




继上周OGG+Kafka架构内容,本周继续完成后半部分(7~11)的开发内容。
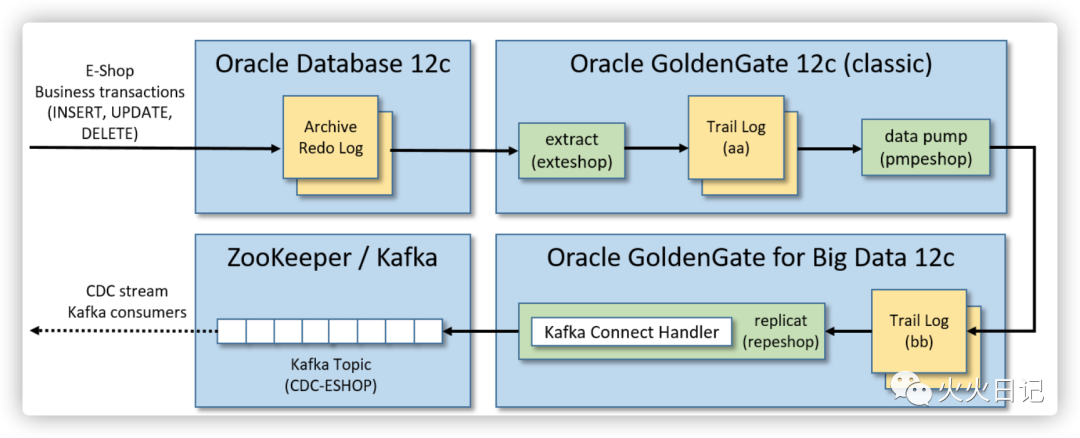
系统架构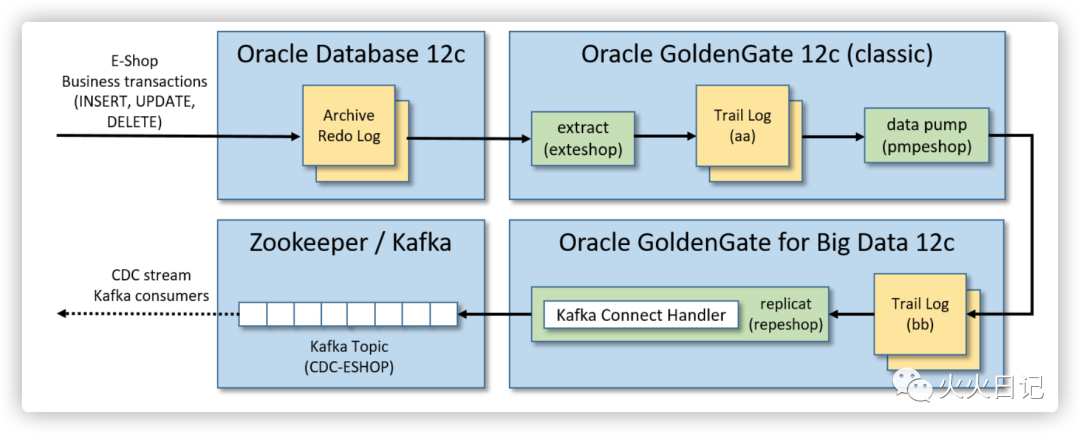
开发流程
启动Oracle数据库
Oracle数据库启用归档日志
创建ggadmin用户
创建ESHOP Schema
初始化GoldenGate Classic
创建GoldenGate Extract
安装并运行Apache Kafka
安装GoldenGate for Big Data
启动GoldenGate for Big Data Manager
创建Data Pump
将事务发布到Kafka
7. 安装并运行Apache Kafka
在这一步骤,我们将完成整体架构中如下部分的工作
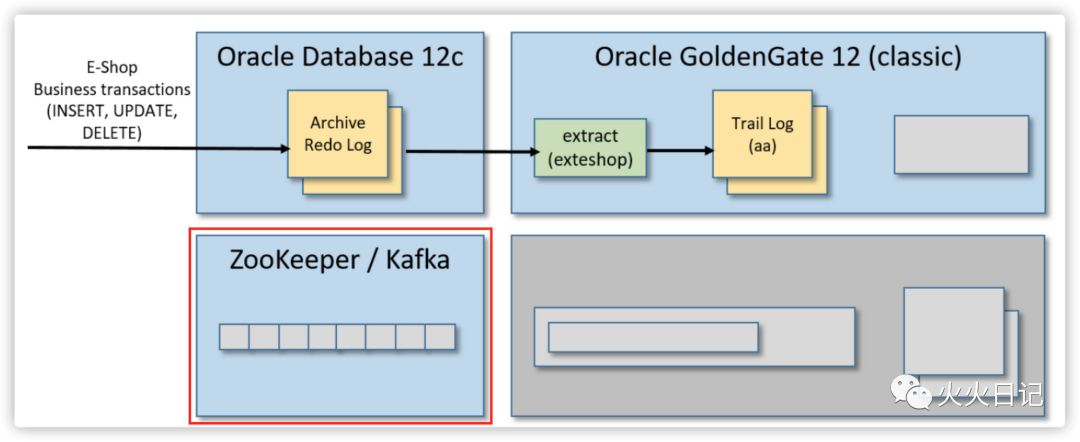
首先从虚拟机的桌面环境中打开Firefox并下载Apache Kafka(kafka_2.11-2.1.1.tgz)
https://kafka.apache.org/downloads
然后打开一个Linux shell并重置CLASSPATH环境变量(在BigDataLite-4.11虚拟机中设置的当前值会和Kafka产生冲突)
declare -x CLASSPATH=""复制
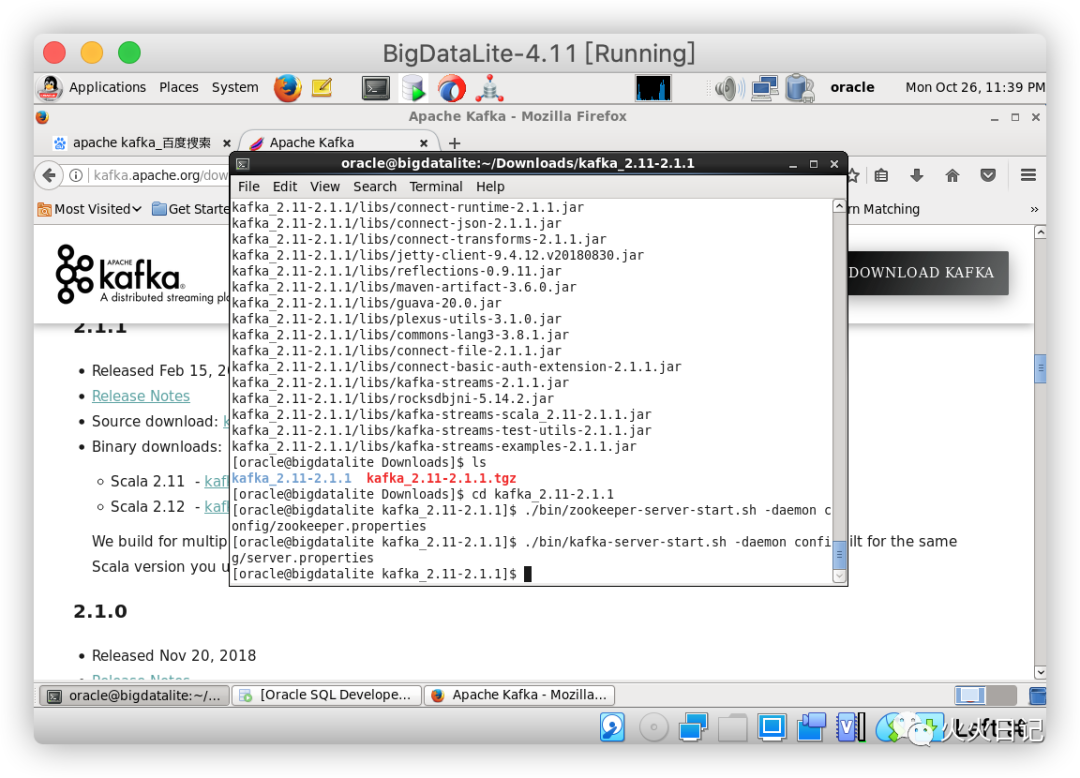
切换到Download目录后,解压缩压缩包,启动ZooKeeper和Kafka
cd ~/Downloadstar zxvf kafka_2.11-2.1.1.tgzcd kafka_2.11-2.1.1./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties./bin/kafka-server-start.sh -daemon config/server.properties复制
我们可以通过启动echo stats | nc localhost 2181来检查ZooKeeper是否正常
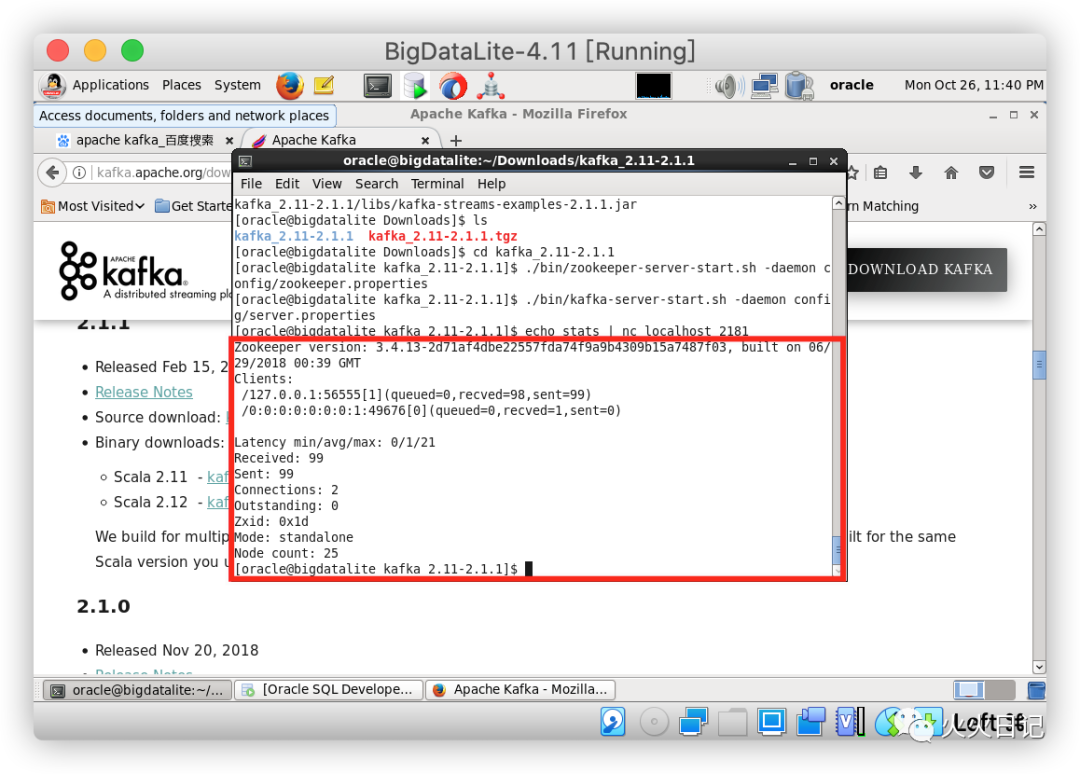
我们也可以通过echo dump | nc localhost 2181 | grep brokers来判断Kafka是否正常启动
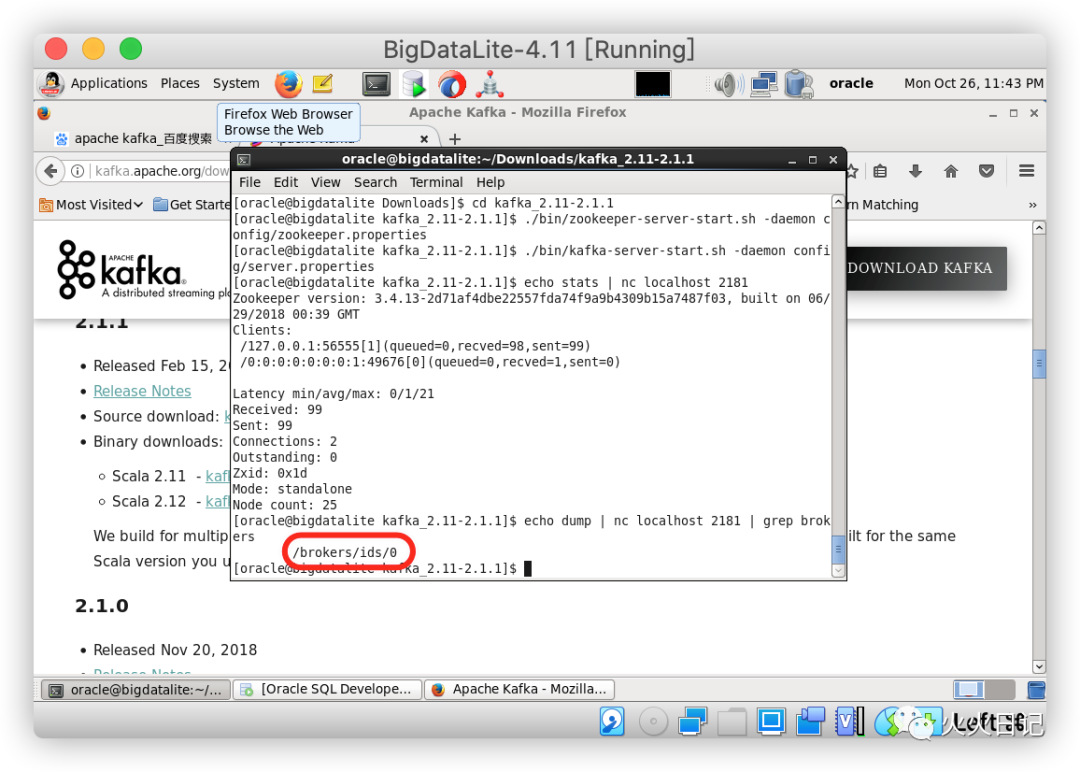
8. 安装GoldenGate for Big Data
同理在这一部分,我们需要通过虚拟机的火狐浏览器下载Oracle GoldenGate for Big Data 12c(Oracle GoldenGate for Big Data 12.3.2.1.0),下载时需要Oracle帐户(免费)
https://www.oracle.com/cn/database/technology/goldengate-downloads.html
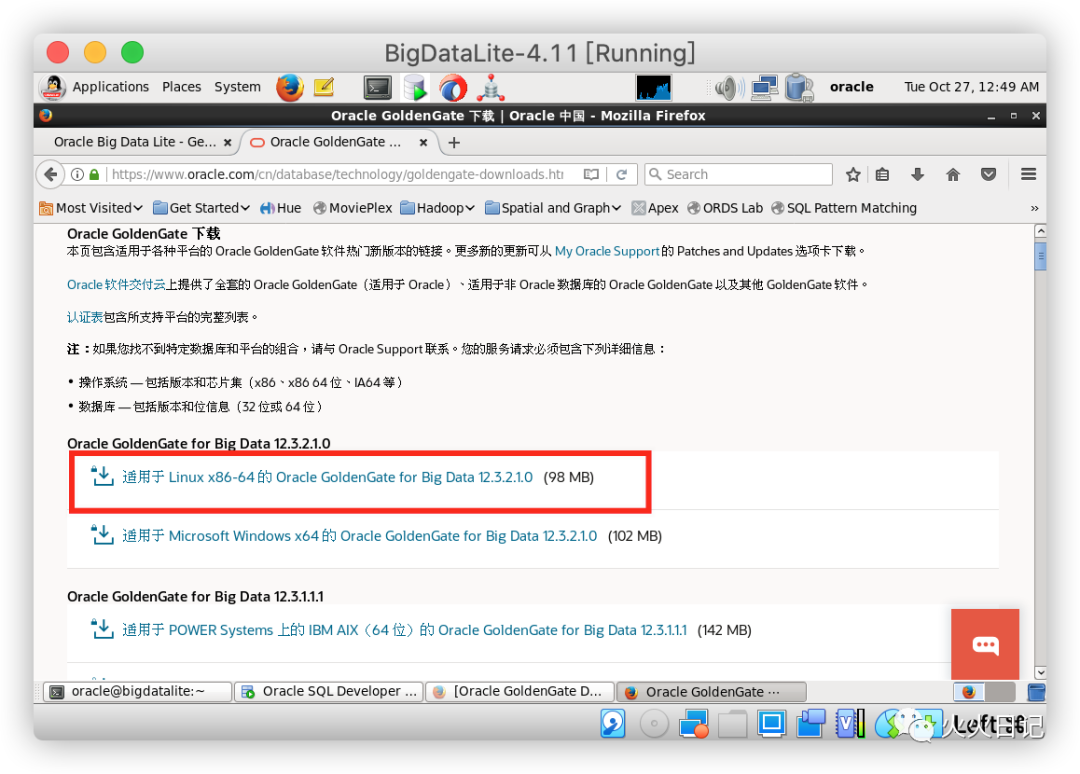
*假如在Linux环境中下载出现问题时,建议用mac或者Windows下载好Zip文件后,用SCP把文件同步到虚拟机中
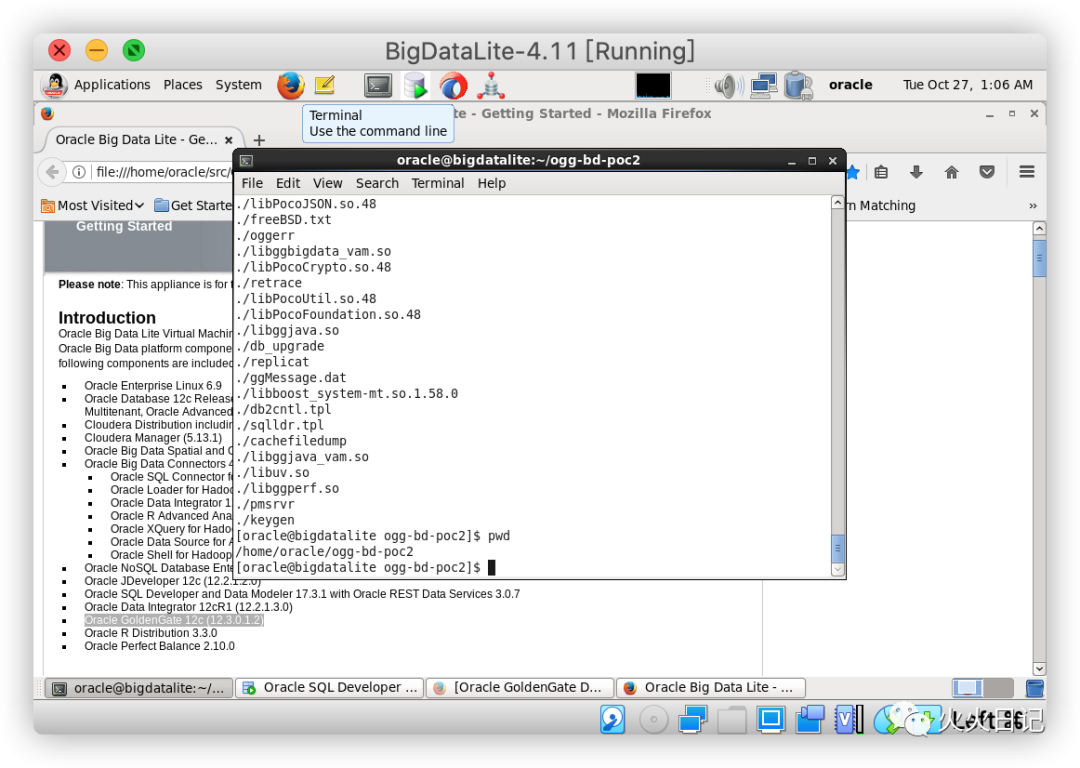
下载完毕后,通过如下代码进行安装
cd ~/Downloadsunzip OGG_BigData_Linux_x64_12.3.2.1.0.zipcd ..mkdir ogg-bd-poc2cd ogg-bd-poc2tar xvf ../Downloads/OGG_BigData_Linux_x64_12.3.2.1.0.tar复制
就这样,GoldenGate for Big Data 12c被安装在了/home/oracle/ogg-bd-poc2文件夹中
9. 启动GoldenGate for Big Data Manager
在这一步骤,我们将完成整体架构中如下部分的工作
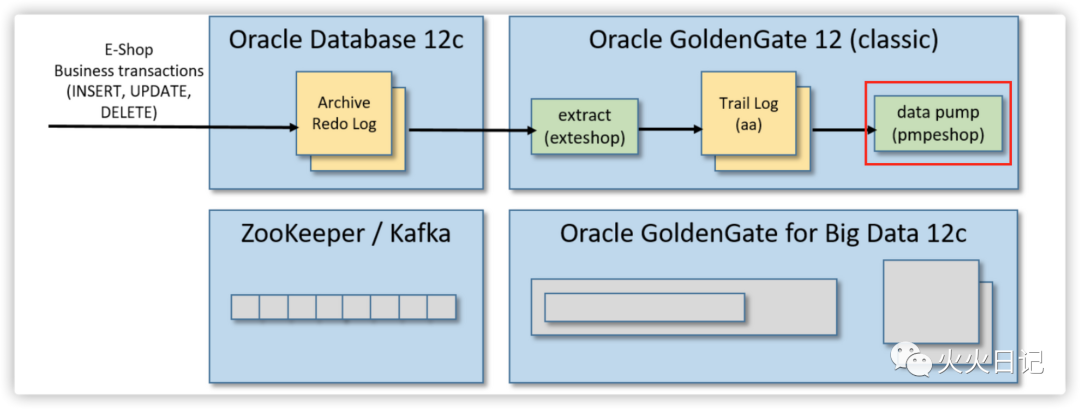
打开GoldenGate for Big Data CLI
cd ~/ogg-bd-poc2./ggsci复制
需要更改管理器端口,否则会与之前启动的与GoldenGate (classic)管理器发生冲突
在GoldenGate for Big Data CLI运行如下代码
create subdirsedit params mgr复制
在vi编辑界面输入如下内容
PORT 27801复制
然后保存内容,退出vi,返回CLI,完成GoldenGate for Big Data manager监听端口27081的修改
start mgr复制
10. 创建Data Pump
在这一步骤,我们将完成整体架构中如下部分的工作
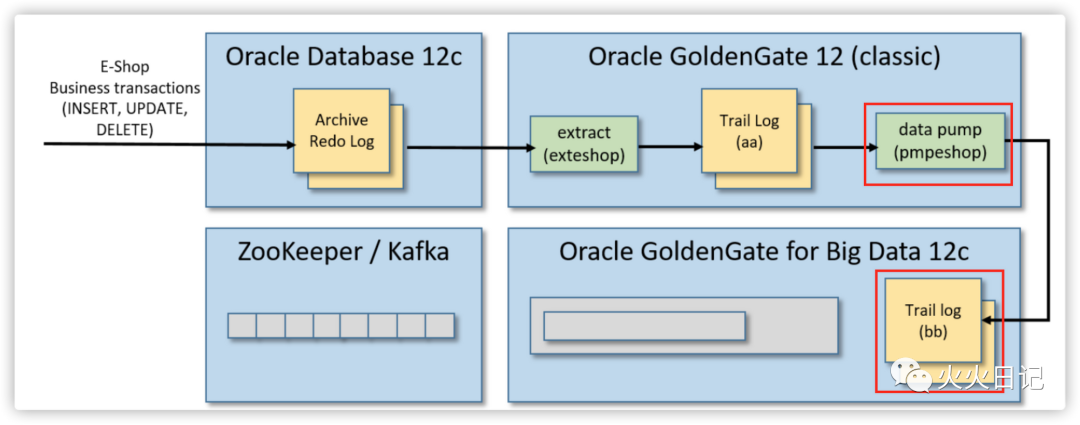
接下来我们需要创建在GoldenGate中创建数据泵(Data pump)。数据泵是一个数据提取进程,它会实时监控源端OGG的trail log,然后实时地将任何更改信息推到目标端OOG实例的Trial log中
按照如下顺序进行数据泵创建
cd /u01/ogg./ggsciedit params pmpeshoo复制
在vi编辑页面中加入以下内容
EXTRACT pmpeshooUSERID ggadmin,PASSWORD ggadminSETENV (ORACLE_SID='orcl')-- GoldenGate for Big Data address/port:RMTHOST localhost, MGRPORT 27801RMTTRAIL ./dirdat/bbPASSTHRU-- The "tokens" part it is useful for writing in the Kafka messages-- the Transaction ID and the database Change Serial NumberTABLE orcl.eshop.*, tokens(txid = @GETENV('TRANSACTION', 'XID'), csn = @GETENV('TRANSACTION', 'CSN'));复制
保存内容并退出vi
接下来我们要通过GoldenGate CLI注册并启动数据泵
dblogin userid ggadmin password ggadmin复制
add extract pmpeshoo, exttrailsource ./dirdat/aa begin nowadd rmttrail ./dirdat/bb extract pmpeshoostart pmpeshoo复制

通过从GoldenGate CLI运行以下命令来检查数据泵的状态,其中view report pmpeshop为查看数据泵日志
info pmpeshooview report pmpeshoo复制
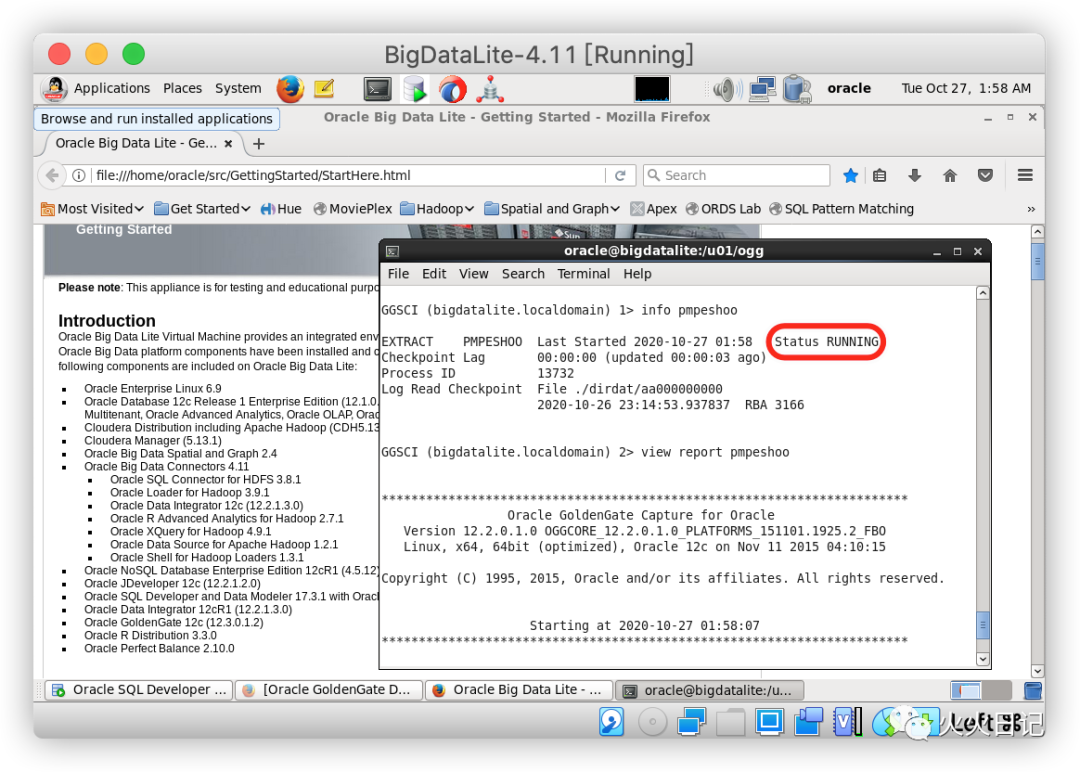
接下来我们可以在源表中插入新的模拟数据,来确认下数据泵是否正常工作
首先登陆数据库
sqlplus eshop/eshop@ORCL复制
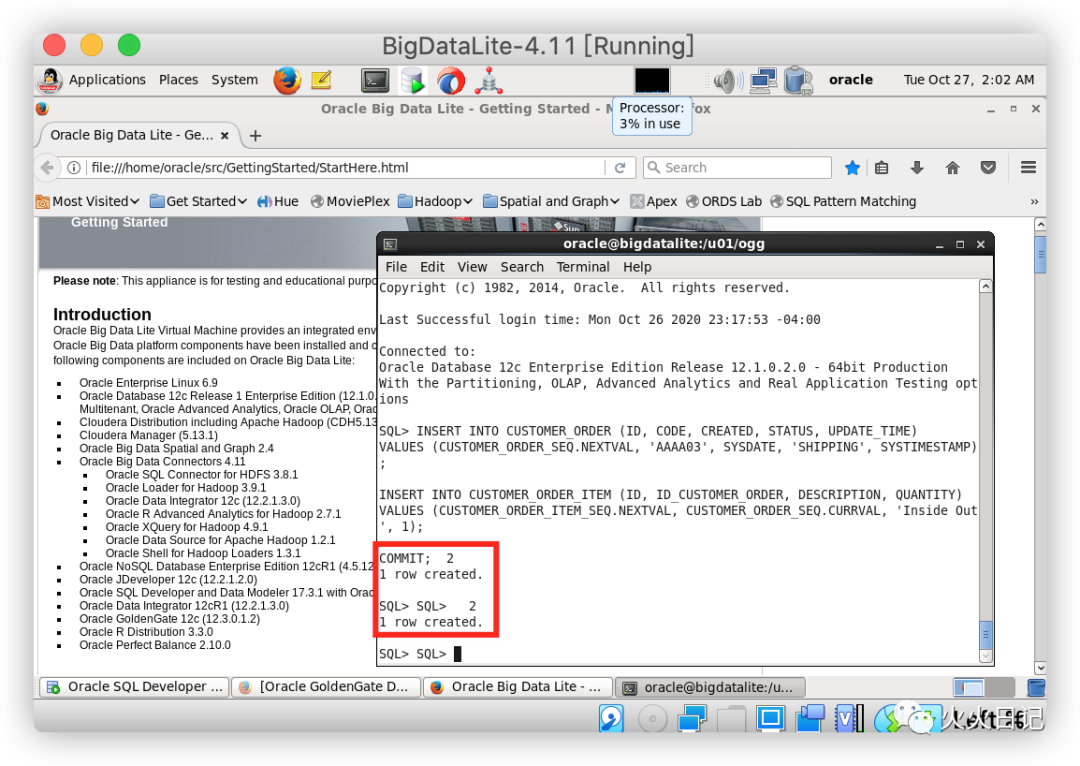
执行下方SQL脚本创建一个新的模拟客户订单数据
INSERT INTO CUSTOMER_ORDER (ID, CODE, CREATED, STATUS, UPDATE_TIME)VALUES (CUSTOMER_ORDER_SEQ.NEXTVAL, 'AAAA03', SYSDATE, 'SHIPPING', SYSTIMESTAMP);INSERT INTO CUSTOMER_ORDER_ITEM (ID, ID_CUSTOMER_ORDER, DESCRIPTION, QUANTITY)VALUES (CUSTOMER_ORDER_ITEM_SEQ.NEXTVAL, CUSTOMER_ORDER_SEQ.CURRVAL, 'Inside Out', 1);COMMIT;复制
可确认源表两行数据已成功插入
在GoldenGate(Classic) CLI运行如下代码
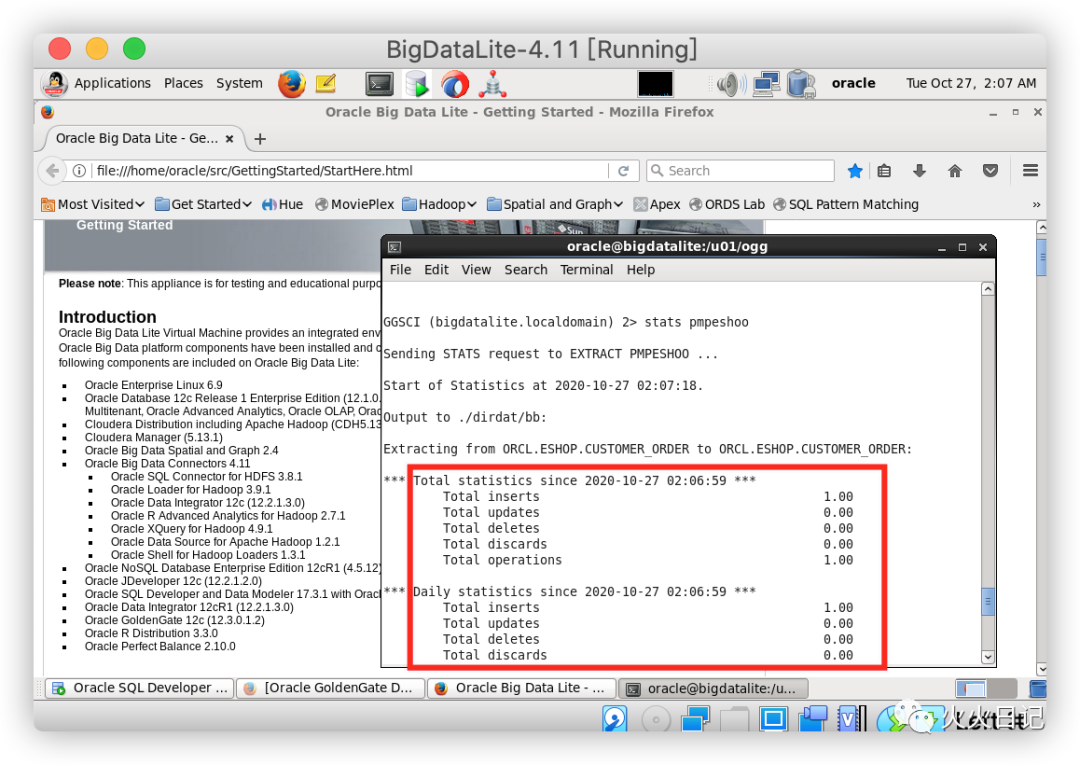
stats pmpeshoo复制
可确认已成功插入变更记录数据
11. 将事务发布到Kafka
在这一步骤,我们将完成整体架构中如下部分的工作
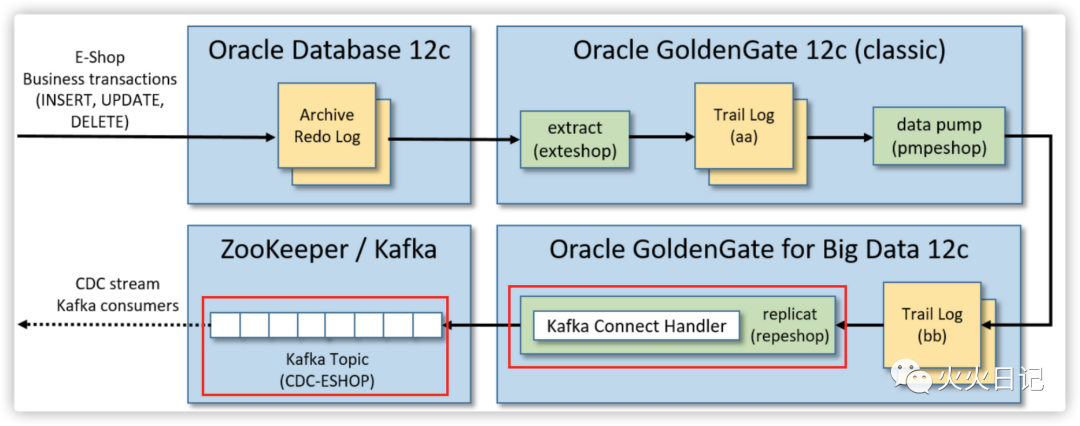
最后,我们将在GoldenGate中为BigData创建一个replicat process,以便往Kafka Topic中插入实时业务数据。replicat进程会从trail log中读取事务的增删改操作,并将此信息转换为JSON格式后传递给Kafka
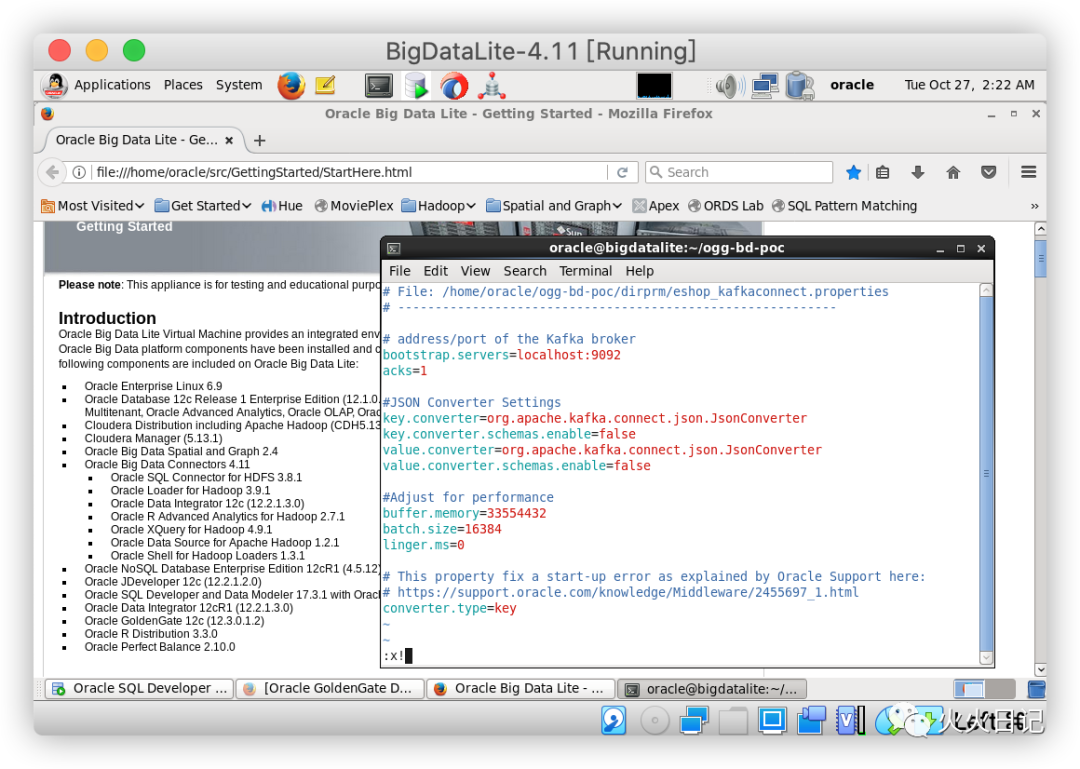
下面在/home/oracle/ogg-bd-poc2 /dirprm路径下创建一个名为eshop_kafkaconnect.properties的文件。文件内输入如下代码
# File: /home/oracle/ogg-bd-poc/dirprm/eshop_kafkaconnect.properties# -----------------------------------------------------------# address/port of the Kafka brokerbootstrap.servers=localhost:9092acks=1#JSON Converter Settingskey.converter=org.apache.kafka.connect.json.JsonConverterkey.converter.schemas.enable=falsevalue.converter=org.apache.kafka.connect.json.JsonConvertervalue.converter.schemas.enable=false#Adjust for performancebuffer.memory=33554432batch.size=16384linger.ms=0# This property fix a start-up error as explained by Oracle Support here:# https://support.oracle.com/knowledge/Middleware/2455697_1.htmlconverter.type=key复制
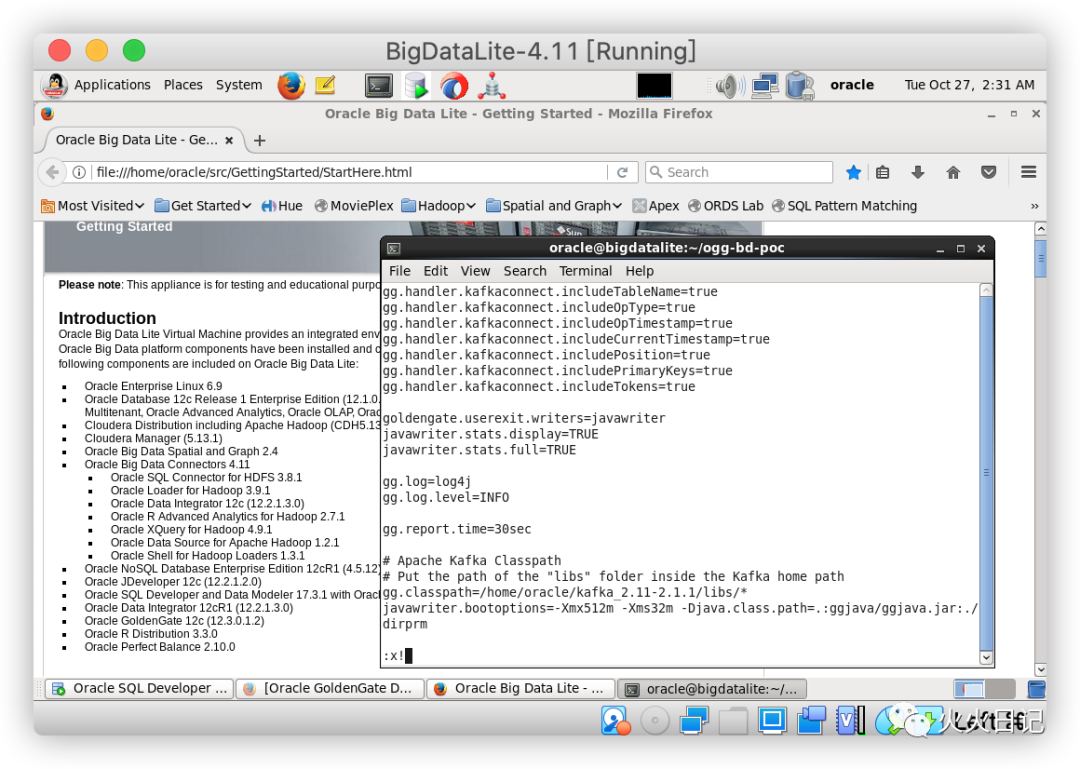
在同一个文件夹中,创建一个名为eshop_kc.props的文件,文件内输入如下代码
# File: /home/oracle/ogg-bd-poc2/dirprm/eshop_kc.props# ---------------------------------------------------gg.handlerlist=kafkaconnect#The handler propertiesgg.handler.kafkaconnect.type=kafkaconnectgg.handler.kafkaconnect.kafkaProducerConfigFile=eshop_kafkaconnect.propertiesgg.handler.kafkaconnect.mode=tx#The following selects the topic name based only on the schema namegg.handler.kafkaconnect.topicMappingTemplate=CDC-${schemaName}#The following selects the message key using the concatenated primary keysgg.handler.kafkaconnect.keyMappingTemplate=${primaryKeys}#The formatter propertiesgg.handler.kafkaconnect.messageFormatting=opgg.handler.kafkaconnect.insertOpKey=Igg.handler.kafkaconnect.updateOpKey=Ugg.handler.kafkaconnect.deleteOpKey=Dgg.handler.kafkaconnect.truncateOpKey=Tgg.handler.kafkaconnect.treatAllColumnsAsStrings=falsegg.handler.kafkaconnect.iso8601Format=falsegg.handler.kafkaconnect.pkUpdateHandling=abendgg.handler.kafkaconnect.includeTableName=truegg.handler.kafkaconnect.includeOpType=truegg.handler.kafkaconnect.includeOpTimestamp=truegg.handler.kafkaconnect.includeCurrentTimestamp=truegg.handler.kafkaconnect.includePosition=truegg.handler.kafkaconnect.includePrimaryKeys=truegg.handler.kafkaconnect.includeTokens=truegoldengate.userexit.writers=javawriterjavawriter.stats.display=TRUEjavawriter.stats.full=TRUEgg.log=log4jgg.log.level=INFOgg.report.time=30sec# Apache Kafka Classpath# Put the path of the "libs" folder inside the Kafka home pathgg.classpath=/home/oracle/Downloads/kafka_2.11-2.1.1/libs/*javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=.:ggjava/ggjava.jar:./dirprm复制
重新打开GoldenGate for Big Data CLI
cd ~/ogg-bd-poc2./ggsci复制
开始创建replicat进程
edit params repeshoq复制
在vi界面输入如下代码
REPLICAT repeshoqTARGETDB LIBFILE libggjava.so SET property=dirprm/eshop_kc.propsGROUPTRANSOPS 1000MAP orcl.eshop.*, TARGET orcl.eshop.*;复制
保存并退出vi

将replicat与trail log(bb)进行关联,并启动replicat进程
add replicat repeshoq, exttrail ./dirdat/bbstart repeshoq复制
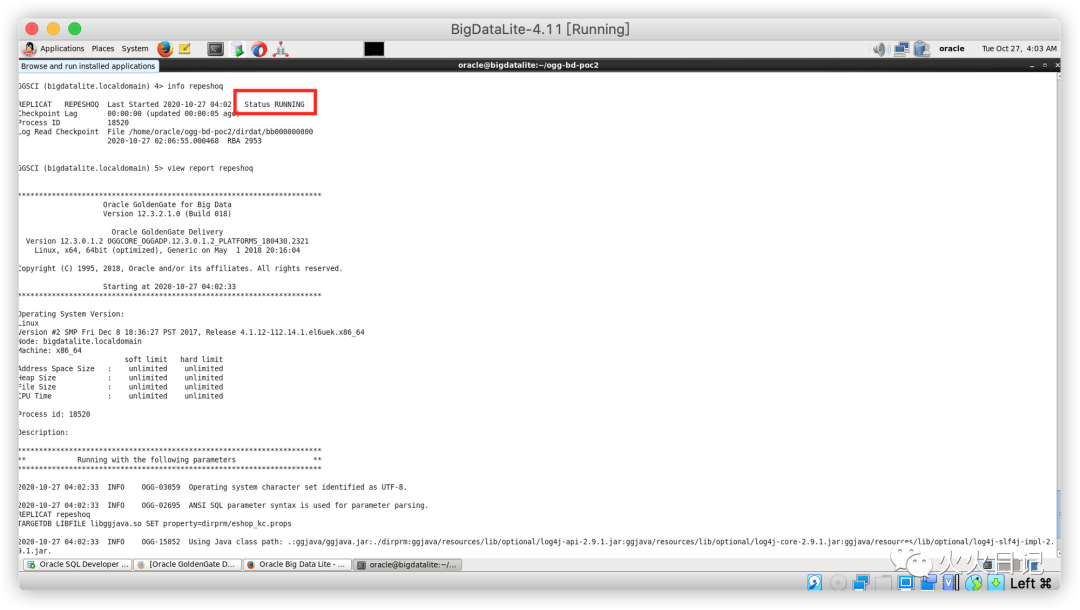
确认replicat是否正常工作,其中view report repeshoq是查看日志的模块
info repeshoqview report repeshoq复制
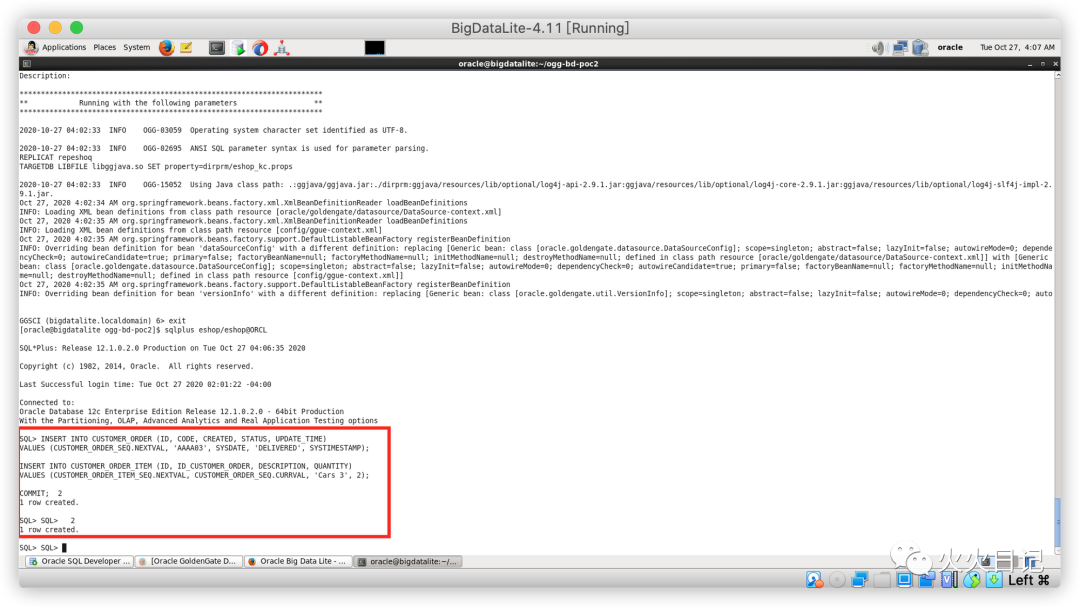
接下来在Oracle 数据库源表中插入数据,确认数据是否实时同步到来kafka Topic中
首先在Linux shell中登陆到数据库
sqlplus eshop/eshop@ORCL复制
插入数据语句
INSERT INTO CUSTOMER_ORDER (ID, CODE, CREATED, STATUS, UPDATE_TIME)VALUES (CUSTOMER_ORDER_SEQ.NEXTVAL, 'AAAA03', SYSDATE, 'DELIVERED', SYSTIMESTAMP);INSERT INTO CUSTOMER_ORDER_ITEM (ID, ID_CUSTOMER_ORDER, DESCRIPTION, QUANTITY)VALUES (CUSTOMER_ORDER_ITEM_SEQ.NEXTVAL, CUSTOMER_ORDER_SEQ.CURRVAL, 'Cars 3', 2);COMMIT;复制
可以确认数据已成功插入源表中
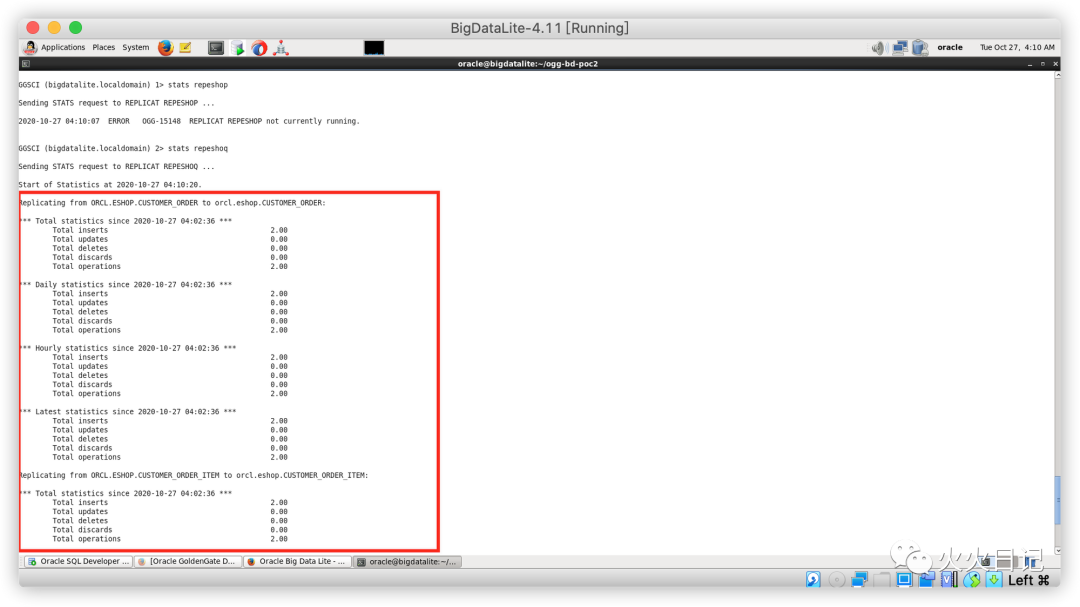
在GoldenGate for Big Data CLI中确认数据是否同步到了replicat进程中
./ggscistats repeshoq复制
可以看到数据同步是正常的
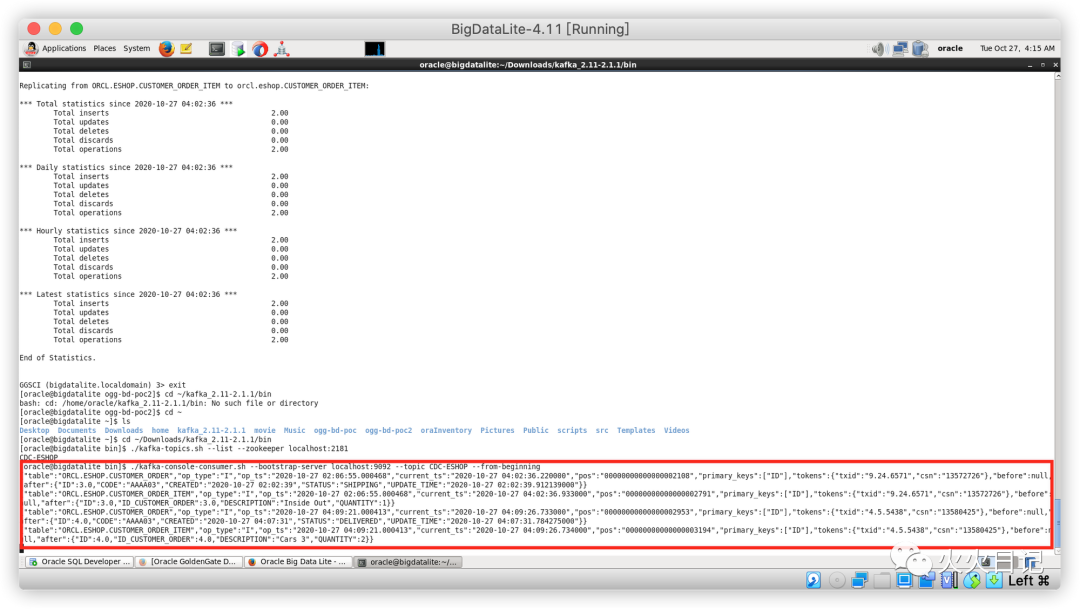
下面我们可以访问Kafka内部,具体查看是否有一个名为CDC-ESHOP的Topic创建成功
cd ~/Downloads/kafka_2.11-2.1.1/bin./kafka-topics.sh --list --zookeeper localhost:2181复制
可以看到已经成功创建了CDC-ESHOP Topic

同时我们可以通过如下代码,访问存储在CDC-ESHOP Topic之内的数据
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic CDC-ESHOP --from-beginning复制
通过下图我们可以清晰的看到,源库源表中新插入的数据都已经实时的同步到了Kafka队列中
如果现在的输出结果看的不清楚,我们可以通过安装jq来进行查看
sudo yum -y install jq./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic CDC-ESHOP --from-beginning | jq .复制
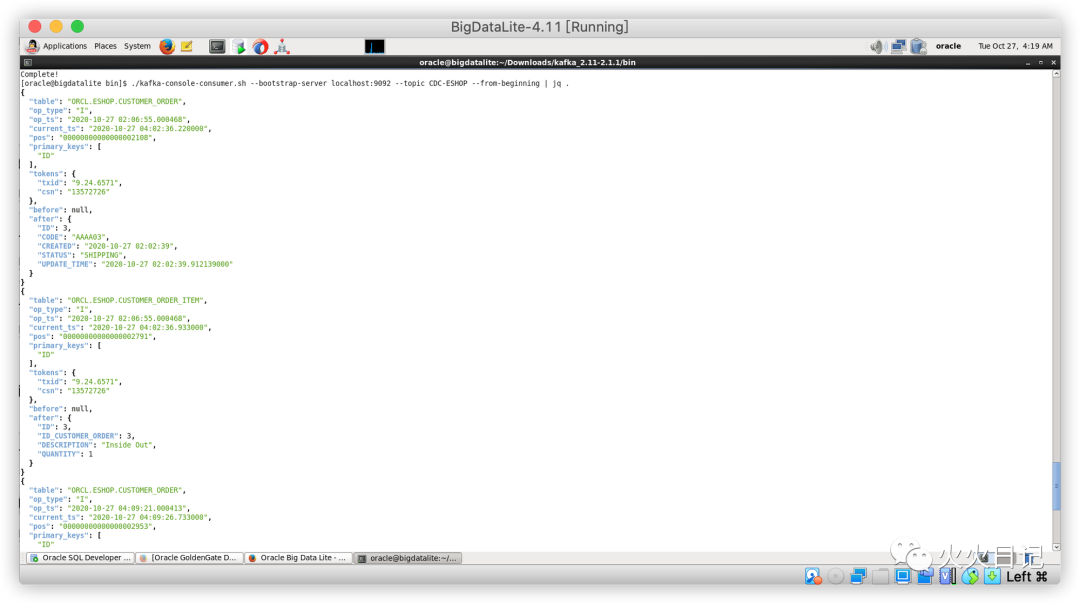
至此我们完成了从Oracle Dababase 12C源库数据到Kafka的实时数据同步,后续我们可以用Python、Java或者FlinkSQL写Kafka的消费程序,实时进行数据处理和计算后落到结果表中
谢谢大家!
