面试这一子模块的类图结构。
3
StreamExecutor框架的层次结构
CUDA的编程模型的并行性很容易让人精神分裂,不但要用户控制每个id线程做的事情,还要管理Event,Stream等较为底层的对象。在复杂的Deep Learning框架里,这部分不抽象可不行。
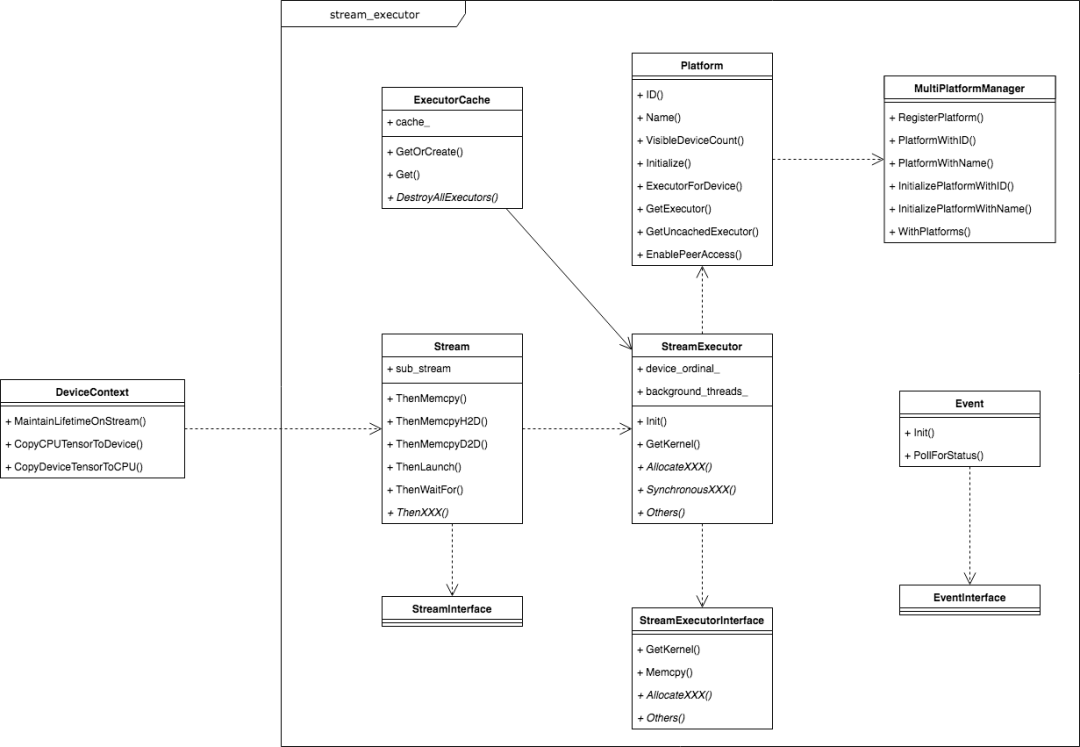
总体上StreamExecutor框架由三个层次组成,从上到下依次为Platform层(平台描述)、StreamExecutor Core层(执行引擎)和LibrarySupport层(基础库)。如果需要为TensorFlow添加新的计算设备种类,不但要向TensorFlow中注册Device的定义,还需要在StreamExecutor框架中提供负责管理该Device计算的代码。

Platform层
Platform指的是计算所使用设备平台的抽象,每种Device对应一种Platform。比如GPU对应的是CudaPlatform,而CPU对应的是HostPlatform等。
一旦获得了某种Device的Platform,就可以获取和该Platform对应的StreamExecutor Core以及相应的LibrarySupport。在TensorFlow的代码实现中,所有Platform类都是通过宏定义和MultiPlatformManager管理类的静态方法主动注册到系统中的,下面是这一层次的类图表示。
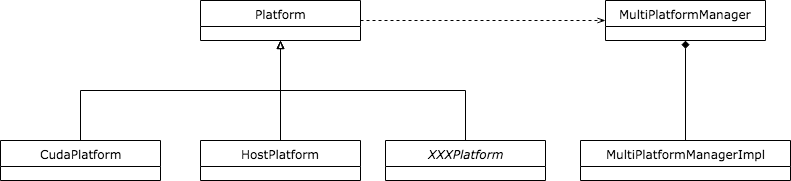
这种设计的扩展性也很好。假设新的Platform出现,直接继承Platform基类,并写好创建函数即可。
StreamExecutor Core层
对于外部使用者来说,获取Platform就是为了获取对应的执行引擎。对于TensorFlow这种存在多种Platform和执行引擎的异构框架来说,必须为每一种执行引擎提供完整的实现,这具有一定的复杂度。
为了让代码结构更有层次感,也为了向Platform层隐藏底层的设计复杂度,该层只向上层暴露StreamExecutor类,而涉及到具体实现的StreamExecutorInterface以及各种具体的实现将由StreamExecutor类统一控制,这种代理的方式让这一层的架构更加干净,下面是涉及到这一层的类图。
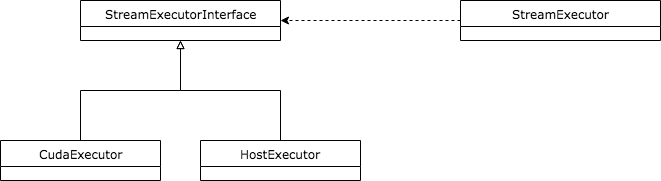
CudaExecutor和HostExecutor继承自StreamExecutorInterface后,由StreamExecutor持有,并暴露给上一层Platform使用。
读代码时还会看到一个叫做StreamExecutorCache的类,这是为了避免SteamExecutor被重复创建设计的缓存机制,也比较好理解。
Library层
作用就是调库,离底层最近的一个部分。
这一层提供的是各种底层加速库的接入,当前该层主要负责接入Dnn,Blas,Rng和Fft模块,每个模块和对应的类说明如下所示。
DNNSupport:主要包含DNN计算的基本操作。在GPU实现中,它将作为CuDNN的封装
RngSupport:随机数生成模块
BlasSupport:主要包含矩阵系列的计算,在CPU实现中它可以是Eigen,mkl等;在GPU实现中,它将作为CuBLAS的封装
FFTSupport:FFT系列运算模块
这些基础库同StreamExecutor类似,都具有平台属性。例如在CUDAHostPlatform中使用的Blas库应为CuBLAS,而HostPlatform中对应的可能是OpenBlas,MKL等。
虽然StreamExecutorInterface创建出来的各种Library指针均由StreamExecutor持有,但是他们却由StreamExecutorInterface的实现类负责创建,所以从逻辑上看他们处于StreamExecutor Core的下一层,下图展示了Library层的类图。
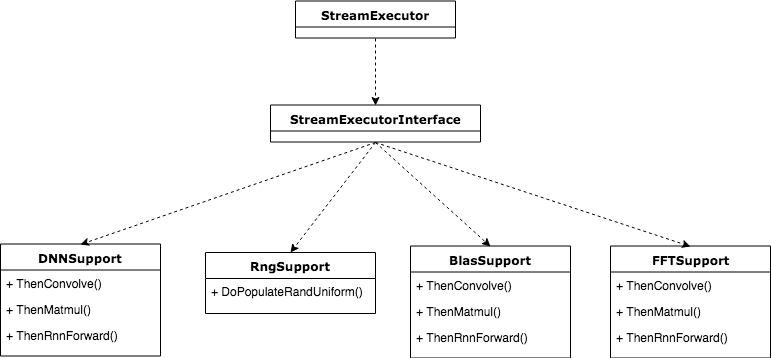
Library层将这些基础库统一作为插件(Plugin)来管理。他们通过PluginRegister模块注册。和StreamExecutor Core中的管理方式相同,也是工厂模式,具体可以考一下代码。
4
再看类图
更多组件
在StreamExecutor框架中还存在其他模块,比如XLA的支持,比如Event的管理,在逐个梳理StreamExecutor框架的三个层次后再看其余部分就非常清晰明了了,下面的两张图展示了整体类图和一些继承结构。
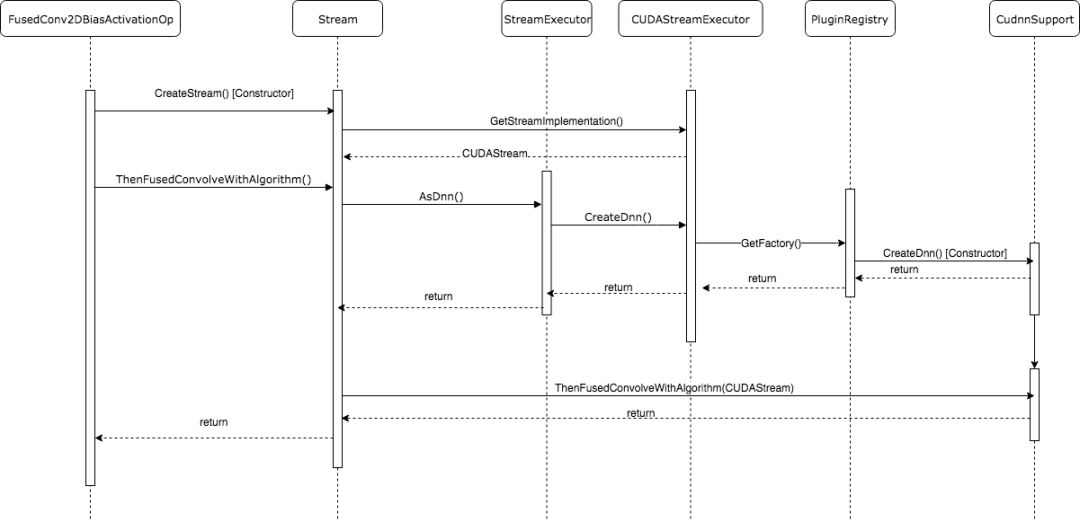
一次调用的完整调用栈
在完整的理解了StreamExecutor框架的内部结构和外部句柄后,我们就可以非常清晰地trace其调用栈了。最后,我们以调用Cudnn中的FusedConvolveWIthAlgorithm为例,画出完整的调用时序图。FusedConvolveWIthAlgorithm是将Convolution计算,Bias计算以及Activation计算fuse在一起的优化版本CUDA kernel,它的效率相对于分开调用相比更高。
讲技术,也谈风月,更关注程序员的生活状况,欢迎联系二少投稿你感兴趣的话题。
