COVID-19疫情的流行给人们的心理、经济和社会关系带来了极大影响。然而,预测疫情动态却面临空间和时间依赖性复杂、影响因素众多、难以找到合适的粒度三大挑战。本次为大家带来国际数据库顶级会议ICDE 2023上的论文《Forecasting COVID-19 Dynamics: Clustering, Generalized Spatiotemporal Attention, and Impacts of Mobility and Geographic Proximity》。1 背景
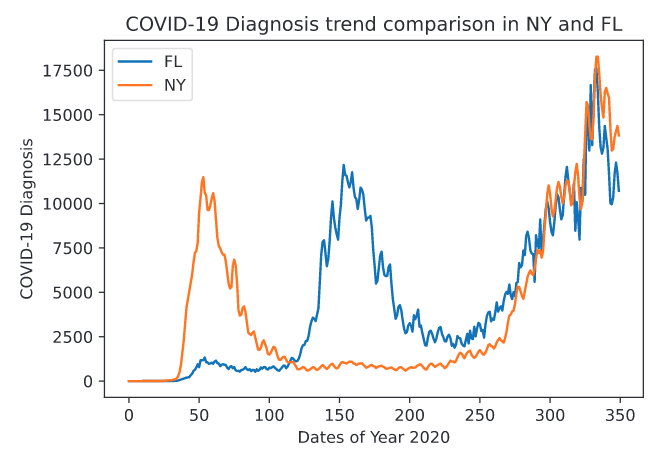
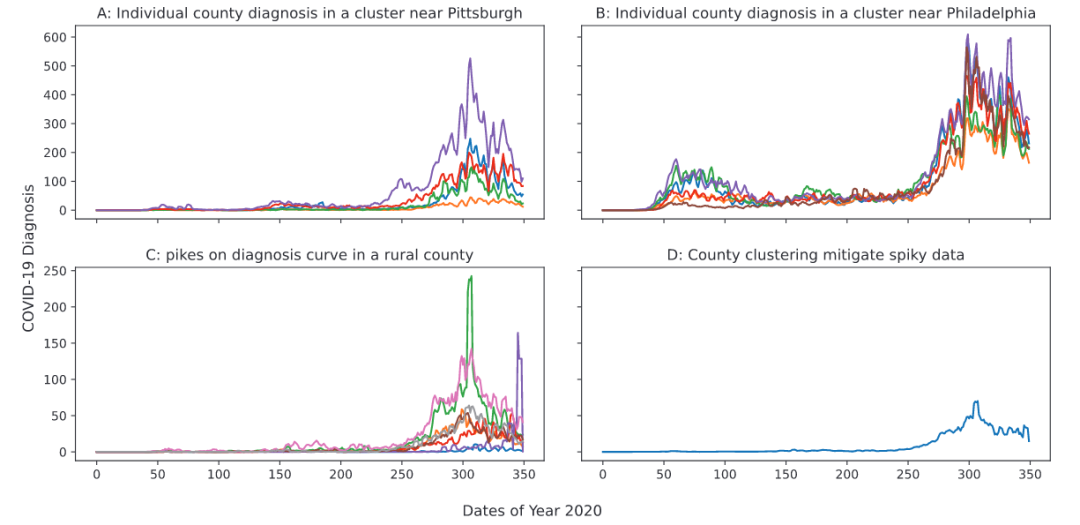
过去几年,COVID-19大流行极大地影响了全球人们的生活,给经济和社会带来了毁灭性的挑战。在这种情况下,了解疫情的动态并预测其未来趋势至关重要,有助于政府机构和公共卫生管理者采取积极措施来应对,不仅是遏制病毒,也可以预见的疫情爆发,以规划和准备必要的资源。而这项预测任务面临几个关键挑战:首先,COVID-19的动态表现出复杂的空间和时间依赖性。某些地区可能比其他地区更早感染病毒,导致不同地区的疫情趋势可能会出现偏差。如图1所示,纽约和佛罗里达州的每日新增病例在不同的时间呈现出类似的趋势,这一关键特性称为时间错位。其次,人口流动性、地区间地理邻近性、口罩使用情况、疫苗覆盖率等众多因素都会对动态产生显着影响,而传统的统计模型和机器学习模型不能灵活地利用这些因素,以致难以准确预测动态。第三,为预测任务找到合适的粒度很重要。粒度不宜太粗,以免忽略各个区域的特性。同时粒度也不应该太细,否则预测结果很容易受到噪声的影响。 图1 纽约和佛罗里达州每日新增的COVID-19病例论文提出了一种简单而有效的聚类算法,可以为预测任务找到合适的粒度。并且发明了广义时空注意力,这是一种足够泛化的注意力机制,可以捕获复杂的空间和时间依赖性,还可以灵活地考虑区域内和区域间的特征。论文还设计了COVID-Forecaster,一种用于预测 COVID-19动态的轻量级深度学习模型。实验结果表明,COVID-Forecaster的性能显着优于最先进的模型。值得注意的是,论文方法不是只关注 COVID-19数据,而是根据几个辅助数据,例如口罩使用情况、疫苗覆盖率、人口流动性、地理邻近性等,对传播动态进行参数化,提供实时分析以了解不同情况下未来可能的流行趋势。大多数现有模型预测的是州级的COVID-19趋势,预测粒度较粗,难以对州内城乡差异进行建模,且州级预测只能利用较小的数据集。此外,农村地区的县级统计数据存在尖峰且嘈杂,如图2c所示。此类数据会降低模型性能。另一方面,地理上相邻且人口相似的农村县通常具有非常相似的趋势,如图2a和2b所示。尽管COVID-19的绝对规模可能不同,但总体趋势通常非常相似。
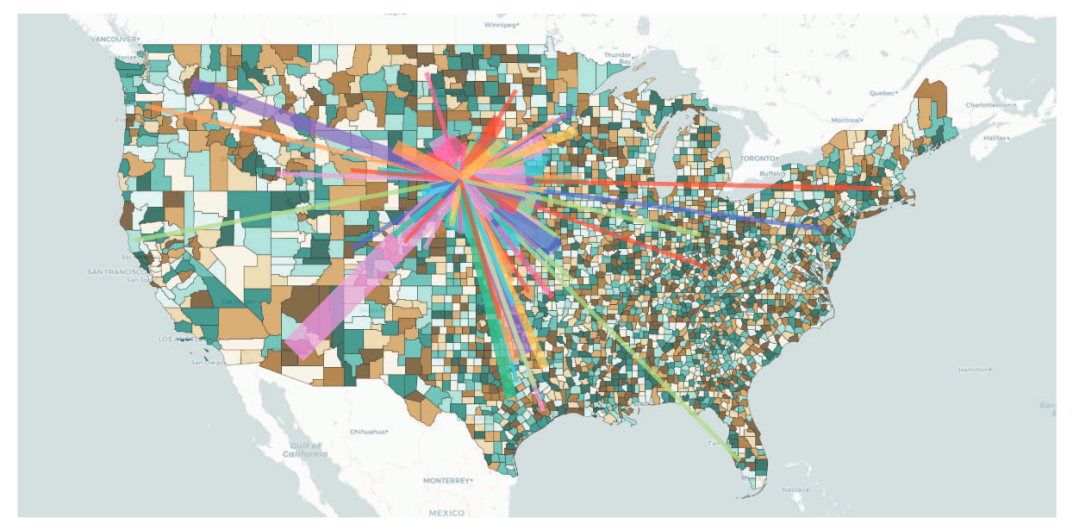
论文设计的聚类算法,可以自适应地将具有相似人口的附近农村县分组在一起,并将它们视为模型中的一个预测单元。聚类算法的细节如下:首先,设置一个人口阈值来确定一个州内县组的数量。例如,如果一个州有1000万人口,而阈值为100万,那么州内将有10个县组。对于该州的每个县i,通过为其分配特征向量hi = [ lai loi pi ]T将其映射到特征空间,其中lai、loi和pi是该县的纬度、经度和人口。基于特征向量,将这些县聚类成州内县组的目标数量。论文修改了层次聚类算法,在其每个中间步骤中,只合并地理上相邻的聚类。这样可以保证执行聚类算法后,同一组内的县是相连的。图3显示了宾夕法尼亚州和俄亥俄州的县分组结果。匹兹堡等大城市往往自行形成集群,而农村县往往与人口相似的地理邻居共同形成集群,这样能使得噪声得到有效抑制,提高了细粒度的预测精度,如图2d所示。 论文的数据源是县级COVID-19诊断统计数据、细粒度流动性数据、辅助数据(口罩使用情况、疫苗覆盖率等)以及人口和地理数据。数据时间从2020年1月6日到2022年1月23日。下面将给出各数据的详细内容:将地点i和日期t报告的诊断病例数表示为xti,其中t =1, 2, 3, ..., T且i = 1, 2, 3, ..., L。对于县级和县组级数据,L分别为3141和422。流动数据提供了对不同地点的人口流动的洞察。通过移动数据,人们可以推断出一个人在相同或不同位置联系过另一个人的概率。在流行病学建模中,这些信息可以帮助估计病毒传播风险并相应预测未来趋势。论文使用SafeGraph数据,它是从移动电话服务领域拥有智能手机的人们中收集的,提供了美国各地每个POI(兴趣点,即人们访问的非住宅区)的细粒度移动数据。论文将每个POI的流动性数据汇总到县级,以构建整个流动性网络,有助于对COVID-19趋势进行建模。例如,如图4所示,将第t周第i县和第j县之间的每周流动数据表示为Mti,j,其中t = 1, 2, 3, ..., T且i, j = 1, 2, 3, ..., L。每周的流动性数据也可以表示为具有时变边的稀疏有向加权图G = (V, E)。节点V代表县,边(vi, vj) 上的权重在时间步t为mti,j 。 一些医疗保健指标如口罩使用率和疫苗覆盖率在COVID-19大流行的动态中发挥着重要作用。论文从健康指标与评估研究所 (IHME) 的网站获取数据,并选择了11个最有影响力的指标,包括ICU床位容量、口罩使用情况、活动水平等,这些数据作为预测模型的上下文特征。2020年美国人口普查数据,包括县面积、人口、地理邻近度等。4 COVID-FORECASTER
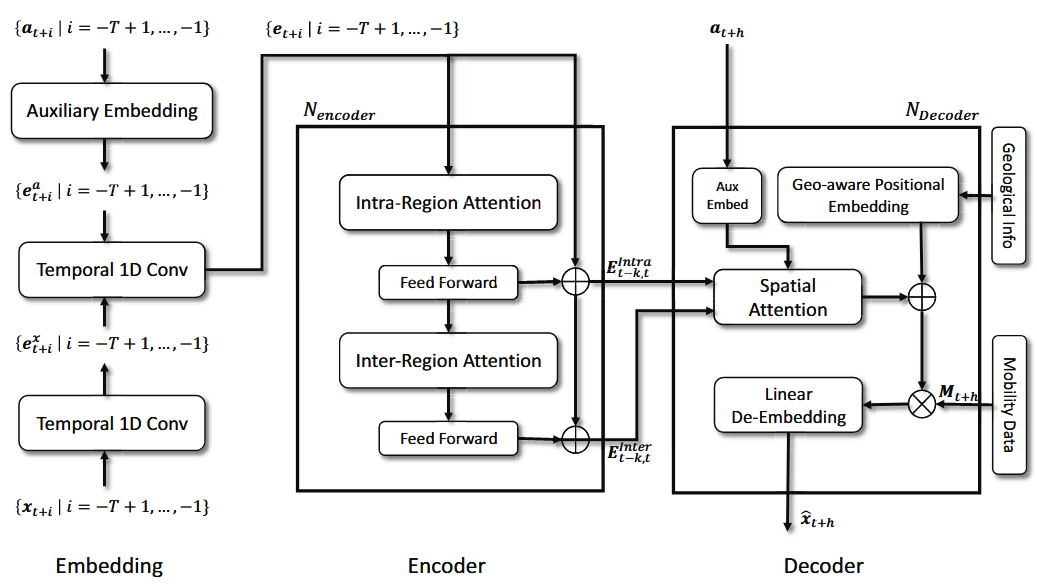
疫情预测与正常的时间序列预测任务不同,流行病数据有更多的变量需要建模,并且时间长度明显更短。此外,病毒在不同地点传播的阶段也不一致,很难直接引用跨区域的曲线。因此,建立良好的预测模型的关键挑战一是如何利用相似的时间段,二是如何用有限的数据量处理大规模的预测问题。论文使用两种不同的注意力机制来应对这些挑战。为了参考其他区域的相似时间段,论文让每个位置的当前时间步长T特征关注所有其他位置的历史特征,以找到最佳对齐的时间段。为了使模型数据高效,借鉴了传统流行病学模型的思想,构建了一个带有移动数据的特殊解码器。整体框架如图5所示,接下来具体说明每个模块结构: 注意力机制无法直接消化原始数据输入,需要将输入信号映射到嵌入空间以进行进一步处理。对于COVID-19诊断曲线和辅助数据需要采取不同的方式。COVID-19诊断数据从一维卷积开始: 。而辅助数据通过多层感知器投影到嵌入空间:
。而辅助数据通过多层感知器投影到嵌入空间: 。根据经验,将两者的嵌入与另一组一维卷积层合并是有益的,这里使用卷积步幅为2来压缩时间嵌入维度:
。根据经验,将两者的嵌入与另一组一维卷积层合并是有益的,这里使用卷积步幅为2来压缩时间嵌入维度: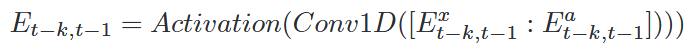 。嵌入代表了高维空间中COVID-19传播和相应的辅助数据的局部趋势。所有嵌入都可以对感受野内的时间特征进行编码,这对于预测非常有利。这种自动学习的表示在机器学习领域和其他时间序列预测任务中很常见。 聚合模块是模型的重要组成部分,用于对区域内和区域间依赖关系进行编码,如图6所示。该模块有效地对区域历史信息进行编码,并跨区域参与识别相似的趋势片段,为更好的预测作参考。图6 时间注意力模块,包括区域内注意力(绿线)和区域间注意力(蓝线)区域内聚合使模型能够根据区域历史信息进行预测。遵循多头注意力的经典设计,允许模型在所有历史时间步骤中关注来自不同嵌入的信息,收集所有历史时间信息 Eit−k,t−1 并将它们编码为在每个位置的时间步t上嵌入Eti。具体来说,对于区域i,使用时间嵌入Eti作为一种查询,用所有历史嵌入 Eit−k,t−1作为注意模块的键和值。公式计算如下:
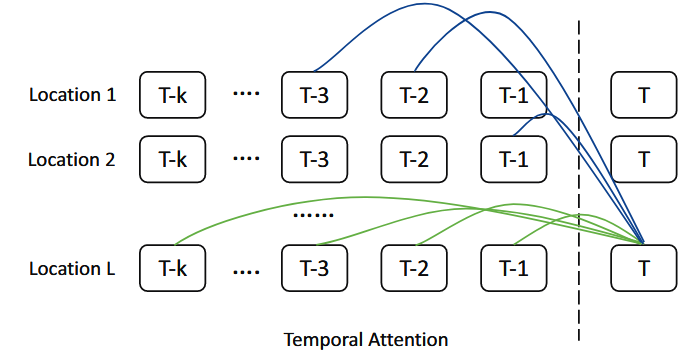
。嵌入代表了高维空间中COVID-19传播和相应的辅助数据的局部趋势。所有嵌入都可以对感受野内的时间特征进行编码,这对于预测非常有利。这种自动学习的表示在机器学习领域和其他时间序列预测任务中很常见。 聚合模块是模型的重要组成部分,用于对区域内和区域间依赖关系进行编码,如图6所示。该模块有效地对区域历史信息进行编码,并跨区域参与识别相似的趋势片段,为更好的预测作参考。图6 时间注意力模块,包括区域内注意力(绿线)和区域间注意力(蓝线)区域内聚合使模型能够根据区域历史信息进行预测。遵循多头注意力的经典设计,允许模型在所有历史时间步骤中关注来自不同嵌入的信息,收集所有历史时间信息 Eit−k,t−1 并将它们编码为在每个位置的时间步t上嵌入Eti。具体来说,对于区域i,使用时间嵌入Eti作为一种查询,用所有历史嵌入 Eit−k,t−1作为注意模块的键和值。公式计算如下: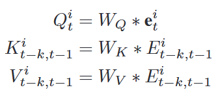 ,最终输出为:
,最终输出为: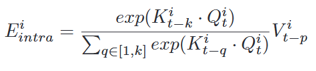 。区域间聚合受到两个观察的启发。一是不同地区不同波次的流行病学过程可以大体相似。因此,其他地区过去的趋势是预测的良好参考。二是某些地区的COVID-19爆发可能会稍早一些,可以在较短的特定窗口内为其他地区提供指导。由此,论文设计了区域间聚合模块来识别与当前趋势相似的历史趋势,并关注这些趋势以预测下一个数据点。利用Transformer的多头注意力找到空间和时间上的时间依赖性,如图6所示。对于L个区域,每个区域有T个时间步长,共有L*T个条目。使用时间步长t嵌入作为查询,并将所有区域的时间嵌入展平作为要在注意模块中计算的键和值。公式如下:
。区域间聚合受到两个观察的启发。一是不同地区不同波次的流行病学过程可以大体相似。因此,其他地区过去的趋势是预测的良好参考。二是某些地区的COVID-19爆发可能会稍早一些,可以在较短的特定窗口内为其他地区提供指导。由此,论文设计了区域间聚合模块来识别与当前趋势相似的历史趋势,并关注这些趋势以预测下一个数据点。利用Transformer的多头注意力找到空间和时间上的时间依赖性,如图6所示。对于L个区域,每个区域有T个时间步长,共有L*T个条目。使用时间步长t嵌入作为查询,并将所有区域的时间嵌入展平作为要在注意模块中计算的键和值。公式如下: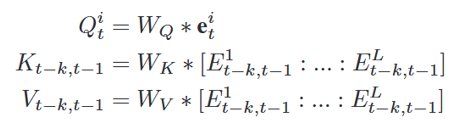 ,最终输出如下:
,最终输出如下: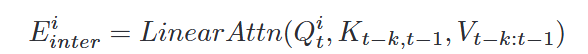 。 将所有历史信息映射到嵌入空间后,解码器消化嵌入并预测未来趋势。地理邻近性在流行病建模中也发挥着重要作用,地理位置相近的地区通常具有相似的阶段。论文将二维M×M网格中的所有位置都视为其中心位置的纬度和经度,采用相对位置偏差B∈RM2×M2 来表示网格之间的地理接近度。编码器的嵌入在短期预测方面表现得很好,但在较长的时间范围内很难很好地预测。为了解决这个弱点,需要通过某种机制来推断未来,而不是依赖历史经验。这需要对区域依赖关系进行密集建模。为了简化模型,论文假设疾病传播率与人口流动性相关,建立了一个因果模型来预测一个区域以其自身的流动性水平和所有其他具有流动性连接的区域为条件的未来趋势,公式如下:
。 将所有历史信息映射到嵌入空间后,解码器消化嵌入并预测未来趋势。地理邻近性在流行病建模中也发挥着重要作用,地理位置相近的地区通常具有相似的阶段。论文将二维M×M网格中的所有位置都视为其中心位置的纬度和经度,采用相对位置偏差B∈RM2×M2 来表示网格之间的地理接近度。编码器的嵌入在短期预测方面表现得很好,但在较长的时间范围内很难很好地预测。为了解决这个弱点,需要通过某种机制来推断未来,而不是依赖历史经验。这需要对区域依赖关系进行密集建模。为了简化模型,论文假设疾病传播率与人口流动性相关,建立了一个因果模型来预测一个区域以其自身的流动性水平和所有其他具有流动性连接的区域为条件的未来趋势,公式如下: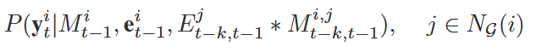 ,这里NG(i)表示移动图中i的所有邻居。此外,还部署了一个自注意力模块来处理移动连接区域之间的交互,分数的计算方式为:
,这里NG(i)表示移动图中i的所有邻居。此外,还部署了一个自注意力模块来处理移动连接区域之间的交互,分数的计算方式为: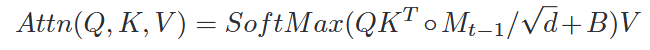 。
。4.4 损失函数
损失函数使用MAE和MAPE的组合: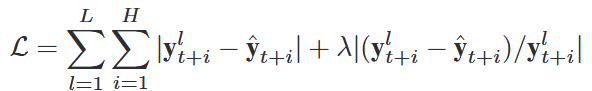
是预测范围的长度,λ是平衡两个损失项的权重因子。
5 实验
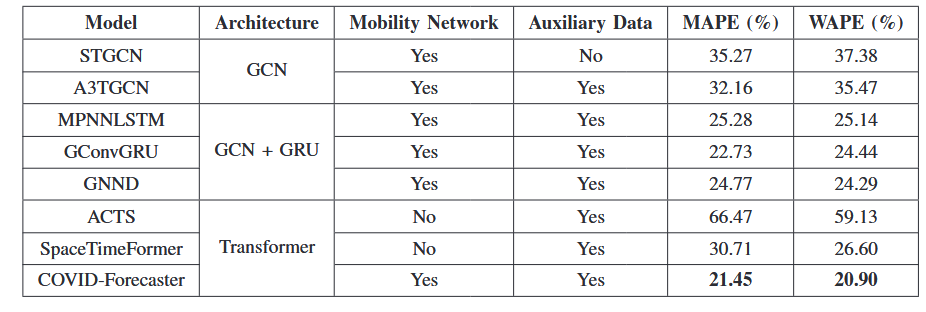
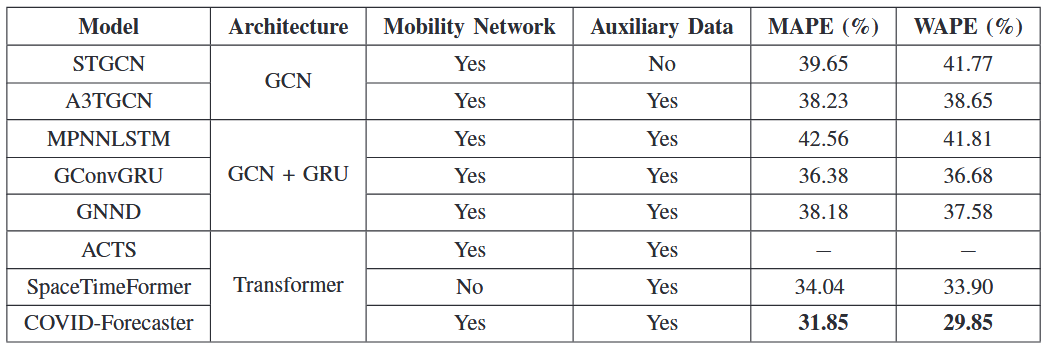
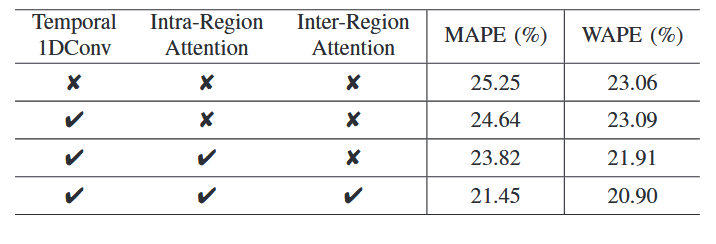
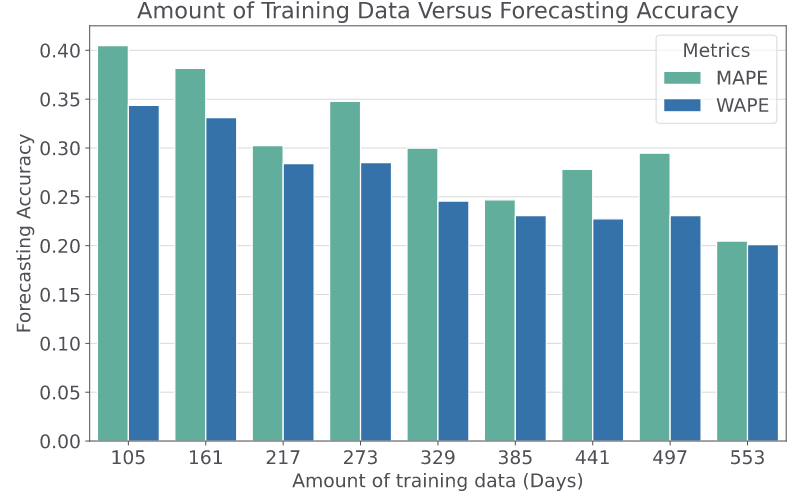
(2)实验环境:单个V100 32GB GPU。所有模型均使用 Adam 优化器进行训练,初始学习率为0.001,训练了100个epoch。(3)衡量标准:平均绝对百分比误差 (MAPE) 和权重绝对百分比误差 (WAPE) 。(4)基线:一系列基于机器学习的方法STGCN、A3TGCN、GConvGRU、GNND等。如表1所示,在县组层面,COVID-Forecaster明显优于其他算法,大致有6.0% MAPE和16.2% WAPE的提升。表2显示了在县级数据集上的结果。COVID-Forecaster的性能比所有其他基线有6.8% MAPE和13.5% WAPE的提升。且论文模型更有可能捕获工作日和周末之间急剧的COVID-19诊断变化,而其他GCN模型倾向于预测平滑曲线。此外,在县级数据集上对ACTS进行训练会导致内存不足,所以它不能很好地收敛。表1 COVID-Forecaster和基线模型预测未来7天县组级COVID-19动态的准确性 表2 COVID-Forecaster和基线模型预测未来7天县级COVID-19动态的准确性论文进行了多项消融研究,这里展示时间处理单元的消融研究。结果如表3所示,三个组件都对模型的最终性能有贡献,尤其是注意力模块。与基于GRU或GCN的方法不同,论文模型的注意力模块能够捕获长期时间依赖性,并能够从其他区域识别类似模式以供参考。论文还进行了不同地区的预测精度、数据集大小对性能的影响、粒度与模型性能、不同流行病阶段的模型表现等多项实验,这里仅展示其中几项。在每个实验种用前K∈ [105, 161, 217, ..., 553]天的数据作为训练集,并使用最后100天的数据作为测试集。结果如图7所示,在训练数据少于330天的情况下,更多的训练数据会直接带来更好的性能,而在训练数据超过330天的情况下,随着训练数据的增加,性能会趋于稳定。找到平衡细粒度和良好性能的最合适的粒度非常重要。论文使用九种不同的设置运行聚类算法,生成九个粒度级别,范围是将整个美国划分为150个县组,再将其划分为1800个县组。结果如图8所示,模型性能随着聚类的细粒度而降低。此外,县组数量较少时(N < 300),很难使同一县组中的所有县具有相似的流行趋势和阶段,此时聚类会损害数据质量并增加多个实验的方差。 预测COVID-19动态使政府机构和公共卫生管理者能够准备资源并采取措施抗击这一流行病。为了实现良好的预测准确性,模型需要捕获流行病动态中复杂的空间和时间依赖性,并考虑相关区域内和区域间信息的影响。为了应对这些挑战,论文提出COVID-Forecaster新深度学习模型,它采用广义时空注意力来捕获不同地区、不同时间的流行病动态之间的时间依赖性。还提供了一个通用框架来编码任何区域内和区域间信息,以更好地建模空间依赖性。此外,论文还研究了预测的粒度如何适应不同地区的特征,同时避免噪声的影响,也提供了一种聚类算法来找到合适的粒度。论文作者期待所提出的模型能够为人类社会抗击疫情的事业做出贡献。
李文慧 重庆大学计算机科学与技术(卓越)专业在读大四学生,重庆大学Start Lab成员。主要研究方向:时空数据挖掘 | 
|
重庆大学时空实验室(Spatio-Temporal Art Lab,简称Start Lab),旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有2~3名研究生名额,欢迎计算机、GIS等相关专业的学生报考!