




好久不见,最近因为膝盖半月板撕裂以及装修的事情,一直没有更新文章。今天更新一篇文章,分享我对深度学习框架Jax的一些初步调研。
1
初识Jax
套用知乎大佬的一句话来介绍Jax就是——能使用GPU加速的,支持自动微分的numpy。numpy在科学计算领域十分普及,但在深度学习领域,有两个制约它使用的因素:1. 没有自动求导;2. 不能用GPU加速。也正是因为如此,才会出现TensorFlow,PyTorch这样的框架,在做法上,他们或者定义了新的编程语言,或者创立了更易用的API。
为什么选择numpy而不是再造API?这是因为再造深度学习模型API有很大的推广风险和成本。目前,深度学习模型的API仍属于比较混乱的状态。以TensorFlow为例,在1.x的迭代中,就存在如原子op、layers等不同层次的API。面对不同类型的用户,使用粒度不同的多层API本身并不是什么问题。但同层次的API也有多种竞品,如slim和layers等实则提高了学习成本和迁移成本。2.x迭代中的keras虽有做统一梳理的用意,但实际上也很难约束住用户。Jax则规避了直接定义API这件事,选择了状态稳定,用户普遍熟悉的numpy作为API,是十分漂亮的做法。
使用时,将import numpy as np替换成import jax.numpy as jnp即可。例如前向可定义如下:
import jax.numpy as jnpdef predict(params, inputs):
for W, b in params:
outputs = jnp.dot(inputs, W) + b
inputs = jnp.tanh(outputs)
return outputs
def loss(params, batch):
inputs, targets = batch
predictions = predict(params, inputs)
return jnp.sum((predictions - targets)**2)复制
反向计算的工具库是autograd,这是一个针对numpy的自动求导库,严格来说是Jax把它集成了进来。承接上面的forward,我们构造其backward和model update过程,体感如下:
from jax import grad
def update(params, batch):
grads = grad(loss)(params, batch)
return [(w - step_size * dw, b - step_size * db)
for (w, b), (dw, db) in zip(params, grads)]
for epoch in range(num_epochs):
for _ in range(num_batches):
params = update(params, next(batches))复制
至此你会发现,Jax并不是像TensorFlow那样先定义静态图,再启动sess.run()的写法,而是像PyTorch,偏Pythonic的写法。那么问题来了,没有图模式,它的性能会怎么样?
2
用XLA优化你的性能
XLA是TensorFlow底层做JIT编译优化的工具,XLA可以对计算图做算子Fusion,将多个GPU Kernel合并成少量的GPU Kernel,用以减少调用次数,可以大量节省GPU Memory IO时间。简单的例子体感如下:
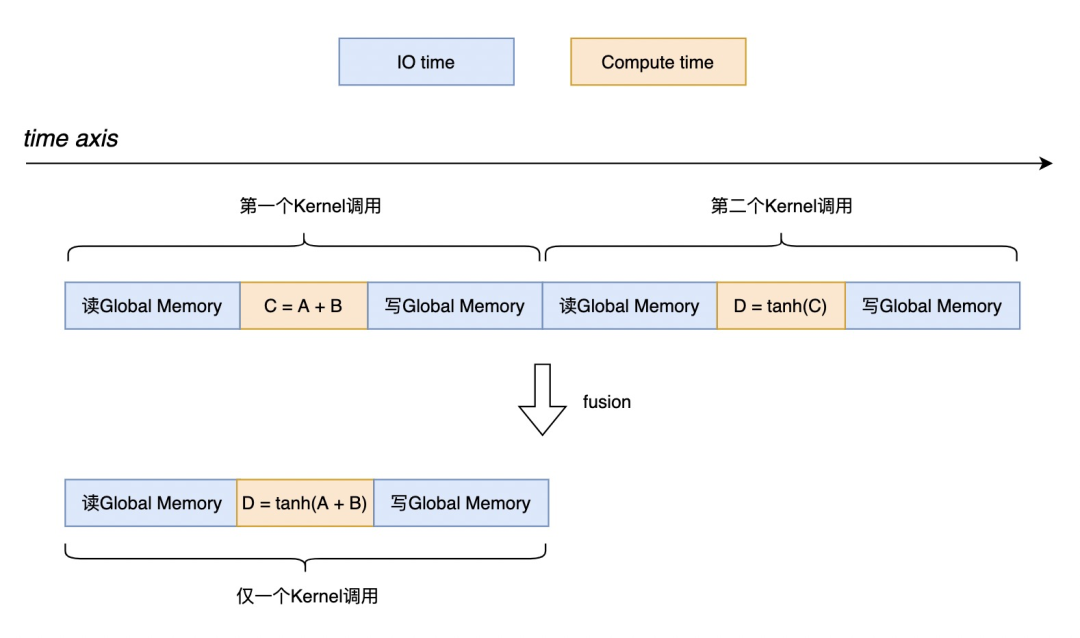
要能识别到这种计算Pattern,必须能够让XLA看到计算的上下文。TensorFlow是通过先定义计算图,再交给XLA做分析的(准确来说是在XLA中先将计算图转换成HLO IR,再做分析)。而Pythonic模式并无定义计算图步骤(PyTorch和Jax都属于这个模式),因此只能用trace的方法记录完整的计算Pattern。
使用上也比较简单,直接在欲编译的函数加上@jit修饰符即可启用。比如我想对上述整个训练计算都做编译优化,直接对最后的update函数添加修饰即可:
from jax import jit
@jit
def update(params, batch):
grads = grad(loss)(params, batch)
return [(w - step_size * dw, b - step_size * db)
for (w, b), (dw, db) in zip(params, grads)]复制
这里有两点需要注意:
编译优化的收益也取决于模型特点
@jit圈的范围越大,越可能达到更大的收益
Jax的编译优化工具,既可以对接GPU也可以对接TPU,总之对用户是完全透明的。看到这里,至少咱们会用Jax搭建模型,并且使用编译优化手段获得计算加速收益。
3
Jax真正的执行过程
Jax本身并没有重新做执行引擎层面的东西,而是直接复用TensorFlow中的XLA Backend作为底座。事实上,XLA Backend确实可以作为这样一种通用的编译优化执行引擎。如下图所示,对XLA而言,只要计算逻辑能够转换成HLO,就能成功对接XLA Backend。这一点从Jax框架source code上也能看到对xla_client的完整复用。
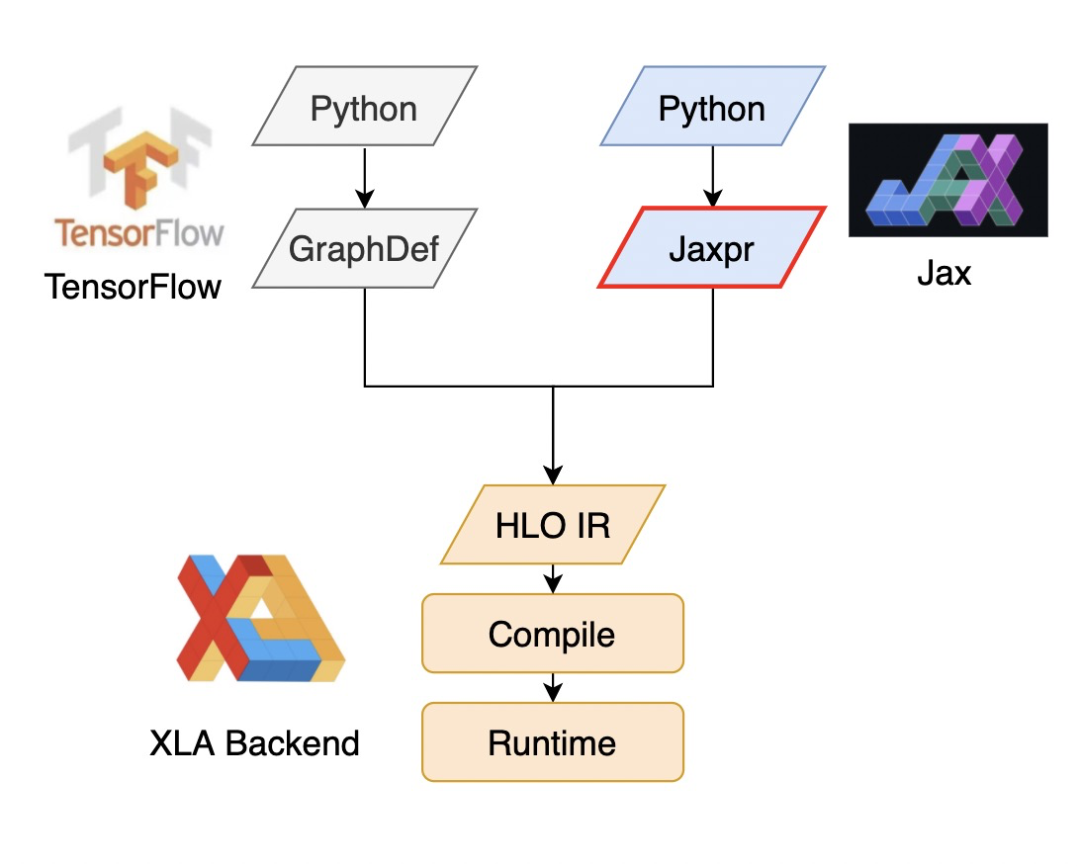
因此,Jax框架源码基本都是Python写的,除了一套完整的API装饰器之外,还有十分重要的功能——Trace。TensorFlow是通过将用户搭建的模型记录为GraphDef(我们所说的静态图IR),然后转换成HLO IR交给XLA运作的。而Jax虽然没有静态图,但它也需要一种IR来Trace模型API的调用链。
注意上图中红圈圈出来的菱形部分,它就是Jax对Python trace出来的一种IR,叫做Jaxpr,它的每一条指令,都是对模型搭建API的trace结果,记录了其参数及其shape,以及所用计算函数等。然后Jaxpr才会被转换成HLO,交给XLA Backend做编译优化执行。Jaxpr长什么样子?我们还是拿熟悉的函数举一个例子,回顾下这个函数:
import jax.numpy as jnp
from jax import jit
@jit
def predict(params, inputs):
for W, b in params:
outputs = jnp.dot(inputs, W) + b
inputs = jnp.tanh(outputs)
return outputs复制
对应的Jaxpr如下:
{
lambda inputs ; params.
let (b, c) = params
(d, e) = b
g = dot inputs d
h = add g e
i = tanh h
(j, k) = c
l = dot i j
m = add l k
in m
}复制
别慌,我解释一下:
Jaxpr是一种SSA指令,因为等号左边总是产生新的变量名,从来不会做变量名的复用
lambda开头即引出原被修饰函数的参数列表,参数列表顺序与命令和原函数完全相同,变量之间用分号(;)隔开
let开始即为指令正文,每一行采用后缀表达式陈列
in即return,表示结束时的返回值
指令序列非常单纯,无嵌套,循环等结构,原语言中所有的循环都被平铺展开
所以,整个trace的过程并没有涉及到真正的编译,计算等,而是纯纯粹粹的前端记录过程,可以认为是一种假执行过程。这一点非常重要,通过这种方式,Jax能够从头到尾将整个计算逻辑全部trace,使编译过程有全局角度,从而采取更加激进的优化策略。与此同时,由于只是做trace,所以实现了在不真正消耗资源的情况下,获得了程序执行的全部静态信息。这在源码上是怎么做到的?我们以tanh函数为例,研究下源码。
(Jax源码文件:lax.py)
def tanh(x: Array) -> Array:
return tanh_p.bind(x)复制
注意函数参数以及返回值的类型——Array。但按上面的分析,此处应该传入的是一种Tracer对象才符合逻辑,因此判断此处Array有鬼。进一步发现Array类型的定义为:
Array = Any复制
也就是说语义上Array可以超越字面意思,表达任意类型了。不过还是要确认下Any的定义:
Any = object()复制
豁然开朗。Array的本质是Python的内置类型object(Python的任何对象都是object子类)。因此传入Tracer是没有问题的了,至于每个函数怎么用tracer,今天就不再讨论了。
以上就是对Jax框架的一个初步的调研。
讲技术,也谈风月,更关注程序员的生活状况,欢迎联系二少投稿你感兴趣的话题。
