




今天开始咱们就正式聊聊机器学习。
首先说到传统机器学习,是源自50年代纯统计学的方法。旨在解决复杂的数学任务,即通过探索数据间的Pattern,评估数据,探索向量的方向及大小。
现如今,很多企业正在研究这些传统算法。比如,当你在国外旅游时境外刷了第一笔信用卡,这时银行客服会联系你,并与你确认是否为本人操作。这背后其实就是机器学习模型,因为它捕捉到了和你平时消费习惯不同的异常情况。金融领域我们通常称之为Fraud Detection(反欺诈),常见算法有GBDT,Logistic等。
虽然大型科技公司对神经网络青睐有加。因为对他们来说,提高2%的模型准确率意味着可能获得巨大的利润。但对于中小企业来讲,我觉得没有太大意义。比如与其花费一年的时间构建电商平台的推荐算法,倒不如把精力投入到客户分析和品牌分析,专注于提高用户触点上。因为你用神经网路搭建的推荐算法准确率再高,大多数用户甚至可能连你的电商平台主页都不点开看一次,何来推荐?何来Cross Selling?
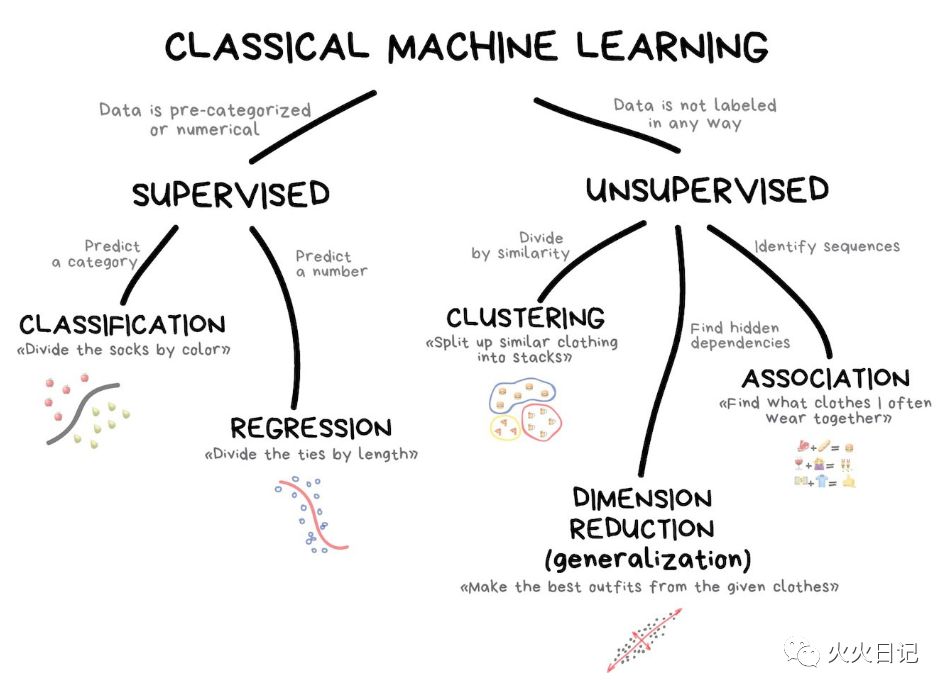
有点扯远了,咱们再回到传统机器学习分类,可以参照如下树状结构。
监督学习(Supervised Learning)
传统机器学习通常分为两类,监督学习和无监督学习。
监督学习 你可以认为,机器有一个“主管”或“老师”,它给机器提供所有答案。比如在所有图片数据中,这位非常有责任心的“老师”已经标记出了这张图片是猫还是狗。那么机器要做的事情就是根据“老师”已经划分(标记)为猫的数据样本中,提取猫的数据特征,再根据划分(标记)为狗的数据样本中,提取狗的数据特征,然后再有新的图片数据进入时,就可以根据猫和狗的数据特征去判断这个动物是猫还是狗。
无监督学习是说机器只留下一堆动物照片,你不知道都有哪些动物,你的任务是从中找出谁是谁。数据没有标记,没有“老师”告诉你答案,机器试图自己找到数据模式。
对于第一次接触机器学习的人,可能听起来还是有点云里雾里...
不要紧,我们再细化一下,先聊聊监督学习中的分类和回归。
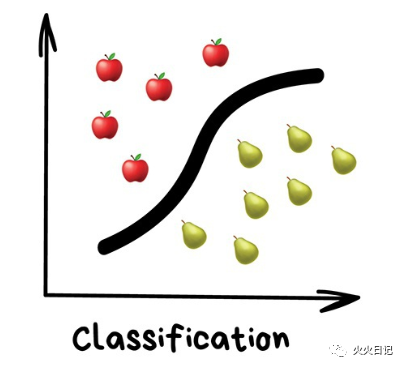
1. 分类
“根据已知的属性,分割对象。如根据颜色将袜子做分类,把苹果和梨做分类”
主要应用于:
– 垃圾邮件过滤
– 语言检测
– 搜索类似文件
– 情感分析
– 识别手写字符和数字
– 反欺诈
常见算法:朴素贝叶斯,决策树,Logistic回归,K-邻近法,支持向量机
顾名思义分类学习主要是处理关于事物的分类问题。 机器就好比一个学习分类玩具的婴儿,它对世间万物都是一窍不通的,你需要逐一告诉机器,红颜色的是苹果,黄颜色的是梨。之所以把分类问题称之为监督学习,是因为所有训练数据都有数据标签(Label)的,即红颜色的数据已经标记成了苹果,黄颜色的数据已经标记成了梨。机器可以根据标记的结果直接做分类。
世间所有都是可以被分类的,基于兴趣的用户分类,基于语言和主题的文章分类(对搜索引擎很重要),基于流派的音乐分类(Spotify播放列表),甚至是您的电子邮件。
朴素贝叶斯(Naive Bayes)是历史上作为最优雅和最初使用的一个在垃圾邮件过滤器。这种算法是计算垃圾邮件和普通邮件中的“广告性文字”提及的数量,然后使用贝叶斯方程将两个概率相乘,再对结果进行求和。
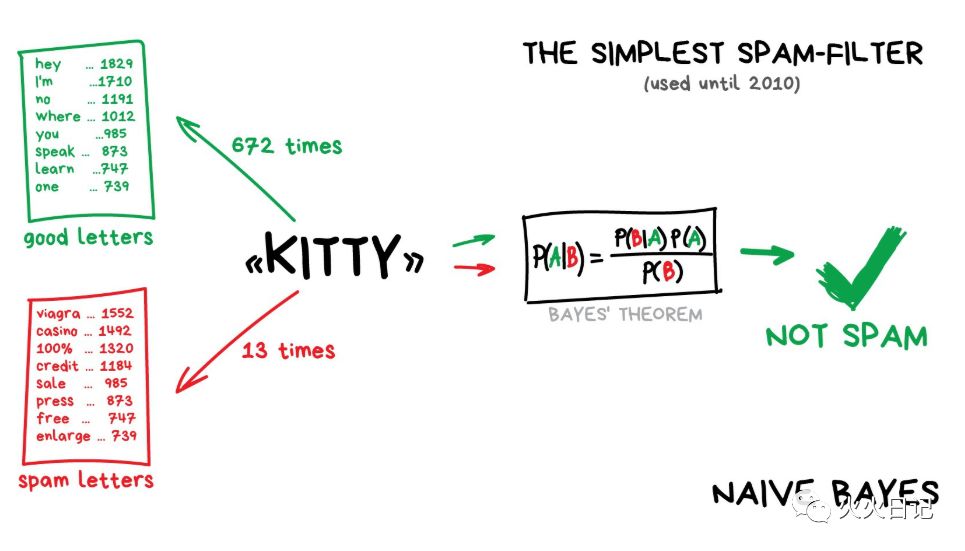
后来,垃圾邮件发送者也变得越来越狡猾,他们通过在电子邮件末尾添加了大量的“好”字,来应付贝叶斯过滤器,这种方法被称为Bayesian Poisoning(贝叶斯中毒)。所以现在其他算法也用于垃圾邮件过滤。
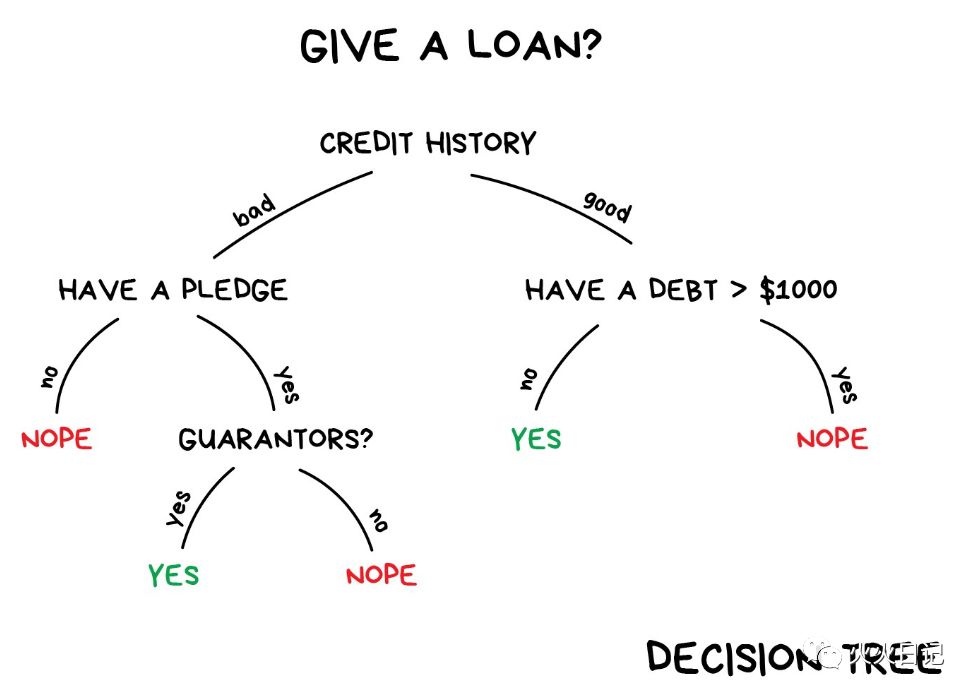
我们再举一个分类的例子。假设你需要一些信贷资金。银行如何判断你是否会按时还款?确切的说,他们也不知道你会不会按时还款。但是银行有很多过去借贷人的数据。他们有关于年龄,教育,职业和工资的数据,还有最重要的,这些人是否还款,yes or no的数据。有了这些数据,银行就可以通过模型探索数据的Pattern,并评估出你按时还款的概率,再决定是否放款。还有一个问题是银行不能盲目信任模型预测的结果。如果出现系统故障或者黑客攻击,该怎么办?
为了解决这个问题,我们会使用决策树,所有数据会自动分为是/否问题。例如,借款人的收入是否超过1万元?机器通过提出这样的问题,以便在每一步中最好地分割数据。这就是树的训练方式。任何分析师都可以接受并解释的万金油算法。有的时候他可能不理解模型,但却很容易解释!所以决策树广泛用于高责任范围:如诊断,医学和财务。其中比较常用的CART(分类回归树)和C4.5。
支持向量机(SVM)是最流行的经典分类方法之一。
SVM背后的原理很简单,它试图在数据点之间绘制两条线,让它们之间的间距最大。
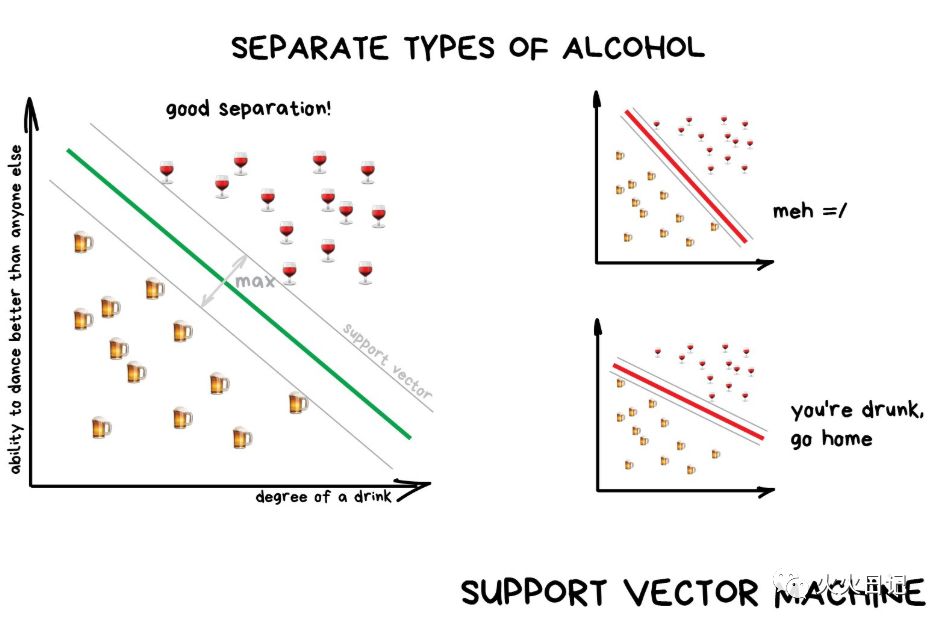
分类中还有一个常见的应用,异常检测。当某个功能不属于任何一个分类时,我们可以High light它。比如可以在医学领域的MRI上,计算机High light所有可疑区域或测试的偏差。股票市场可以用它来检测交易者的异常行为,以找到具体问题。
而现如今,神经网络更常用于分类问题。这其实也是神经网络被发明出来的原因之一。
通常来讲,数据越复杂,算法也越复杂。
对于文本,数字和表格,一般选择传统机器学习算法。模型也比较小,它们学得更快。而像对于图片,视频和所有其他复杂的大数据事物,可以考虑神经网络。
就在五年前,我们还可以找到基于SVM构建的人脸分类器。 而如今,从数百个经过预先训练的神经网络中进行选择变得更加容易。不过,垃圾邮件过滤器使用SVM编写的还是比较多。
2. 回归
“通过已知的数据点画一条线。这就是回归”
主要应用于:
– 股票价格预测
– 需求和销量分析
– 医学诊断
– 任何数字时间相关预测
常见算法:线性回归、多项式回归
与分类问题不同,回归问题我们预测的是数字而不是类别。例如,按行驶里程预测的汽车价格,按时间预测的交通量等。当某些事情取决于时间时,回归是完美的。从事金融和分析相关工作的人一般都会比较喜欢回归。因为他们总是和数打交道,回归甚至内置于Excel中...
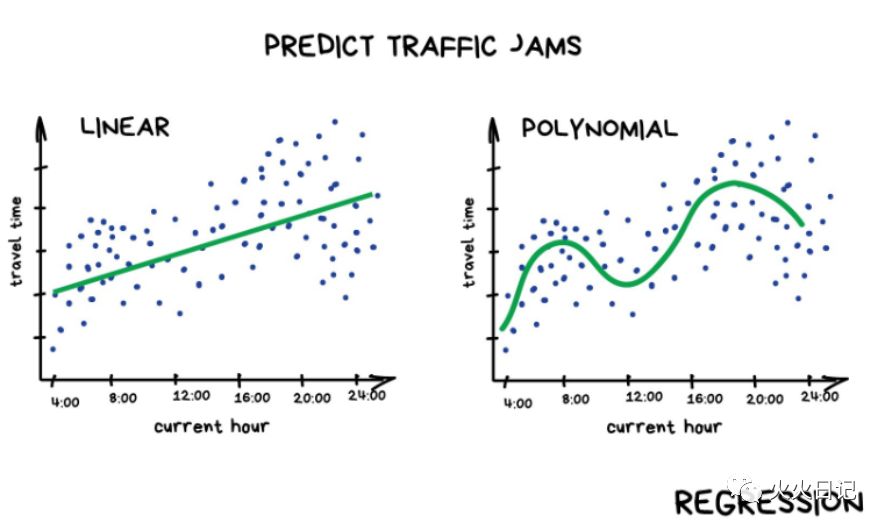
当预测值为直线时我们称之为线性回归,当预测值为曲线时我们称之为多项式回归。这是两种主要的回归类型,而Logistic回归就好比羊群中的一只黑羊。因为它是一种分类方法,而不是回归方法。
不过,事实上其实也可以不把回归和分类区分的那么清楚。经过一些调整后,许多分类器可以变成回归。我们不仅可以定义对象的类,还可以计算对象的接近程度。这是回归。这部分可参照如下文档
https://medium.com/machine-learning-for-humans/supervised-learning-740383a2feab
今天的机器学习部分就到这里,下期我们接着来讲传统机器学习的无监督学习部分!
