




上周我们完成了MQTT Broker到 Streaming Service这部分数据的打通,今天就把数据加载到ADW(Autonomous Data Warehouse)进行预测模型的搭建,以及前端实时分析可视化界面的展示。
kafka-connect-mqtt 部署(已完成)
Streaming Service 部署(已完成)
Oracle Kubernetes Engine 部署(已完成)
OKE中部署Docker(已完成)
Hive MQ 部署(本期进行)
Stream数据加载ADW(本期进行)
ADW数据加工及机器学习模型搭建(本期进行)
OAC前端可视化界面开发(本期进行)
从架构图上来看,就是要实现下面红框这一部分。
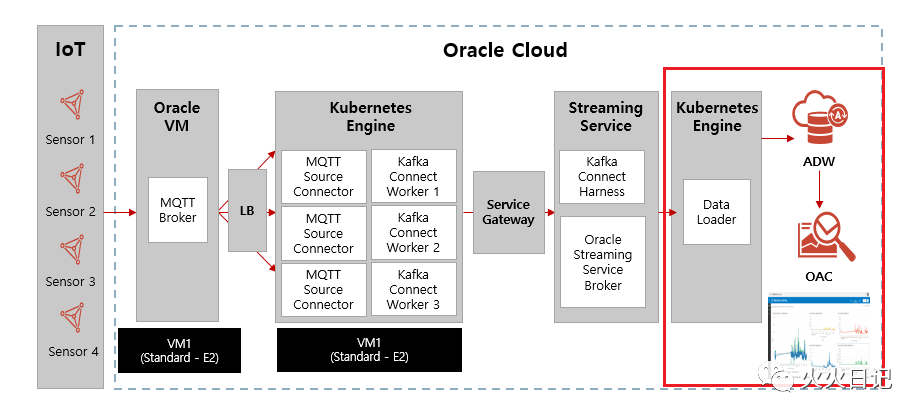
好,咱们开始!
Hive MQ 部署
本步骤中我们搭建Hive MQ服务来模拟客户生产环境,代替客户的MQTTBroker进行数据的实时分发
1. 部署 Hive MQ
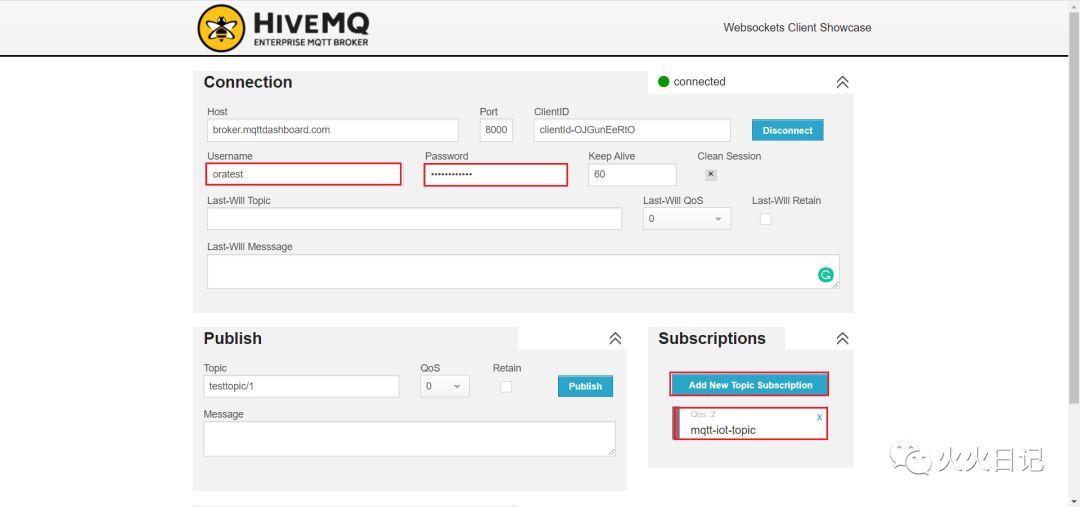
如下图,需要在Websockets Client中生成,Connection。然后单击Add New Topic Subscription生成“mqtt-iot-topic” Topic。
2. 配置 Kafka Connect
# Make a Directorymkdir -p connect-clicd connect-cli# Download the CLIwget https://github.com/lensesio/kafka-connect-tools/releases/download/v1.0.6/connect-cli# Prepare Environment# Load-Balancer-Public-IP:kubectl get svc复制

# 拷贝上述 EXTERNAL-IP130.61.197.91export KAFKA_CONNECT_REST="http://<Load-Balancer-Public-IP>"复制
3. 创建Connect Config
创建mqtt-source.propeties 文件,并把如下代码复制进去
name=mqtt-sourceconnector.class=com.datamountaineer.streamreactor.connect.mqtt.source.MqttSourceConnectortasks.max=3topics=iot-topic-streamconnect.mqtt.clean=trueconnect.mqtt.timeout=1000connect.mqtt.kcql=INSERT INTO iot-topic-stream SELECT * FROM mqtt-iot-topic WITHCONVERTER=`com.datamountaineer.streamreactor.connectconnect.mqtt.keep.alive=1000connect.mqtt.converter.throw.on.error=trueconnect.mqtt.hosts=tcp://broker.hivemq.com:1883connect.mqtt.service.quality=1connect.progress.enabled=true复制
设置环境
# connect-cli 权限chmod 755 connect-cli# 安装 Javasudo yum install jre复制
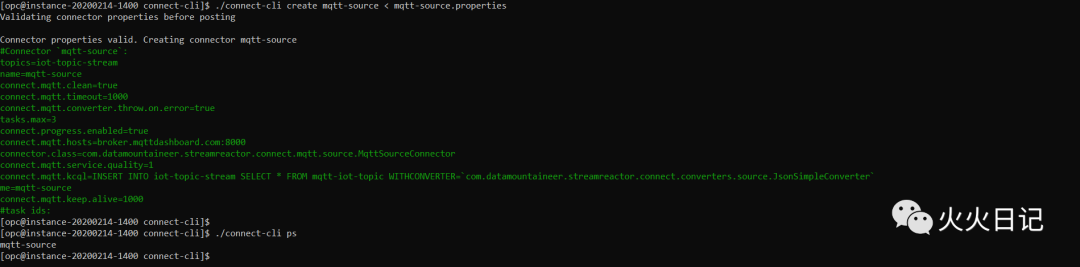
创建Connector,并确认状态
./connect-cli create mqtt-source < mqtt-source.properties./connect-cli ps复制
# mqtt-source 状态确认./connect-cli status mqtt-sourceconnectorState: RUNNINGworkerId: 10.244.0.12:8083numberOfTasks: 1tasks:- taskId: 0taskState: RUNNINGworkerId: 10.244.0.12:8083# 删除命令(必要时进行删除)./connect-cli rm mqtt-source复制

4. MQTT Data Generator
安装PIP
sudo easy_install pip复制
安装 paho-mqtt
sudo pip install paho-mqtt复制
# MQTT-Generator 代码下载# git 未安装时需要进行安装> sudo yum install -y gitgit clone https://github.com/ufthelp/MQTT-Generator.git# 确认 configcat config.json复制
修改Config文件

生成数据
python mqttgen.py 10 1 1复制
在Hive MQ中确认数据
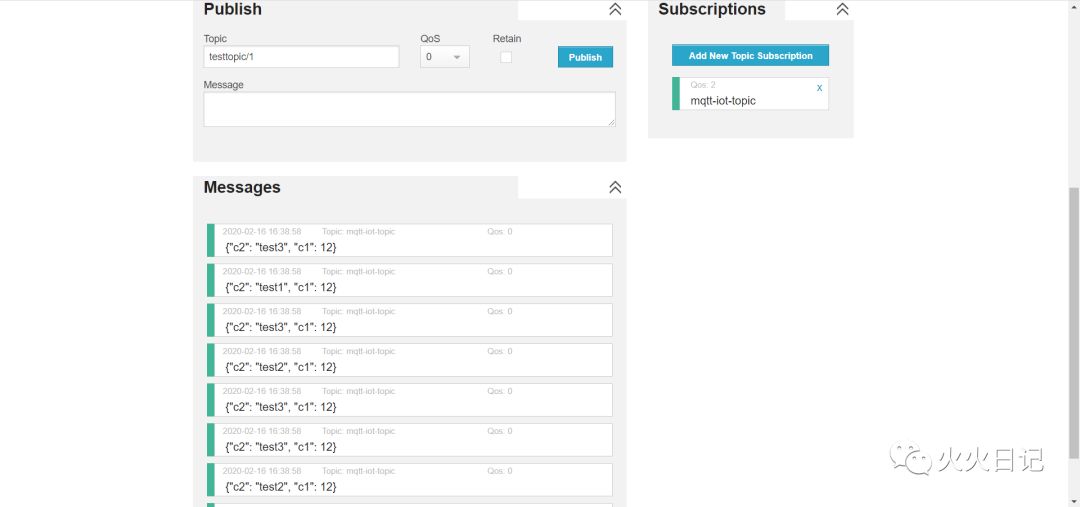
在Streaming Pool中确认实时数据。如下图,数据已成功写进Streaming中
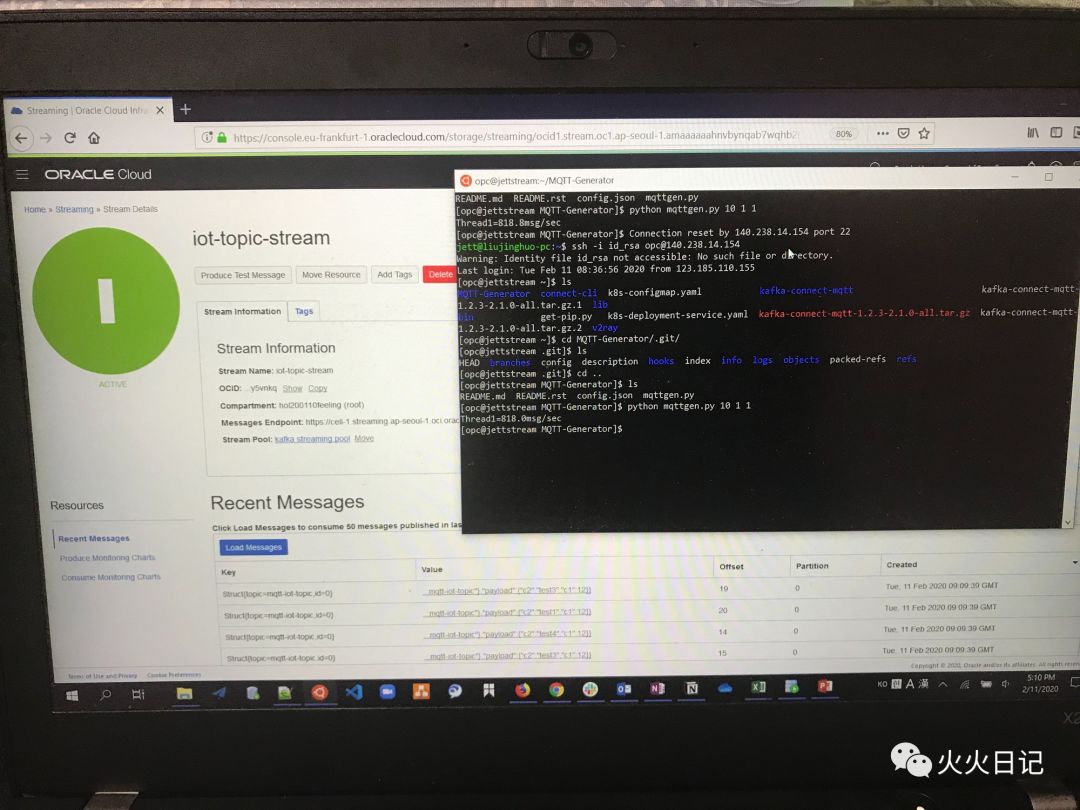
Streaming数据加载到ADW
1. 上传ADW Wallet到 Connector Container
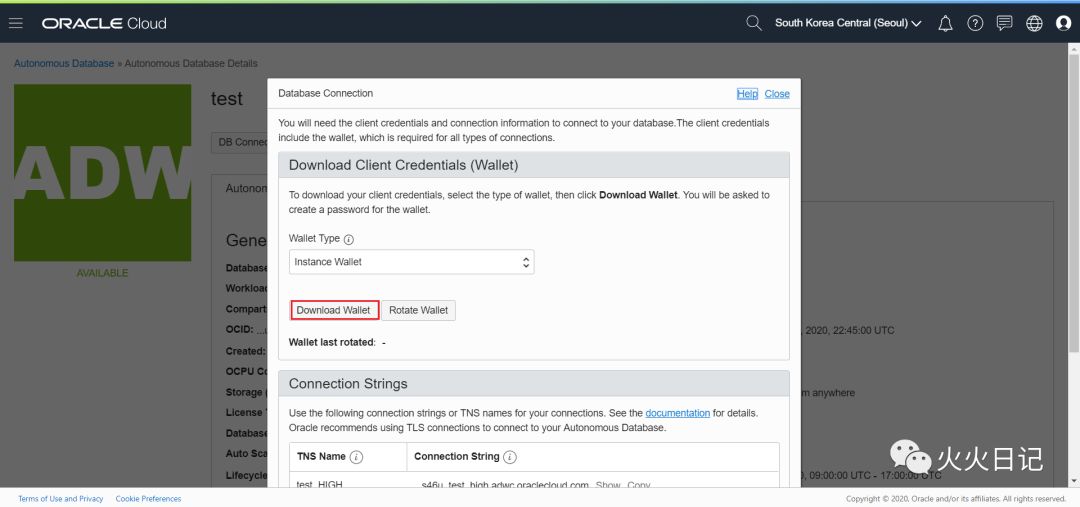
下载ADW Wallet
路径:OCI Menu → Autonomous Database → 选择Database → DB Connection,选择下载DB Wallet
利用SCP本机的Wallet文件上传到VM中
scp Wallet_test.zip opc@140.238.14.154:~复制
把ADW Wallet Zip文件解压缩,放到/oracle_credentials_wallet目录中
sudo suwallet_unzipped_folder=/oracle_credentials_walletmkdir -p $wallet_unzipped_folderunzip -u /Wallet_test.zip -d $wallet_unzipped_folder复制
把Wallet从Oracle VM,上传到Kafka Connect nodes
docker cp oracle_credentials_wallet 0a7e6a8b8bcc:/oracle_credentials_wallet复制
执行Container,确认Wallet上传情况
docker start 0a7e6a8b8bccdocker exec -it 0a7e6a8b8bcc /bin/bash复制

2. 安装Kafka jdbc-connercotor
执行Container,确认jdbc-connercotor安装情况
docker start 0a7e6a8b8bccdocker exec -it 0a7e6a8b8bcc /bin/bash复制
确认 /usr/share/java/kafka-connect-jdbc 目录,发现已安装

如果未安装jdbc-connercoter时,需要安装
confluent-hub install confluentinc/kafka-connect-jdbc:5.4.0复制
3. 安装ODBC Driver
如下下载文件后,复制到 /usr/share/java/kafka-connect-jdbc 目录
wget https://objectstorage.us-phoenix-1.oraclecloud.com/n/intmahesht/b/oracledrivers/o/ojdbc8-full.tar.gztar xvzf ./ojdbc8-full.tar.gzcp ojdbc8-full/ojdbc8.jar /usr/share/java/kafka-connect-jdbcrm -rf ojdbc8-fullrm -rf ojdbc8-full.tar.g复制
4. Docker Image上传
执行如下代码,把刚刚修改的Docker文件,重新上传的到之前的Oracle Registry中,版本设定为0.2
docker login icn.ocir.iousername:frvvnnkmcble/oracleidentitycloudservice/alvin.jin@oracle.compassword(Authtoken):xZ<cXf>#89)pl{Mt5#gwdocker commit 0a7e6a8b8bcc icn.ocir.io/frvvnnkmcble/kafka-connect-mqtt/kafka-connect:0.2docker push icn.ocir.io/frvvnnkmcble/kafka-connect-mqtt/kafka-connect:0.2复制
connect-cli 目录中生成 jdbc-adw.properties文件,并把如下代码拷贝进去
name=jdbc-adwconnector.class=io.confluent.connect.jdbc.JdbcSinkConnectortasks.max=1topics=iot-topic-streamconnection.url=jdbc:oracle:thin:@DBkafka_HIGH?TNS_ADMIN=/oracle_credentials_walletconnection.user=ADMINconnection.password=QWERasdf1234auto.create=true复制
参照4. OKE中部署Docker步骤,删除Pod后,基于刚刚生成的0.2版本Image,重新部署Docker
ADW数据加工及机器学习模型搭建
在ADW中可以对IoT数据进行多维度的数据分析,本步骤中主要介绍如何利用指数平滑法进行时间序列预测
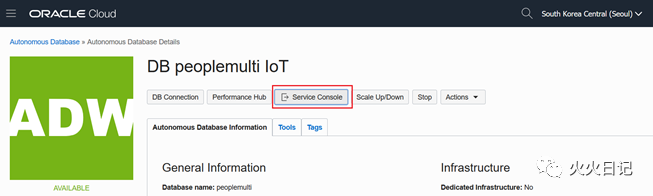
1. 登陆OML Notebook
路径:OCI Menu → Autonomous Database → 选择Database → Service Console
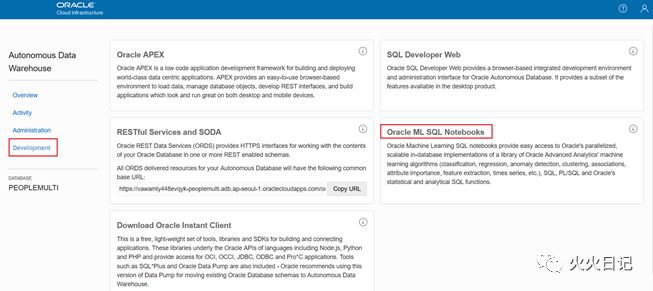
Development中选择 ML SQL Notebook
选择Notebook
创建Notebook
2. 预测模型
创建训练数据集
%script-- Drop Previous Training TableBEGINEXECUTE IMMEDIATE 'DROP TABLE ML_AIRDATA';EXCEPTIONWHEN OTHERS THEN NULL;END;/create table ML_AIRDATAas select a.sn, a.radon, a.co2, a.dust10, a.temperature, a.humidity, a.air_station_time, substr(a.air_station_time,1,15) time_id, b.hospital_no from admin.air_station a left join admin.air_station_master b on a.sn = b.sn;select * from ml_airdata;复制
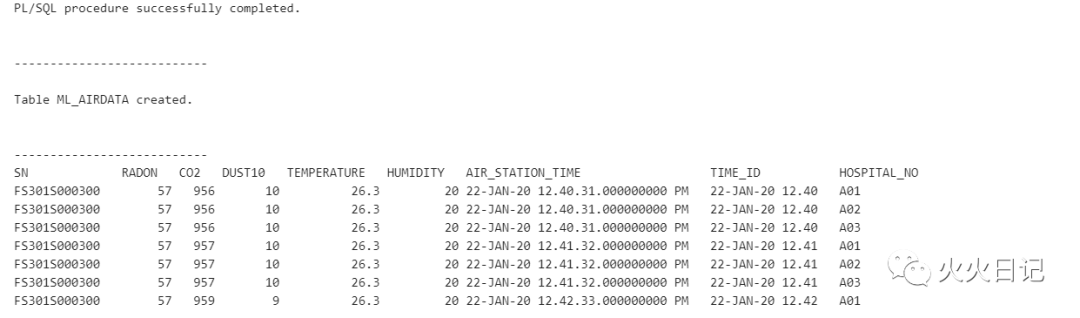
创建模型及配置模型参数
%script-- Cleanup old settings tableBEGIN EXECUTE IMMEDIATE 'DROP TABLE esm_radon_settings';EXCEPTION WHEN OTHERS THEN NULL; END;/-- Cleanup old model with the same nameBEGIN DBMS_DATA_MINING.DROP_MODEL('ESM_RADON_SAMPLE');EXCEPTION WHEN OTHERS THEN NULL; END;/-- Create input time seriesCREATE OR REPLACE VIEW ESM_RADON_DATAAS SELECT AIR_STATION_TIME, RADONFROM ML_AIRDATA where sn = 'FS301S000300';CREATE TABLE ESM_RADON_SETTINGS(SETTING_NAME VARCHAR2(30),SETTING_VALUE VARCHAR2(128));BEGIN-- Select ESM as the algorithmINSERT INTO ESM_RADON_SETTINGSVALUES(DBMS_DATA_MINING.ALGO_NAME,DBMS_DATA_MINING.ALGO_EXPONENTIAL_SMOOTHING);-- Set accumulation interval to be minuteINSERT INTO ESM_RADON_SETTINGSVALUES(DBMS_DATA_MINING.EXSM_INTERVAL,DBMS_DATA_MINING.EXSM_INTERVAL_MIN);-- Set prediction step to be 30 minutes (half hour)INSERT INTO ESM_RADON_SETTINGSVALUES(DBMS_DATA_MINING.EXSM_PREDICTION_STEP,'30');-- Set ESM model to be Holt-WintersINSERT INTO ESM_RADON_SETTINGSVALUES(DBMS_DATA_MINING.EXSM_MODEL,DBMS_DATA_MINING.EXSM_HW);-- Set seasonal cycle to be 4INSERT INTO ESM_RADON_SETTINGSVALUES(DBMS_DATA_MINING.EXSM_SEASONALITY,'4');END;/-- Build the Exponential Smotthing (ESM) modelBEGINDBMS_DATA_MINING.CREATE_MODEL(MODEL_NAME => 'ESM_RADON_SAMPLE',MINING_FUNCTION => 'TIME_SERIES',DATA_TABLE_NAME => 'ESM_RADON_DATA',CASE_ID_COLUMN_NAME => 'AIR_STATION_TIME',TARGET_COLUMN_NAME => 'RADON',SETTINGS_TABLE_NAME => 'ESM_RADON_SETTINGS');END;/复制
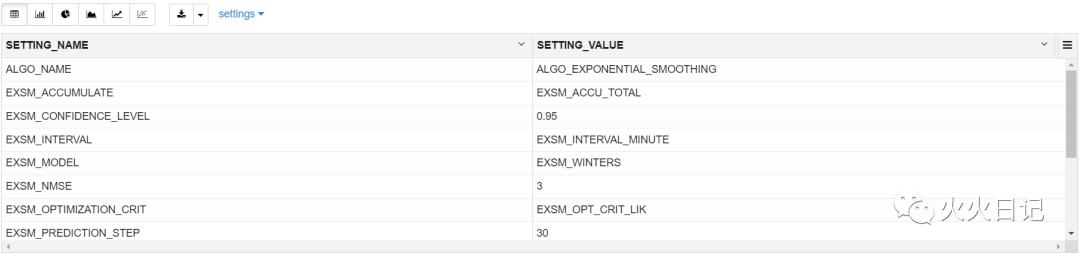
模型参数确认
%sql-- output setting tableSELECT SETTING_NAME, SETTING_VALUEFROM USER_MINING_MODEL_SETTINGSWHERE MODEL_NAME = UPPER('ESM_RADON_SAMPLE')ORDER BY SETTING_NAME;复制
模型质量确认
%sql-- get global diagnosticsSELECT NAME,NUMERIC_VALUE,STRING_VALUEFROM DM$VGESM_RADON_SAMPLEORDER BY NAME;复制
预测结果确认
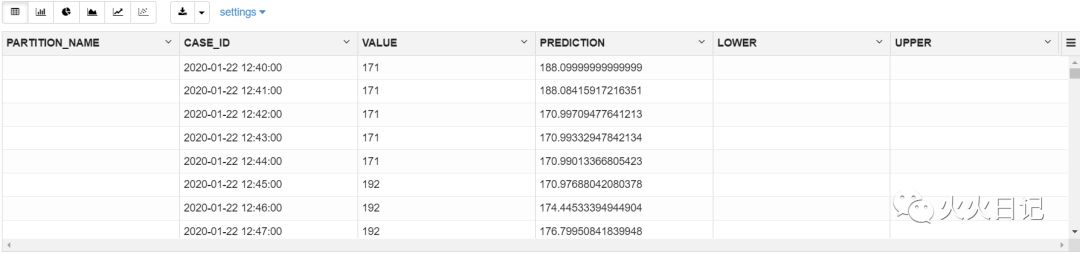
%sqlSELECT * FROM JETT.DM$VPESM_RADON_SAMPLE;复制
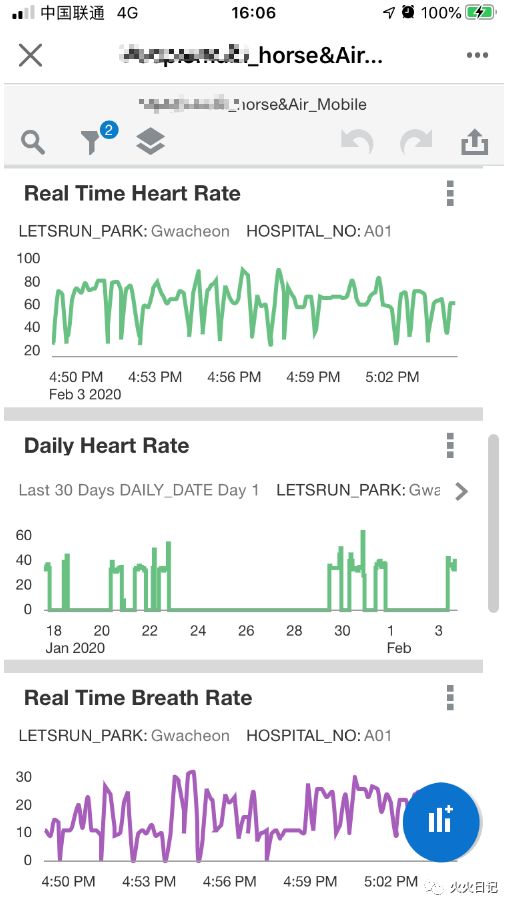
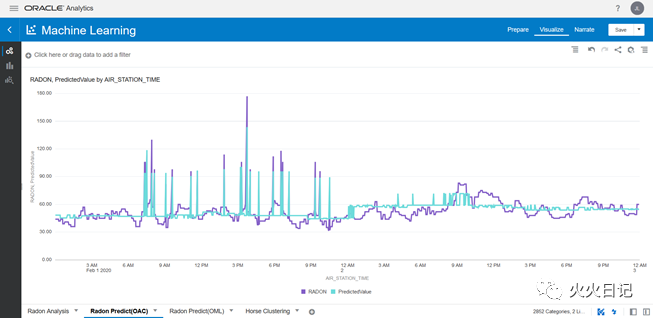
OAC前端可视化界面开发
PC端

移动端
时间序列预测结果
好了,到这里IoT实时数据分析做完了!
基于云端的实时分析方案,从架构到部署,涉及的内容比较多,我们来总结下!
首先我们在k8s集群上搭建了kafka-connect-mqtt环境,将基于C环境的IoT数据实时接入Streaming Service(流处理)。
然后把数据实时写入ADW(Autonomouse Data Warehouse),并进行机器学习预测。
最后在OAC(Oracle Analytics Cloud)上搭建了实时可视化界面。
