




二少决定不定期和大家分享TensorFlow底层的架构设计和源码,这些可能有助于做性能优化,推进落地~
建议阅读时对着代码梳理~
讲技术,也谈风月,更关注程序员的生活状况,
欢迎联系二少投稿你感兴趣的话题。

1
Tensor传输和Session管控是两回事
前一篇文章我们了解了Rendzvous的抽象以及本地传输的过程,今天我们来谈谈这个Rendzvous架构是如何实现真正的跨机传输的。
与其他分布式训练框架不同,Google选用了开源项目gRPC作为TensorFlow的跨机通信协议作为支持。
如果你在代码中看到有GrpcSession,千万不要认为它是用来传输Tensor的。GrpcSession利用gRPC管控多个worker的Session,而不是用来传输具体的Tensor。在TensorFlow中,无论你用什么协议传输Tensor,管控工作都可以交给GrpcSession,这是需要区分的。
2
跨进程通信过程
前一篇我们已经了解,Rendzevous架构中,本地传输的通信过程理解关键点在于下面这一句重点:
Send只是把消息挂到队列里,而Recv主动过来拿数据!
其实,使用gRPC传输Tensor也同样遵循这个规则。我们马上用gRPC套一下这个过程,非常简单。
1. Send方——将Ready的Tensor挂入本地Table
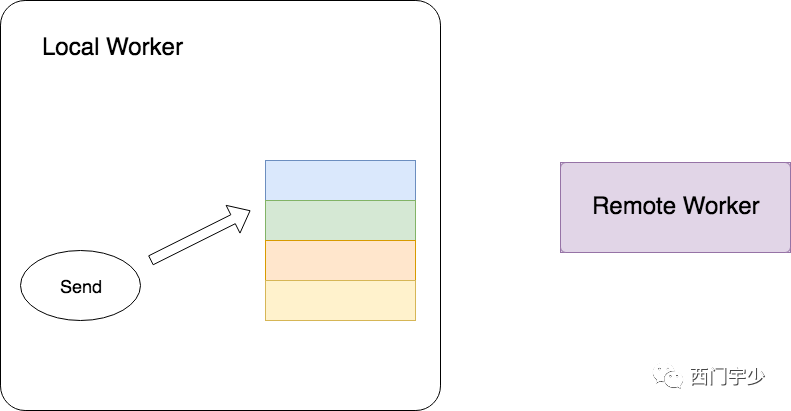
发送方在做Send时,只是将待发送的Tensor挂在本地Worker的Table中,至此Send过程就全部完成了。
所以Send过程完全没有涉及到任何跨网络传输的内容,并且Send过程是非阻塞的。下面的图表达了Send的过程。它明显与Remote Worker没有任何关系。
2. Recv方——主动发出请求,触发通信过程
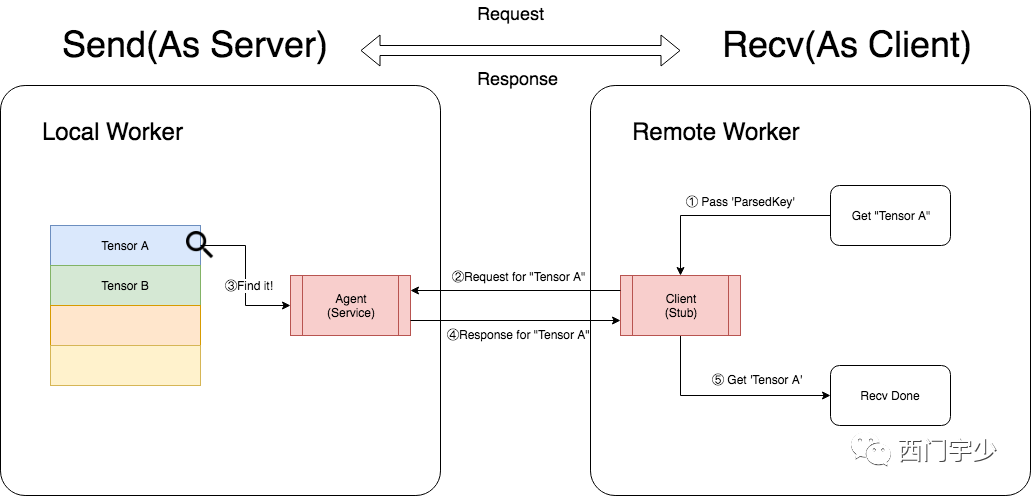
Recv方是Tensor的接收方,它与Send方的交互过程描述如下:
a. 主动向Send方,发出跨进程的Request;
b. Send方在接收到Request后,立即在本地Table中查找方所需要的Tensor;
c. Send方将Tensor封装成Response发回Recv方;
d. Recv方接受到Response,传输完成。
在这个过程中,Recv方可以认为是Client,Send方可以认为是Server,通过发送Request和Response来完成Tensor的传输。
下面的图表达了这个交互过程。
3
结构设计解析
代码上看,虽然原理简单,但是封装还是复杂了些。
一方面,实现本身具有相对较高的复杂性(大家可以尝试阅读gRPC源码感受下底层软件的复杂度)。
另一方面,应用层也需要与通信底层通过抽象尽量实现较好的解耦,这样也方便将应用层模块被其他团队扩展编写。
下面我们一起来探究TensorFlow中涉及到跨进程通信的Rendezvous系列的结构设计。
1. 两层抽象继承关系——RemoteRendezvous与BaseRemoteRendezvous
跨进程传输也有不同的Rendezvous,从根源上来说,它们也继承于Rendezvous接口,并且不同的传输协议也有各自的Rendezvous。
在这里,我们再次将前文中展示的总体类结构图展示出来,这次我们将涉及到远程传输的类用特殊颜色标出,如下图所示。
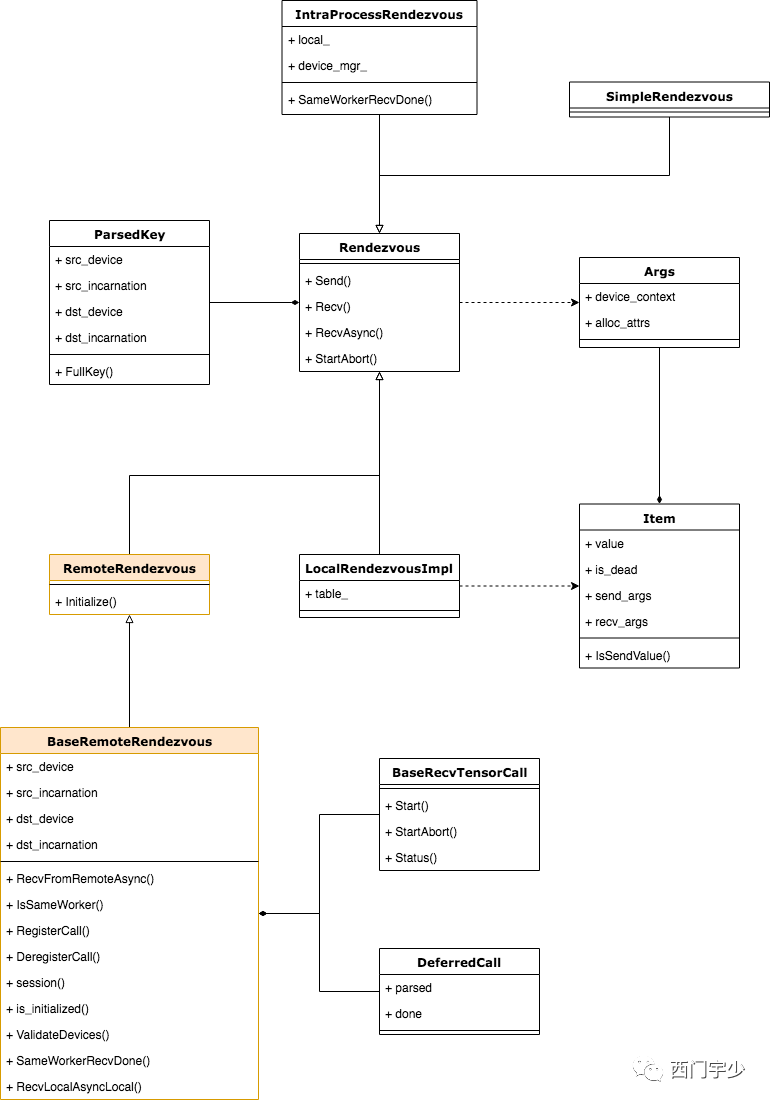
从Rendezvous的继承结构来看,涉及到跨进程传输的Rendezvous有两层:
a. RemoteRendezvous:只增加了一个Initialize方法,并标记为纯虚函数。这是因为跨进程Rendezvous需要借助Session做一些初始化工作;
b. 各种具体协议Rendezvous的基类——BaseRemoteRendezvous:它提供了公共的Send和Recv方法,这可以让继承它的特化Rendezvous尽最大可能做到代码复用。
BaseRecvTensorCall是通信的实体抽象,后面分析时会有更深的体会,在这里先有个印象即可。
2. 开始特化——各种各样的RemoteRendezvous
TensorFlow目标是通用可扩展,所以被设计成允许底层支持多种通信协议的结构。事实上到目前为止,算上contrib目录的内容,TensorFlow已经支持包括gRPC,RDMA(Remote Direct Memroy Access),GDR(GPU Dirrect)和MPI四种通信协议。
每种通信协议各有其特点,有时候其可用性也取决于硬件和软件条件(比如RDMA需要支持RDMA协议的网卡,通常跑在Infiniband和RoCE网络上,如果没有硬件支持,那么RDMA将无法使用,GDR也是这个道理)。
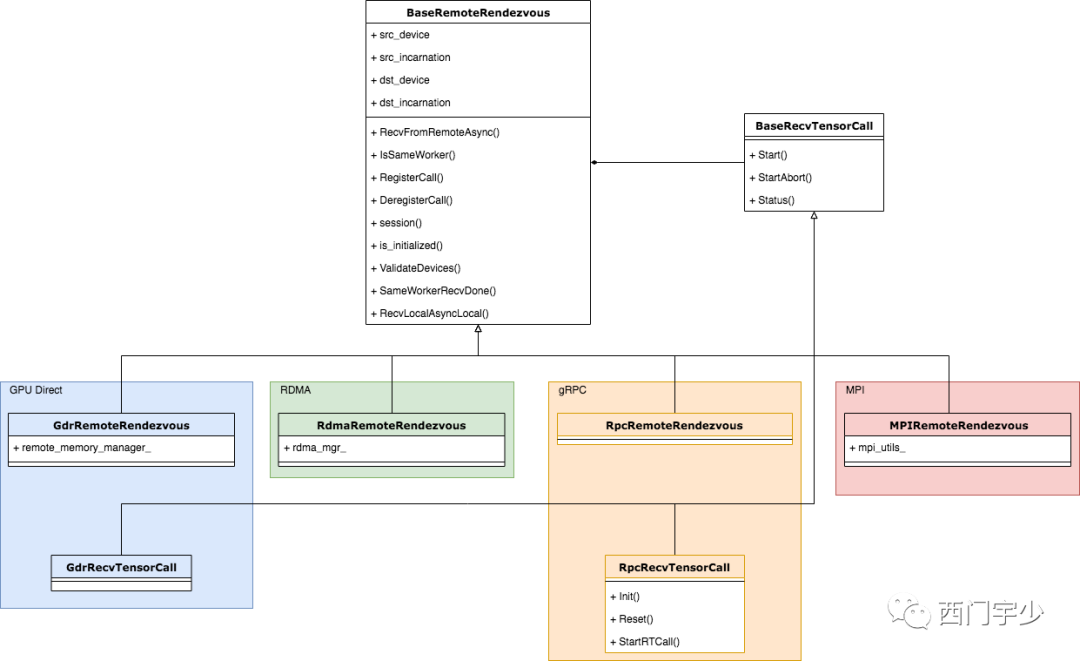
在本篇我们关注RpcRemoteRendezvous,它是gRPC协议实现的RemoteRendezvous, 下面展示了类图关系。
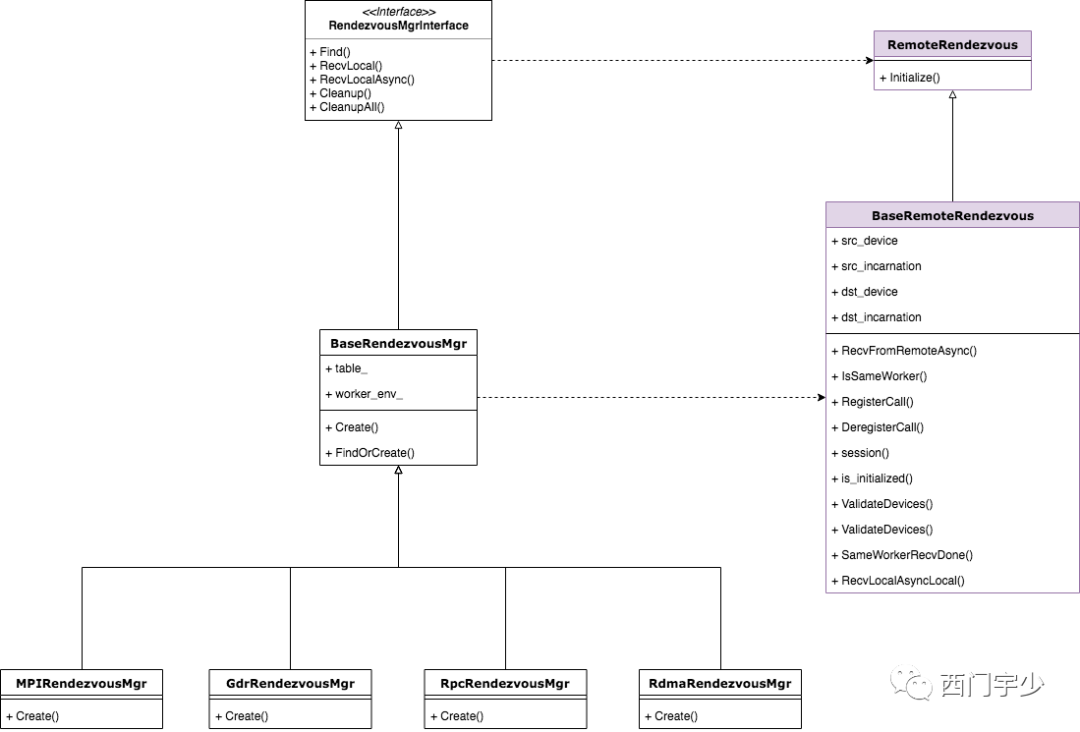
3. 令人熟悉的管理器模式——RendezvousMgr
为了更好地管理RemoteRendezvous,TensorFlow设计了相应的管理器——RendezvousMgr相关类,并为每种具体的RemoteRendevzous做了特化。
管理器是一种经典的设计模式,它能使管理职责的变化独立于类本身。RendezvousMgr主要负责RemoteRendezvous的创建和销毁,它也定义了两个本地版本的Recv接口。
下面是RendezvousMgr相关的类图结构,我们可以看到其接口类中已经定义了Recv接口,便于具体的Rendezvous直接重用。
4
RpcRemoteRendezvous通信过程
理解通信过程之前,我们先暂时对上文做一个简单地梳理,将重点内容梳理到以下几条:
本地Rendezvous和RemoteRendezvous共同继承了同一个接口;
RemoteRendezvous需要支持不同的通信协议,因此派生了各种各样的实现类;
RemoteRendezvous的使用较为复杂,为此引入了管理器模式——RendezvousMgr,它负责RemoteRendezvous的创建和销毁,并添加了两个额外的Recv接口方便某些场景直接调用。
至于gRPC部分,有以下几个重要的部分:
Rendezvous相关类——RemoteRendezvous,BaseRemoteRendezvous,RpcRemoteRendezvous;
管理器——BaseRendezvousMgr,RpcRendezvousMgr;
其他类——BaseRecvTensorCall,RpcRecvTensorCall和DefferedCall。
至此,结构清晰,分工明确,但看源码还是发现看不太懂。因为使用gRPC本身就是一件很复杂的事。这难点,还是在于gRPC本身的使用上。
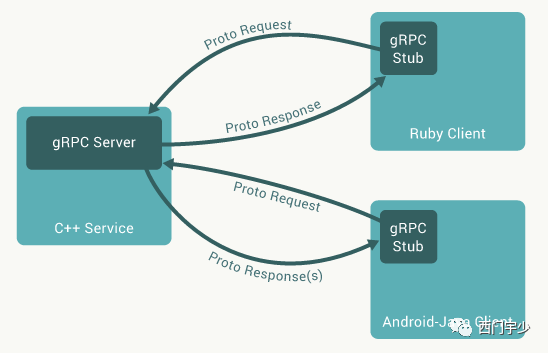
1. gRPC编程中的代理模式——Stub与Service
在一次RPC调用中,客户端需要调用服务端的服务,然后将处理结果返回给客户端。而gRPC做到了“让客户端调用远端函数时就像调用本地函数一样”的体验,这得益于一种经典的设计模式——代理模式。
负责为客户端代理的节点(gRPC中称之为Stub)会将请求和参数传到服务端,并由Service进行实际的处理,然后将结果返回给Stub,最终返回到客户端中。
我们甚至可以认为负责代理的Stub就是客户端,因为它的职责就是与远端交互并取得结果。另外,为了能够让传输量尽可能少,也为了能够让传输不受客户端和服务端具体的类型限制,gRPC在做跨网络传输前将消息统一序列化成Protobuf格式。下图是从gRPC官网教程中摘出的工作原理图。
2. Send过程
Send将Ready的Tensor挂入本地Table之中,所以它和LocalRendezvousImpl的Send完全相同。不仅如此,TensorFlow中的任何RemoteRendezvous的Send过程都要遵循这样的原理,基于代码复用的考虑,将这部分内容都被抽象到了公共基类BaseRemoteRendezvous的Send函数里是一个很好的设计。
事实上,BaseRemoteRendezvous的Send过程就是调用了LocalRendezvousImpl的Send过程,所以LocalRendezvousImpl必须要作为BaseRemoteRendezvous的成员之一。让我们稍微看以下这里面的代码。
Status BaseRemoteRendezvous::Send(const Rendezvous::ParsedKey& parsed,
const Rendezvous::Args& args,
const Tensor& val, const bool is_dead) {
VLOG(1) << "BaseRemoteRendezvous Send " << this << " " << parsed.FullKey();
{
mutex_lock l(mu_);
if (!status_.ok()) return status_;
DCHECK(is_initialized_locked());
if (!IsLocalDevice(session_->worker_name, parsed.src_device)) {
return errors::InvalidArgument(
"Invalid rendezvous key (src): ", parsed.FullKey(), " @ ",
session_->worker_name);
}
}
// Buffers "val" and "device_context" in local_.
return local_->Send(parsed, args, val, is_dead);
}复制
3. Recv过程
Recv过程就非常复杂了,因为每种RemoteRendezvous都涉及到不同的通信协议以及管理方式,所以Recv函数是真正需要继承重写的模块。在看RpcRemoteRendezvous具体的实现之前,我们必须先将gRPC定义服务的接口部分梳理清楚。
gRPC的服务定义接口文件
在TensorFlow的core/protobuf文件中,我们需要研究一下worker_service.proto文件,这个文件中定义了若干RPC Service接口。
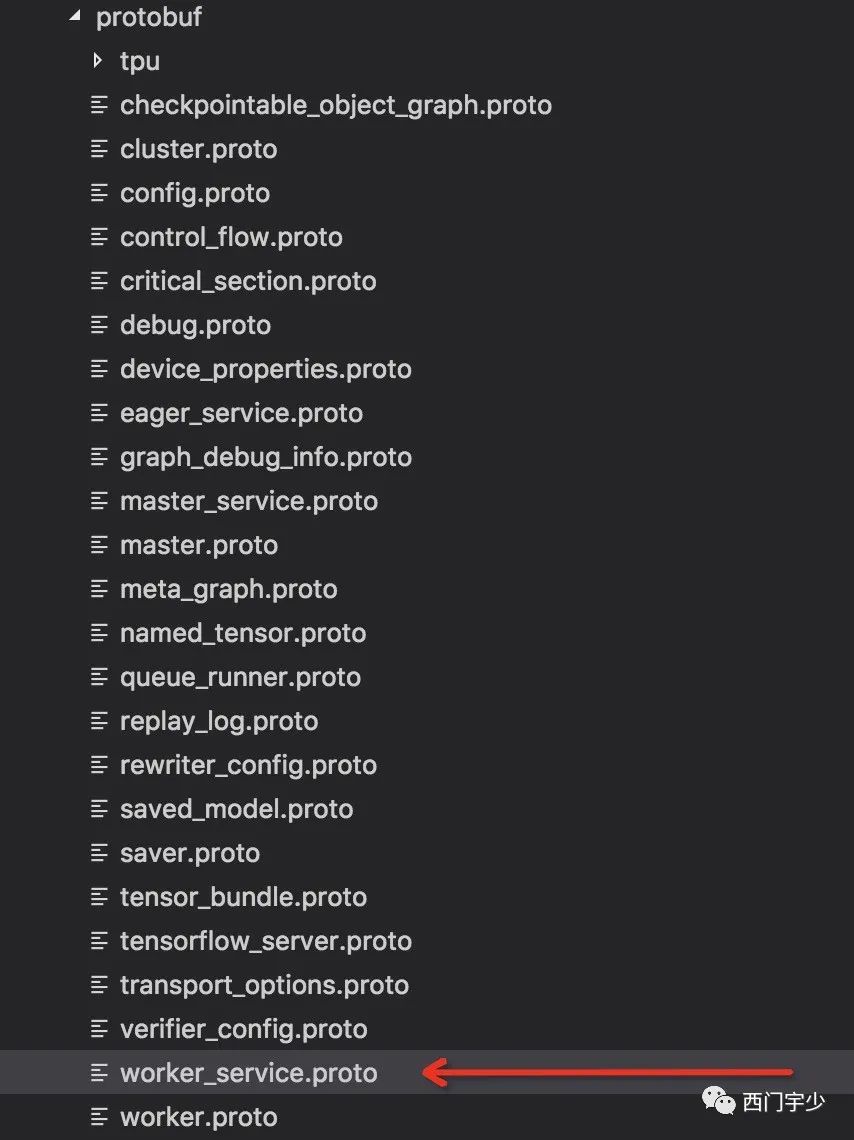
虽然它定义了很多RPC服务接口,但是我们只需要关注和Tensor接收相关的接口定义即可。准确地说,目前我们必须要知道的是下面这个Service定义。
// See worker.proto for details.
rpc RecvTensor(RecvTensorRequest) returns (RecvTensorResponse) {
// RecvTensor Method
}复制
显然,这是一个让服务端处理“接收Tensor”的服务(注意是让服务端处理名为“接收Tensor”的服务,而不是让服务端去接收Tensor。因为客户端有接收Tensor的需求,但需要服务端发送Tensor,为客户端发送Tensor的服务被称之为“接收Tensor”),按照注释提示,我们可以在worker.proto中找到RecvTensorRequest和RecvTensorResponse的数据结构。
在编译时,扩展的Protobuf编译器会对worker_service.proto中的rpc接口生成C++服务接口代码和Stub代码(毕竟Stub代码比较纯粹并且和业务逻辑无关,它只是一个向对应Service端发送处理请求的过程),TensorFlow只需要对具体的Service提供实现即可。
与gRPC生成的代码联系起来
gRPC会为worker_service.proto中每一个rpc服务生成C++接口代码,为了区分多个rpc服务,特意为每个服务生成了特殊的名字。比如RecvTensor服务的名字就是/tensorflow.WorkerService/RecvTensor。
为了不直接使用冗长的字符串,TensorFlow为worker_service.proto中的每个服务都做了enumeration的映射,这部分代码在tensorflow/core/distributed_runtime/grpc_worker_service_impl.h和同名实现文件中。
// Names of worker methods.
enum class GrpcWorkerMethod {
kGetStatus,
kCreateWorkerSession,
kDeleteWorkerSession,
kRegisterGraph,
kDeregisterGraph,
kRunGraph,
kCleanupGraph,
kCleanupAll,
kRecvTensor,
kRecvBuf,
kLogging,
kTracing,
kCompleteGroup,
kCompleteInstance,
kGetStepSequence,
};复制
然后,实现一个包含switch语句的函数,就可以将上述枚举类型转换成真正的服务名称。
RPC服务需要用户主动将其注册为异步服务。这需要使用gRPC自带的AddMethod接口和MarkMethodAsync接口,如下所示。
WorkerService::AsyncService::AsyncService() {
for (int i = 0; i < kGrpcNumWorkerMethods; ++i) {
AddMethod(new ::grpc::internal::RpcServiceMethod(
GrpcWorkerMethodName(static_cast<GrpcWorkerMethod>(i)),
::grpc::internal::RpcMethod::NORMAL_RPC, nullptr));
::grpc::Service::MarkMethodAsync(i);
}
}复制
好了,接下来就是解析源码中具体的交互过程了。
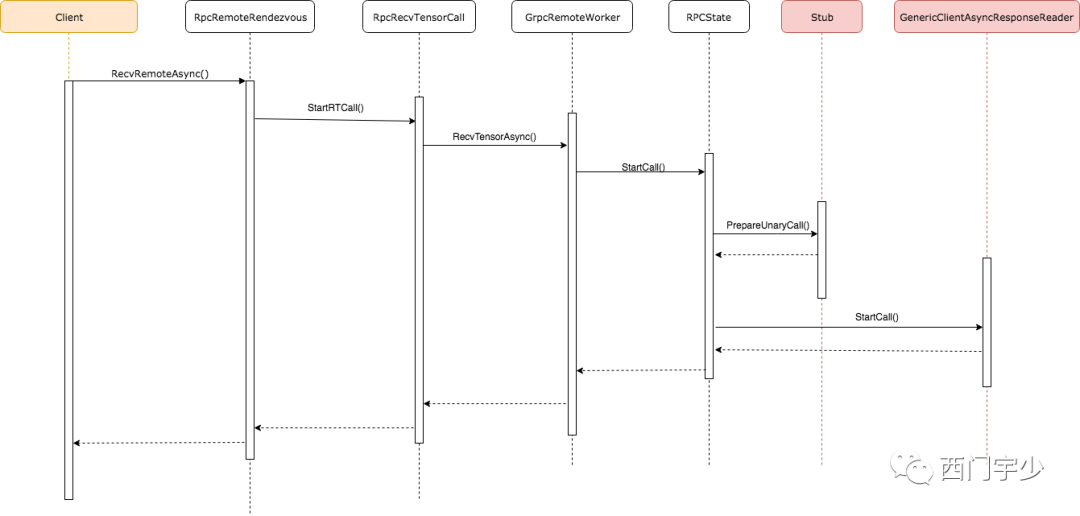
Client端的调用链
我们利用UML的时序图分析这一个多层封装的过程,如此冗长的过程其实理解起来挺噩梦的。但过程不重要,我们知道知道Client最终调用Stub代理即可。中间的层层封装其实是为了gRPC的复杂性而设计。
不过,还是提一下每个封装的作用:
1. RpcRecvTensorCall:这是一次gRPC调用的抽象,继承了BaseRecvTensorCall这个抽象基类,它封装了复杂的后续调用链。
2. GrpcRemoteWorker:它也是client端的内容,只不过它是Remote端的代理。
3. RpcState:这是真正封装了一次RPC调用及状态的类,它会直接对Stub以及GenericClientAsyncResponseReader进行管理,比如向服务端发送异步请求并等待结果等。
Server端负责查找Tensor的Service
下面的时序图展示了自Server端接收请求后的调用过程。和Client端理解方式相同,中间的层层封装不重要,重要的是request最终到达了真正的Service处理函数——GrpcWorker中,并将结果写回。
同样,我们也提一下每个封装的作用:
1. GrpcWorkerServiceThread:这是服务端处理请求的线程类。
2. GrpcWorker:这是真正负责处理请求的Worker,是GrpcRemoteWorker的服务端版本;
3. WorkerCall:这是服务端处理一次gRPC请求和响应的类,抽象为WorkerCall,其实这也是个别名,真实的名称较长;
4. ServerAsyncResponseWriter:这是gRPC为用户端提供的Response writer,是承载响应的实体;
5. Utils:这其实不是一个类,而是多个工具的组合,为了在时序图表达方便,统称为Utils。
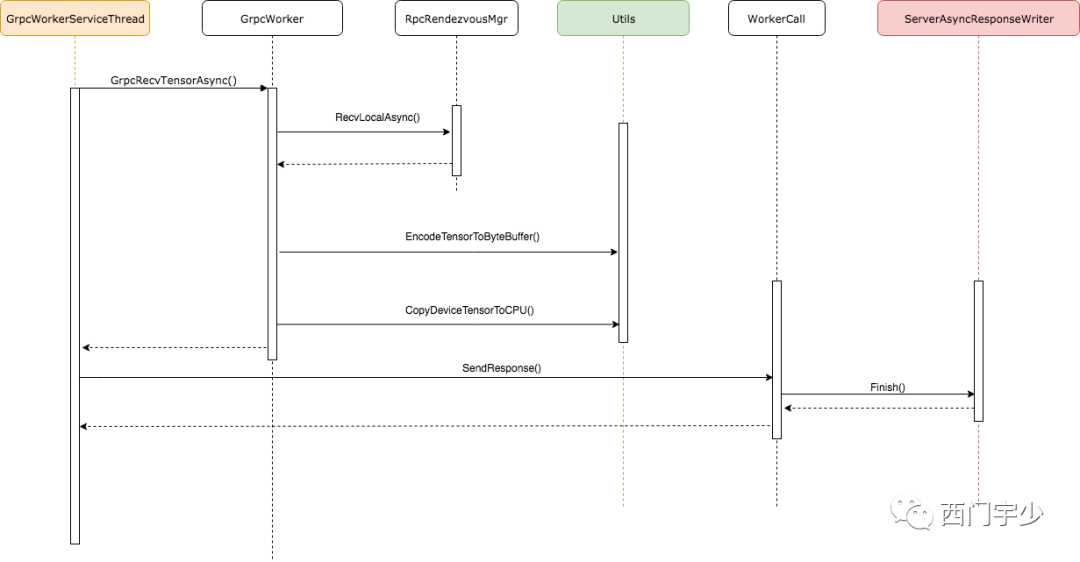
可以看出,服务端接收到请求后,会调用RecvLocalAsync在本地将客户端所需要的Tensor查找出来,然后拷贝到CPU上,最后利用gRPC发送回客户端。
5
问题思考——gRPC传输效率
我想,这是大多数人关心的问题,结果可能也确实让你们失望。
没错,慢。
从设计哲学上说,gRPC本身设计并不适合深度学习训练场景,原因如下:
无意义的压缩序列化。在Tensor很大的时候这是一个非常讨厌的overhead,发送接收延迟过大;
不能支持RDMA和GPU Direct。虽然这依赖于硬件,但是gRPC在软件层面也并没有做这些适配。
其他实现层面的原因。
问题是,你能优化改进吗?还是说,换一个通信协议会更好?虽然不同人各有各的观点,但工作量确实真都不小。
6
总结
本篇文章篇幅较长,是Rendezvous机制系列的第二篇,主要梳理了涉及到gRPC传输的模块架构设计和源码细节,并且详细梳理了通信过程。
理解TensorFlow跨机传输的关键在于理解一个事实:真正的通信过程由Recv方触发,而不是Send方!Send依然将Ready的Tensor挂入本地Table中,而Recv会向Send端发送gRPC请求查询所需要的Tensor,然后返回所需要的结果,这个过程虽然有些别扭,但逻辑上并不稀奇。
从结构设计上来说,RemoteRendezvous沿用了Rendezvous接口,并且完全复用了LocalRendezvousImpl的Send代码,而Recv由于涉及到具体的通信细节和管理机制,则各有各的不同。另外,RemoteRendezvous相对LocalRendezvous复杂很多,需要管理器进行管理。
我们还简单梳理了Client与Server的交互过程,虽然调用链较深,封装较复杂,但依旧能剥开它们,看到Client->Stub->GrpcWorker的过程。切记,不要被封装牵着鼻子走。
最后,我们总结了gRPC传输Tensor的明显缺陷,为性能优化开辟了新的空间。
讲技术,也谈风月,更关注程序员的生活状况,欢迎联系二少投稿你感兴趣的话题。
