





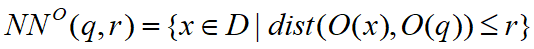
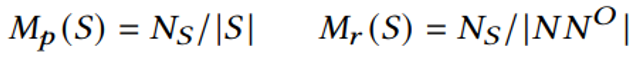
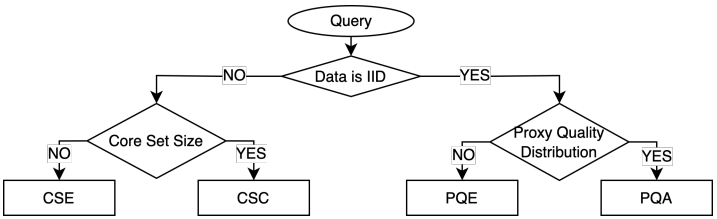

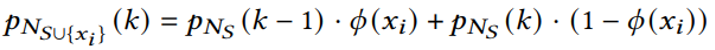
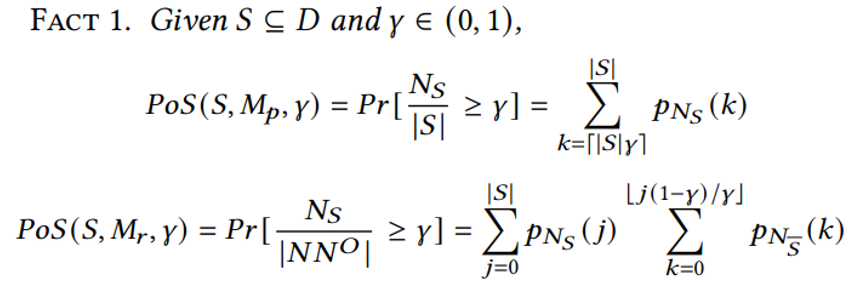
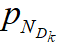 和PoS(S, Mp,γ),最后返回满足要求的Dk*。而对于RT查询,PQA-RT使用二分查找来识别最小的k*使得PoS(Dk, Mp, γ)≥ 1 - δ,接着计算出Dk的互补率并返回Dk*作为答案。以下是算法伪代码1-8为PQA-PT,9-26为PQA-RT。
和PoS(S, Mp,γ),最后返回满足要求的Dk*。而对于RT查询,PQA-RT使用二分查找来识别最小的k*使得PoS(Dk, Mp, γ)≥ 1 - δ,接着计算出Dk的互补率并返回Dk*作为答案。以下是算法伪代码1-8为PQA-PT,9-26为PQA-RT。
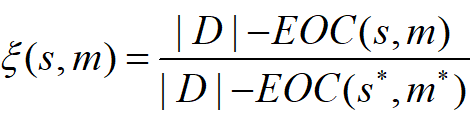 ,越大的节省比率表示更优的近似解。
,越大的节省比率表示更优的近似解。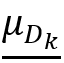 ,可以通过启发式方法来识别具有良好互补率和高的Dk。
,可以通过启发式方法来识别具有良好互补率和高的Dk。

本文作者 周敏欣 |  |
文章转载自时空实验室,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
DolphinDB 在深度学习中的应用:股票实时波动率预测
DolphinDB
108次阅读
2025-03-20 10:44:13
国密算法介绍
漫步者
49次阅读
2025-03-21 09:20:39
如何用大模型评估大模型——PAI-Judge裁判员大语言模型的实现简介
阿里云大数据AI技术
45次阅读
2025-03-21 10:02:49
《揭开多头注意力机制的神秘面纱:解锁自然语言处理的超能力》
程序员阿伟
37次阅读
2025-03-20 22:43:14
《人工智能赋能网络拓扑分析:洞察关键节点与脆弱链路》
程序员阿伟
35次阅读
2025-03-23 22:50:29
《深度剖析:BERT与GPT——自然语言处理架构的璀璨双星》
程序员阿伟
29次阅读
2025-03-20 22:42:44
AutoGLM助力数据库管理员:必备AI技能全解析
青年数据库学习互助会
27次阅读
2025-04-14 09:40:49
北京南文观点:AI掘金术激活算法中的“沉默用户”
数据财报
27次阅读
2025-03-21 19:58:58
PostgreSQL与AI融合:开启数据库智能新时代
开源软件联盟PostgreSQL分会
26次阅读
2025-04-10 11:52:55
卷积神经网络(CNN)原理深度剖析,带你彻底搞懂CNN!
戏说数据那点事
26次阅读
2025-03-28 14:57:19
