排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
首页
/
【机器学习系列】强化学习 & 集成学习
【机器学习系列】强化学习 & 集成学习
火火日记
2019-10-12
2157
通过前两篇文章,我给大家介绍了传统机器学习的内容。
今天咱们来聊聊最近备受瞩目的强化学习和集成学习。
强化学习
百度百科中的解释为“描述和解决智能体(Agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题”,其本质是为了实现自动决策。
强化学习4大要素:Agent、Environment、Action、Reward
主要应用于:
– 自动驾驶汽车
– 扫地机器人
– 游戏
– 自动交易
– 企业资源管理
常见算法:Q-Learning,SARSA,DQN,A3C,遗传算法等
为方便大家理解4要素的概念,我们来举个马里奥的例子。
首先马里奥不是由我们操控,而是通过强化学习的模型自动进行游戏。
这里马里奥就是Agent,游戏中的各种障碍物、下水道、怪物就是马里奥所处的环境(Environment),而马里奥需要通过跳跃不断躲避障碍并到达终点,所以这里的跳跃就是行动(Action)。那么这里Reward是什么呢?当马里奥成功躲避障碍时给他加1分,躲避障碍物失败而触碰到怪物时给他减1分,以此类推当他操作得当时加分,操作不当时减分。最终的目标是通过最大得分完成游戏,即获得最大回报(Reward)。
自动驾驶、扫地机器人等都会用到强化学习。
强化学习,貌似看起来有点像我们所认知的人工智能了...
其实强化学习所解决的问题与数据无关,为什么这么说呢?
以自动驾驶为例,即使我们了解世界上所有的道路规则,也没有办法教会汽车自动驾驶。无论我们收集了多少数据,我们仍然无法预见所有可能的情况。这就是为什么强化学习的目标是最小化错误,而不是预测所有的移动。
在环境中生存是强化学习的核心理念。就好比在教育小孩子一样,当他做对了就给他奖励,当他做错了就给他惩罚。
这里其实还有一个更有效的方法,就是建立一个虚拟城市,让自动驾驶汽车首先学习它的所有技巧。这正是我们现在训练自动驾驶的一种方式。
建立一个基于真实地图的虚拟城市,汽车与行人一起在道路上行走,让汽车学会尽可能少的撞到行人的次数。当机器人对这种人工GTA有相当的信心时,它就可以在真实的街道上进行测试。
这里又分为两种不同的训练方法,一种是基于模型的训练,另一种是无模型训练。
1. 基于模型意味着汽车需要记住地图。这是一个非常过时的方法,因为这辆自动驾驶汽车不可能记住整个星球。
2. 在无模型学习中,汽车不会记住每一个动作,而是试图评估环境并合理地做出行动,同时获得最大的奖励。
大家可能还记得
AlphaGo
成功击败世界顶级象棋选手李世石的新闻。下象棋有太多太多组合的下法,而机器也无法记住所有的组合。在每个回合中,它只是为每种情况选择了最佳动作。
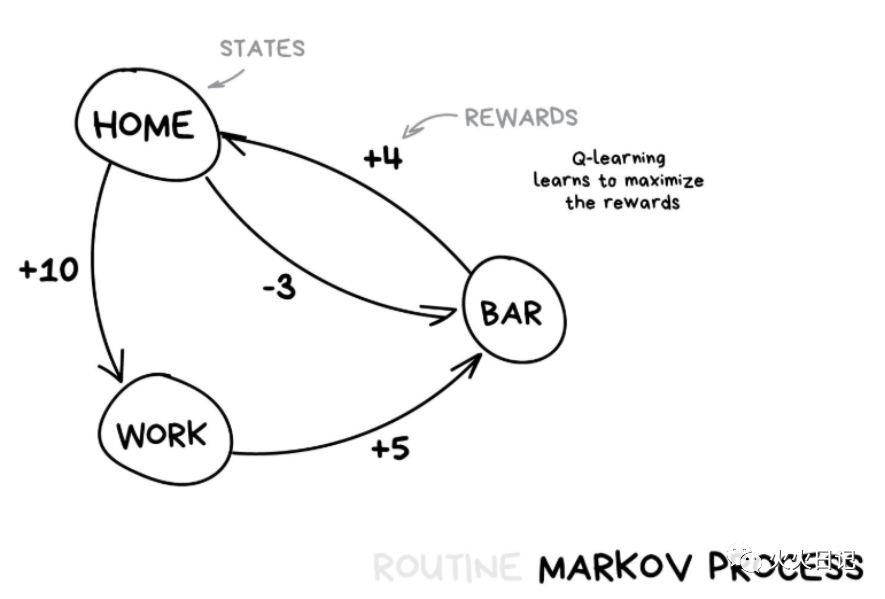
这种方法就是Q-learning,以及其衍生算法SARSA和DQN背后的核心概念。这里的“Q”代表的是质量,因为机器需要学会在每种情况下执行最“定性”的操作,并且所有情况都会被记忆(马尔可夫过程)。
就像这样,机器可以在虚拟环境中测试数十亿个情况,记住哪些解决方案带来了更大的回报。但是,它如何区分以前看到的情况和全新的情况呢?如果一辆自动驾驶汽车在过马路时信号灯变绿了,那么,这是否就意味着现在可以行驶?如果有救护车冲过附近的街道怎么办?
对普通人来说,强化学习看起来像是真正的人工智能。因为它让你觉得,这是机器在现实生活中自己做出了决定!而不是人为的干预。
近几年强化学习被大肆宣传,并且它以非常惊人的速度在发展,并与神经网络不断交叉结合使用...
集成学习
百度百科中的解释为,集成学习(ensemble learning)是通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)。
主要应用于:
– 适用于所有传统机器学习方法(效果更佳)
– 搜索系统
– 计算机视觉
– 物体检测
常见算法:随机森林,梯度提升等
现如今集成学习和神经网络作为机器学习领域提升模型准确度的非常有效的方法,广泛用于生产。
相比神经网络的概念铺天盖地,集成学习中的Bagging、Boosting、Stacking等概念却很少被人提及。集成学习背后的想法其实很简单,就是利用一些相对效率比较低下的算法,使他们相互纠正彼此的错误,就好比“少数服从多数”,使得系统整体的模型质量高于任何单个算法的结果。
3种集成学习方法
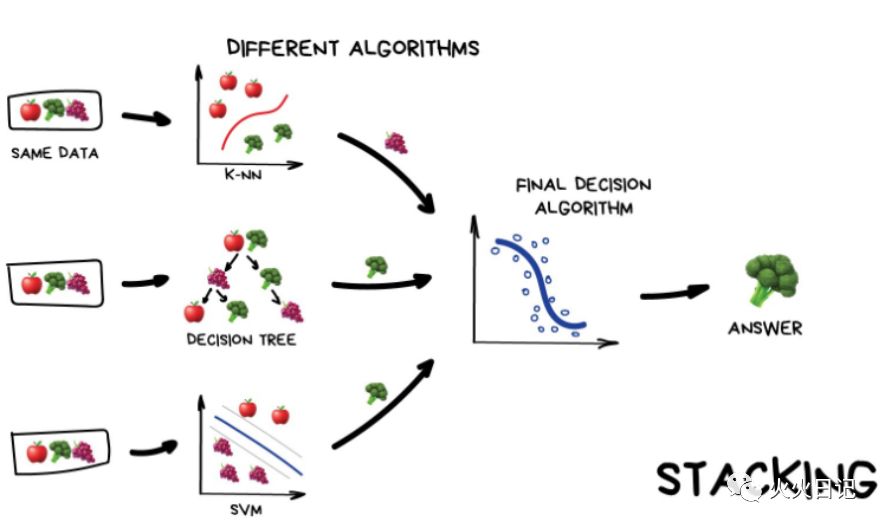
1. Stacking
Stacking是通过一个元分类器或者元回归器来整合多个分类模型或回归模型的集成学习技术。基础模型利用整个训练集做训练,元模型将基础模型的特征作为特征进行训练。
简单来讲就是
几个并行模型的输出作为输入传递给最后一个,做出最终决定。就好比你在约一个女孩子吃饭,那个女孩子不知道自己该不该出来和你吃饭,于是她就找好几个闺蜜询问是否应该与你见面,以便自己做出最终决定。
这里强调“不同”这个词。在相同的数据上并行相同的算法是没有意义的。 而具体选择何种算法,完全取决于个人。 但是,对于最终决策模型,回归通常是一个不错的选择。
通常情况下Stacking在实践中不太受欢迎,因为另外两种方法提供了更好的准确性。
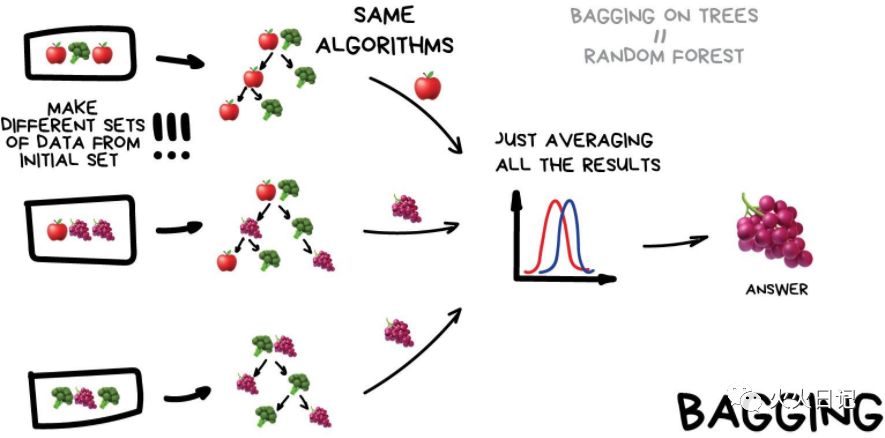
2. Bagging
Bagging是在原始数据的不同数据子集上,使用相同的算法进行训练。最后寻求平均值。
当然随机子集中的数据可能会有重复。例如,从“1-2-3”这样的集合中我们可以得到像“2-2-3”,“1-2-2”,“3-1-2”等子集。我们在这种新数据集中,运用相同的算法,然后通过简单的投票方式预测最终答案。
Bagging最著名的例子是随机森林算法,相当于在决策树上做了Bagging(如上图)。比如当你打开手机的拍照功能时,你可以看到人脸周围有矩形框(如下图),这可能就是随机森林处理的结果。神经网络比较慢,所以无法实时运行,而Bagging就可以做到。
在某些任务中,Bagging的并行运行能力要比Boosting的精度损失更为重要。特别是在实时处理中。这些都需要权衡。
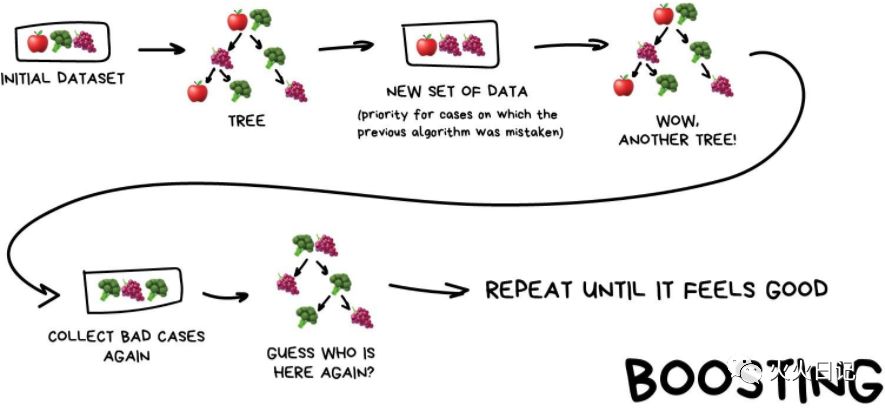
3. Boosting
Boosting指的是通过算法集合将弱学习器转换为强学习器。boosting的主要原则是训练一系列的弱学习器,所谓弱学习器是指仅比随机猜测好一点点的模型,例如较小的决策树,训练的方式是利用加权的数据。
简单来讲,Boosting算法按顺序逐个训练。随后的每一个学习器都将其大部分注意力集中在前一个错误预测的数据点上。 一直重复,直到符合你的要求。
与Bagging相同,Boosting也会使用数据集合的子集,但这次它们不是随机生成的。 然后在每个子集中,我们采用先前算法未能处理的部分数据。因此,新的算法会修复上一个算法的错误。
今天就到这里,下期咱们接着聊聊神经网络和深度学习
机器学习
文章转载自
火火日记
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
热门文章
基于K8s的机器学习工作流框架-Kubeflow
2019-11-10
2169浏览
【机器学习系列】传统机器学习-监督学习
2019-09-22
1886浏览
AWS开源AutoML 库AutoGluon入门
2020-10-26
1727浏览
Oracle DB实时分析之OGG+Kafka架构(第二弹)
2020-11-10
1332浏览
基于Oracle Streaming Service的IoT数据实时分析(第三弹)
2020-02-28
945浏览
领墨值
有奖问卷
意见反馈
客服小墨