




1
背景
以单个GPU能否承载整个模型的训练过程为判断标准,习惯上会将模型主观分类为大模型和小模型。在分布式训练领域,在小模型上应用简单的数据并行策略基本够用,最多加上一些可插拔替换的trick。但大模型的出现,尤其是Dense模型(比如GPT-3,Switch-Transformer等),不仅为分布式的实施带来了大量工程问题,同时也对策略的研究推向新的高潮。至少到目前为止,Dense大模型的分布式训练门槛还没有降低到对用户完全透明的程度。
之前梳理过两篇关于数据并行的优化实践文章,他们应对小模型或者Sparse大模型的大部分场景应该是够用了。今天简单列几种比较popular的大模型分布式策略。
2
参数量增速每年翻10倍
下图是截止到GPT-3发布时,业界一些语言模型的参数量增长趋势。我们可以看到,从2018年开始,每年新发布的模型参数量都是翻了10倍以上。而就在今年,Swtich Transformer已经达到万亿规模,ZeRO项目已经能够支撑甚至更大的模型。
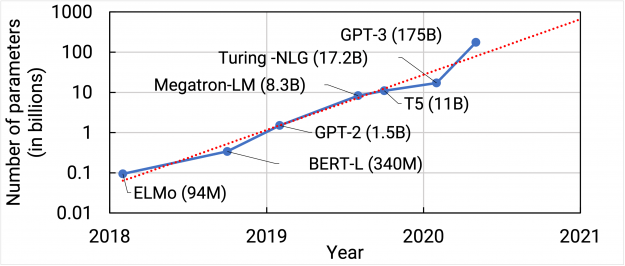
面对参数量如此巨大的增速,单个GPU早已不能支撑,分布式似乎已经是唯一的选项,不仅具有使用门槛,对软件技术,财力更是门槛。此时,依据基础设施能力的不同,不同公司的工程师们有完全不同的态度。
巨头们都在思考如何释放计算集群的算力,趁此打造技术护城河,支撑大模型训练。
另一些却在吐槽,浪费资源,效果提升有限,上线方式未知。
需求推动技术发展和方法创新,该解决的都会解决,哪怕是某个领域内的best practice都是极具价值的。
3
大模型分布式策略
必须要明确一点,每种并行模式都非常有效,但都有各自适用场景和使用门槛。同样是大模型,不同的模型种类,不同的Device拓扑关系也都会影响其并行模式的选择。
流水并行
这是一种模型并行的方式。为了区分其他模型并行类型,文献中一般将其称之为Pipeline parallelism。具体地,一般以Layer为单位,将模型的不同Layer映射到不同的Device上。如果把用户定义的Model看做DAG,那么将不同算子映射到不同Device上也可实现流水并行。显然,这是利用多个Device瓜分大模型已达到支持超大规模模型的方式之一,GPT-3和Bert系列就可以使用这种并行模式。
这样做的一个特点是,因为DAG的拓扑序原因,Layer和Layer之间一般是先后执行的关系,所以流水的不同Stage是串行执行的,这就要求必须通过其他手段想办法令多个Device并行工作,提高吞吐。
典型的流水并行方式有GPipe,PipeDream,DAPPLE等。下面只列出GPipe的做法,其他的文献我们后续详细展开。
论文:GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism https://arxiv.org/pdf/1811.06965.pdf
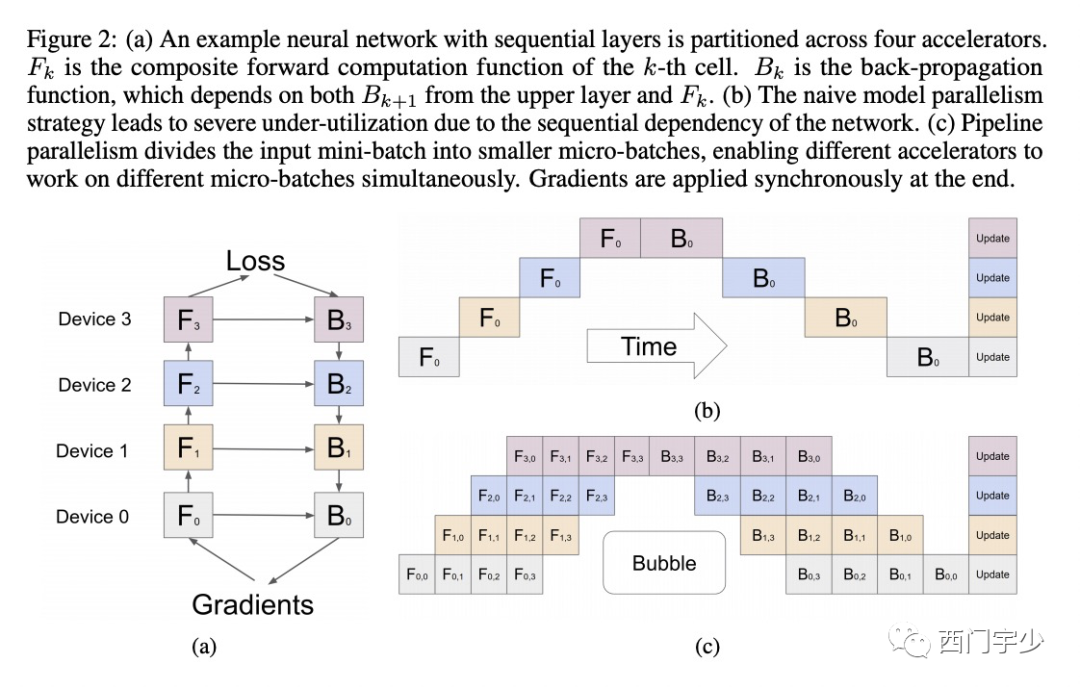
假设用户手动的将某个Model的前向计算过程分成了4个Stage,即F0,F1,F2和F3,依次放到Device 0~3上,而每个Stage的反向与其对应前向捆绑放在一起,那么当某个Batch的数据喂入F0时,会依次触发F0~F3,B3~B0顺序的计算。对应Device的工作顺序为Device 0~3,然后再从3~0,显然具有明显的串行行为。
下面图(b)中展现了这个串行执行过程。以横向为时间轴,纵向为Device轴(空间轴),可以看出在大部分时间里,每个Device都有处于Idle的状态(文献中称为Bubble time),总体利用率极低。
GPipe提出将大的Batch size拆分成多个小的micro batch,并且在不同的时间点推送给Stage 0(即F0)。这样做的一个好处是,当Device 1在运行某micro batch时,可以让Device 0运行下一个micro batch,两个device在此时可以并行计算。下面图(c)展示了这个过程,我们可以看到,Bubble time占比确实降低了一些。
Pipeline Parallelism使用有其门槛,主要在以下几个方面。
切分Stage的切点选择,尽可能保证每个Stage计算量均衡,并且跨Stage传输量不大
合理的调度
显存的管理
PipeDream提出了使用异步的方式进一步提高并行度,而DAPPLE则对同步Pipeline做了一些改进,之后再专题中详细展开。
算子拆分
另一种模型并行策略,文献中一般叫做Sharding或者Operator partitioning,与Pipeline Parallelism切分算子之间或者Layer之间的连接不同,算子拆分主张切分Operator。典型的例子如矩阵分块乘法。
假设有矩阵C=[C1, C2], A=[A1, A2]。那么在数学上以下两者等价。
A=matmul(B, C)
[A1, A2] = matmul(B, [C1, C2])
这样的一个好处是,如果矩阵C太大,以至于单卡都放不下,那么可以通过将C拆成两个部分C1和C2分别放到不同Device上以共同表示一个完整的Tensor效果。此时,我们把矩阵B复制到两个Device上,那么两个Device分别执行matmul(B, C1)和matmul(B, C2)即可共同完成原matmul(B, C)的等价逻辑。当然,产出的结果A1和A2也是以拆分的形式分别放在不同Device上,用以表示一个完整Tensor A。
这种计算必须要拆分matmul算子,迫使原来的一个matmul变为两个可以并行计算的matmul,好处是:
每个Device占的显存少了,可以放更大的模型
每个Device的matmul的计算速度提升了,因为参与计算的Tensor变小了
整体的吞吐变快了,因为matmul在不同Device上并行起来了
除了matmul,每个算子都可以拆分,但有些拆分的计算会引来额外的通信,因此不是盲目的拆分,而是有选择的拆分。至于选择哪些算子拆分,这是一个open problem,需要通过各种搜索才能找到较优的解。
另外,每种算子的拆分都有不同的计算逻辑。matmul和element wise不同,reshape则更不同。
在做法上面,Mesh TensorFlow选择引入新的编程范式,对所有的算子都实现了拆分版本,用户必须重新使用新的API编写模型。而GShard选择在XLA的HLO上进行拆分推导,尽可能地保留用户原来的模型写法(但需要借助一些简单的annotation)。二者都由Google出品。
Megatron-LM,T5模型和Switch Transformer都使用了算子拆分的方案。下面简单展示一下Megatron-LM的拆分做法,其他Sharding内容后续将详细展开。
Megatron-LM
https://arxiv.org/pdf/1909.08053.pdf
Megatron-LM本质是Transformer,每个Transformer layer都比较占显存空间,并且都是Dense类型,对比较大的算子和Tensor进行拆分是比较不错的选择,比如Self-Attention的Head维度和Feed Forward的Tensor。下图是这两个结构的拆分。
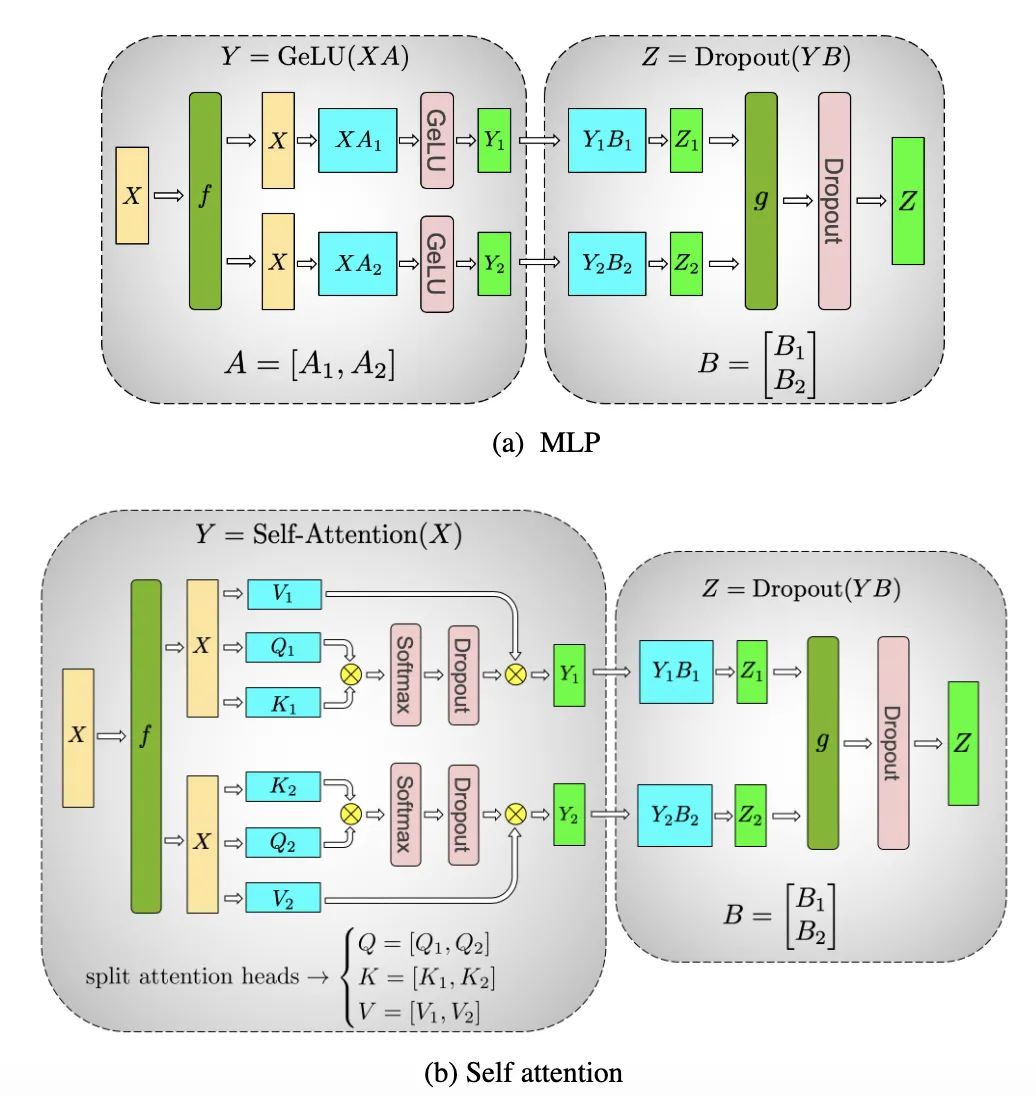
算子拆分使用也有门槛,主要在以下几个方面:
哪些算子值得拆分,拆多少份,哪些保留不拆,这是搜索空间极大的问题
API设计与易用性,如何让用户尽可能不改代码的情况下使用
其他文献的内容,后续再谈。
多策略混合
Data Parallelism,Pipeline Parallelism和Sharding三种中的全部或者几种的组合。这是一个非常难但非常有价值的问题。其中Data Parallelism可以归类为Sharding,即切分到了Batch size维度,但为了和模型并行区别,我们单独讨论。
从策略搜索上说:
Pipeline Parallelism难点在于Stage切点选择,大模型搜索空间很大
Sharding难点在于切分的算子选择,大模型搜索空间很大
上述二者互相串扰,互相影响,使得搜索空间更大
与Data Parallelism结合的选择,也扩大了搜索空间
不同的Device种类,Device拓扑链接关系,对策略来说也是个巨大的搜索空间(TPU的连接是高速链路,GPU的连接存在机内和跨机两种链路)
目前看到的有Google的GSPMD工作将三者结合了起来,但策略的自动化搜索还是个非常open的问题。面对np hard问题,也许启发式结合一些random search是比较好的选择,比如FlexFlow的策略。
以上就是一个简单的开篇,望多提意见多留言~ 感谢大家。
讲技术,也谈风月,更关注程序员的生活状况,欢迎联系二少投稿你感兴趣的话题。
