





作者介绍
司马辽太杰,10余年数据库架构和运维管理经验,擅长常见关系型、NoSQL、MPP 等类型数据库。杭州桐庐县人,业余热爱历史、足球,偶尔读点闲书。欢迎关注个人公众号“程序猿读历史”,有需要联系的可以从公众号上扫码加我好友,感谢各位。
在分布式系统中,不同地理分布的副本节点因网络延迟、节点崩溃以及拜占庭崩溃(信息被篡改或伪造)等原因,影响系统副本间的数据不一致,从而带来系统的一致性与可靠性的问题。
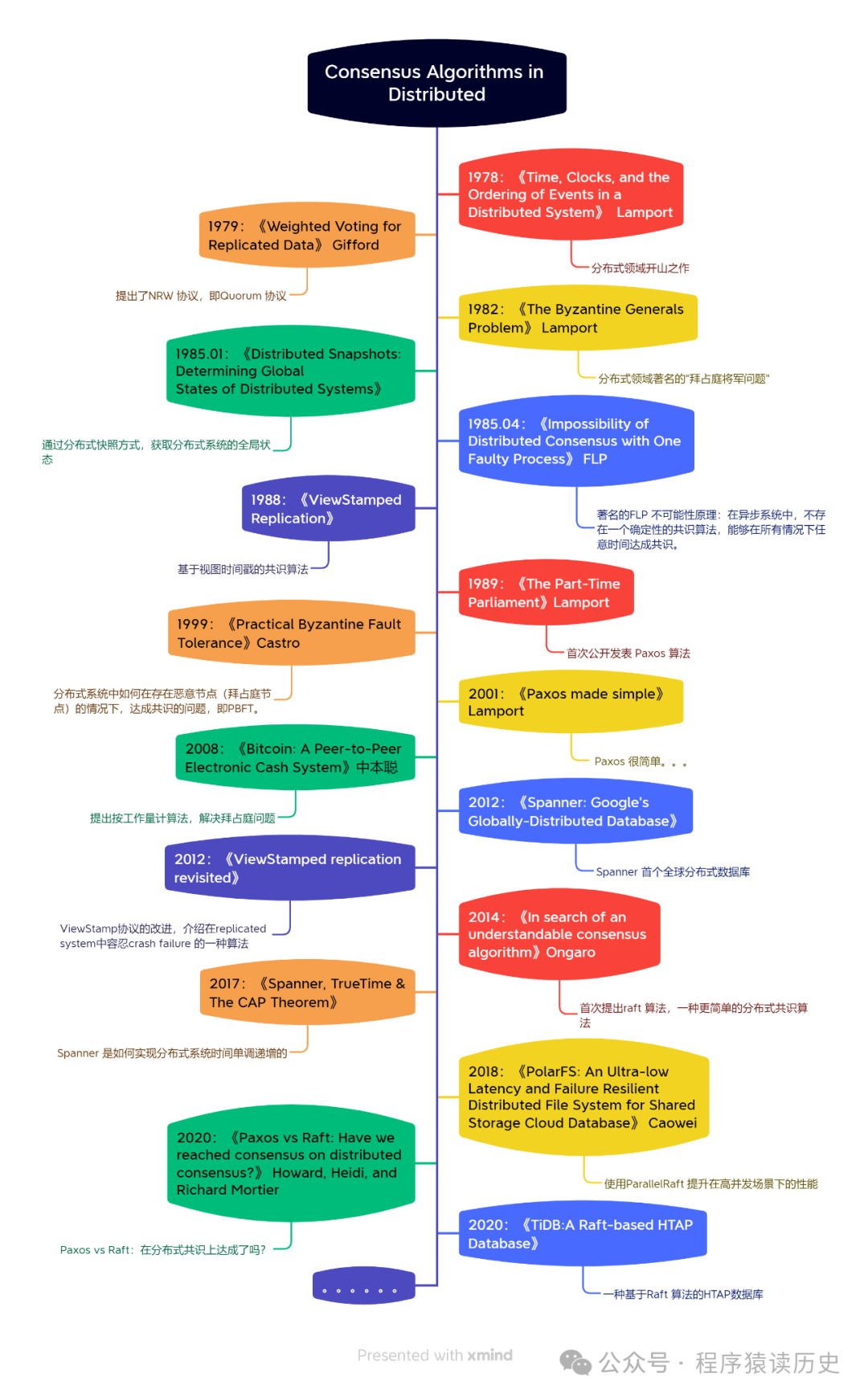
为解决分布式系统这一核心问题,自上世纪70年代 Lamport 提出逻辑时钟理论以来,研究者们相继提出了一系列理论模型与工程实践,包括崩溃容错法及拜占庭容错法,业内将这类算法称为共识算法(Consensus Algorithms)。它是基于数学可验证的协议流程,通过多轮通信与状态同步机制,确保分布式节点集群在异步网络与局部故障环境下,对某一确定性状态达成严格一致的全局共识。本文主要介绍分布式系统共识算法的发展历程,探讨 Paxos、Raft、PBFT、PoW等常见算法的实现原理及其特点,以及简单介绍Spanner、OceanBase、PolarDB、TiDB 等分布式数据库的共识算法实现。限于自身能力及知识储备,文中内容或存在一定局限性,还望读者海涵并予以指正。
主要参考论文

Lamport 在1978年发表的《Time, Clocks, and the Ordering of Events in a Distributed System》 一文,被称为分布式领域开山之作,并在 2007 年被选入 ACM SOSP 名人堂。Lamport 也因在分布式领域的卓越贡献,在 2013 年获得图灵奖,也被誉为“分布式计算之父”。
这篇文章主要探讨了分布式系统中事件时间顺序,重点介绍了时间(Time)、时钟(Clock)、事件排序(Ordering of Events)等概念,作者认为:
时间是一个物理学上的概念。在分布式系统中,每个事件发生都能在时间轴上找到某个数值。在的牛顿的经典力学中,时间是绝对的、独立的;在爱因斯坦的相对论中,时空是不可分割的,时间必须与空间一起讨论才有意义。
时钟分两种,一种是物理时钟(Physical Clock);另一种是逻辑时钟(Logical Clock)。物理时钟是时间的一种表示,然而因各种原因,现实中的物理时钟是有误差的。而逻辑时钟是跟物理时间无关的,是一个单调递增的数值。
分布式系统由很多进程组成,而一个进程可以看成是一个事件序列。不同的事件,可能具有先后关系,它们之间是能够排序的;也可能不同事件之间根本无法按照先后关系来排序,作者称之为偏序(Partial Ordering,直译应该是部分序),用符号“→”来表示。
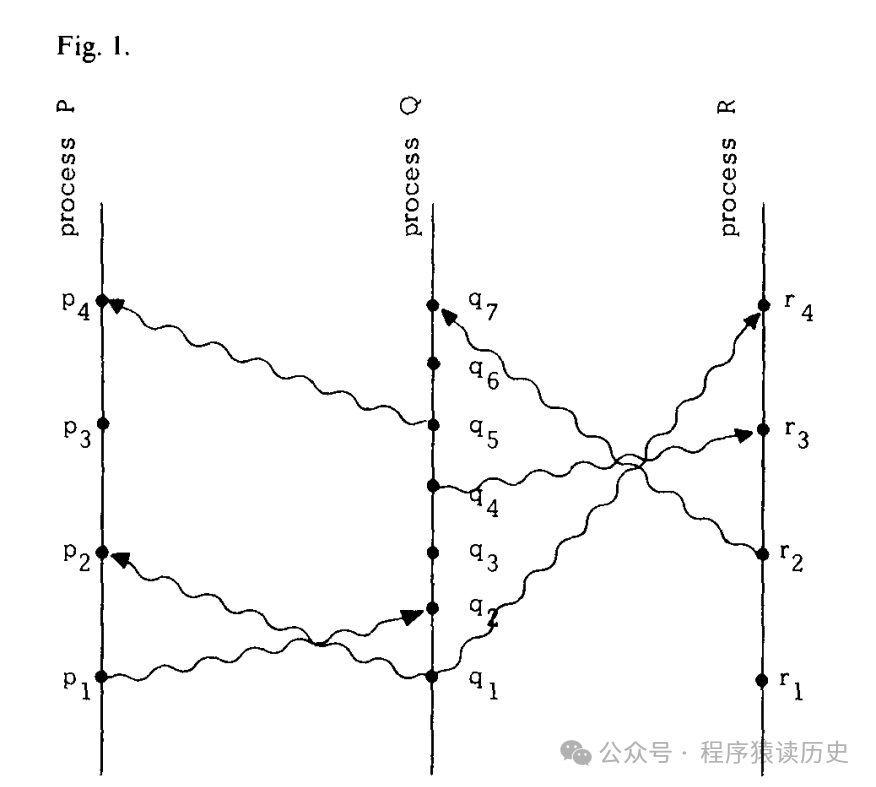
如何理解偏序?可以用上图来理解偏序的概念。图中水平方向表示空间,垂直方向表示时间——较早的时间在下方,圆点表示事件,竖线表示进程,波浪线表示消息。由图可知:
同一进程内部先后发生的两个事件之间,具有偏序关系。比如,在进程Q内部,q2表示一个消息接收事件,q4表示另一个消息的发送事件,q2排在q4前面执行,所以q2 → q4。
同一个消息的发送事件和接收事件,具有「Happened Before」关系。比如,p1和q2分别表示同一个消息的发送事件和接收事件,所以p1 → q2;同理,q4 → r3。
偏序满足传递关系。比如p1→ q2,q2 → q4和q4 → r3,可以推出p1→ r3。
对于不具备偏序关系的p2 → q2 以及q2 → p2,称之q2 和 p2 为并发。
由上可知,偏序关系能够为单进程内部的事件,以及分布式系统中不同节点(或者进程)间的事件进行排序,而对于进程之间的并发事件无法排序。多年后,Google Spananer 通过 TrueTime 实现全球数据库时间单调递增的理论依据。
作者凭借对相对论深刻的理解以及分布式系统全面的思考,除了提出偏序概念外,还提出了逻辑时钟、物理时钟、异常行为、状态机复制等理论,奠定了分布式计算领域内事件排序理论的基础,为其后的发展提供了关键性的思想和理论支持,极大地推动了分布式系统的研究与实践进步。
限于篇幅和能力,除偏序概念外,其他相关概念强烈建议阅读论文原文。只有理解了这篇论文中“时间、时钟和事件排序”的概念,才能在分布式系统的设计时游刃有余。
通过前面介绍可知,Lamport 《Time, Clocks...》一文并没有直接给出保障数据一致性解决方案,直到 1979 年 Gifford 在《Weighted Voting for Replicated Data》 提出了 Quorum 一致性协议,才明白分布式系统在工程上如何保证数据一致。Quorum 核心思想是通过对参数 N(集群副本数)、W(写成功节点数)、R(读成功节点数)的数学关系的控制,实现分布式系统各副本数据一致性,又称 NWR 多数派协议。
当满足 W + R > N 时,系统通过鸽巢原理保证读写操作交叉,从而每次读取的R个节点中必然包含至少一个最新写入的节点,再结合每个节点数据的时间戳或版本号机制,即可从多个节点中找到最新数据的节点,从而实现数据的一致性。由上可知,Quorum 协议并不能保证数据强一致,允许短暂的数据不一致,但通过多数派和版本号确认,最终系统逐步达成一致。
当 W + R > N 且 W > N/2 时,即写入超过半数节点,此时分布式系统在保障数据一致性的同时还能实现 写入顺序一致性 。如何理解写入顺序一致呢?假设两次写入操作 W1 和 W2,由于 W > N/2,因此每次都要覆盖半数以上的节点,根据鸽巢原理原理,两次写入的副本集合必然存在至少一个公共节点。这个公共节点会记录两次写入的顺序(如通过版本号或时间戳),从而确保所有节点最终以同一顺序应用写入。
当 W = N、R = 1 时,整个系统变成 Write all read one(WARO)控制协议。此时,系统每次更新确保所有副本都写入成功,查询则可以从任意一个节点读取数据。WARO 保证了所有节点的数据一致,系统具有很强的一致性,也提高了数据查询性能,但降低数据写入性能,同时任意一个节点数据写入异常,都会导致整个系统的不可用,也降低了系统可用性。
Quorum 协议是一种通过对每个副本赋予投票权,读写操作需满足最小票数要求,即 W + R > N ,能保证分布式系统中副本的数据一致性;当节点 W + R > N 且 W > N/2 时,满足副本的数据顺序写入,避免数据冲突。
如果需要调整分布式系统的读写性能,可通过改变 W/R 值实现。提升写性能可降低 W,但需提高 R 以保证一致性,反之亦然。Gifford 在70年代末提出该协议后,为后来的分布式一致性算法,如Paxos、Raft、BFT(拜占庭容错)等奠定了理论基础。
由前两节可知,分布式系统可通过事件排序、以及多数派协议,保证各副本数据一致。而在现实世界中,分布式系统不仅可能遇到因网络原因的节点失联或者崩溃,还可能是节点信息被篡改等问题。
根据这两种不同故障,共识算法也分为两大类:一类是针对节点崩溃设计的崩溃容错(Crash Fault Tolerance, CFT),常见的有Paxos、Raft、ZAB等;一类是处理包括节点崩溃以及被篡改在内的更复杂故障情形而设计的拜占庭容错(Byzantine Fault Tolerance),常见的有PBFT、PoW等。
崩溃容错法:系统中的节点可能会突然停止工作的情况,但这些节点不会发送错误的信息,只是失效或变得不可用。
拜占庭容错法:系统中不仅包括节点崩溃,还包括可能发送错误信息、伪造信息或表现出任意异常行为的恶意节点。比如在完全去中心化的比特币,就有可能出现信息篡改的恶意节点。
本节主要讨论崩溃容错中的Paxos、Raft算法,下节讨论拜占庭容错相关算法。
Paxos
Paxos 几乎成了分布式系统数据一致性算法的代名词,他的发明人依旧是 Lamport 。早在上个世纪80年代末,Lamport 完成了《The Part-Time Parliament》一文提出了Paxos 算法(标题直译“兼职议会”,paxos 一词是作者虚构古希腊爱琴海的一个小岛,该岛管理方式介绍 paxos 算法的实现过程)。由于文章过于晦涩,直到 1998 年才公开发表,但其难以理解和晦涩的内容,并没有产生影响力。到了 2001 年,Lamport 使用相对简练的语言和逻辑,把主旨又重新阐述了一遍,于是又发表了《Paxos made simple》一文。
由于Paxos 在互联网上有广泛的出镜率,本文将简单介绍,有兴趣想要深入了解该算法的,读者可以自行搜索相关内容及 Lamport 两篇论文。
Paxos算法包含三种角色,分别是提案者(Proposer)、接受者(Acceptor)、学习者(Learner)。提案者提出提案,提案信息包括提案编号和提案值;接受者接收到提案,若提案获得多数接受者的接受,则该提案被批准;学习者只能学习被批准的提案。每个节点可扮演多种角色。其两个主要分为Prepare 阶段和Accept 阶段。
Prepare 阶段:
提案者(Proposer)选择一个唯一的提案编号,并向所有接受者(Acceptor)发送 Prepare(n) 请求。
每个接受者收到 Prepare(n) 请求后,如果该编号不小于其之前见过的所有编号,则接受者承诺不再响应小于 n 的提案请求,并回复 Promise(n, v),其中 vv 是接受者已经接受过的最高编号的提案值。
Accept 阶段:
提案者收到大多数接受者的 Promise(n, v) 响应后,选择一个值 v 进行提案。如果所有响应中的 v都为空,则提案者可以自由选择一个值;否则,选择其中最高的编号对应的值。
提案者向所有接受者发送 Accept(n, v) 请求。每个接受者收到 Accept(n, v) 请求后,如果该编号 n 不小于其之前承诺的最大编号,则接受者记录下该提案并回复 Accepted(n, v)。
提案者或独学习者(Learner)收集到大多数接受者的 Accepted(n, v)响应后,确认该提案已达成共识,并通知其他节点
Paxos 在理论上解决了多副本之间数据一致性问题,也能在主节点出现故障后重新选主节点或在多节点之间实现数据同步等,但其本身难以理解,工程实现上也存在巨大挑战,在提出的很长时间并不行业重视。直到 Google 的 Chubby 系统出现,Paxos 才逐步成为行业主流。在 Chubby 之后,Google Spanner、Microsoft Azure、Amazon DynamoDB、OceanBase 等分布式数据库,均采用了Paxos 或其变种算法保证分布式各副本间的数据一致性。
Raft
2014年,斯坦福大学教授 Diego Ongaro 在其《In search of an understandable consensus algorithm》 一文中指出:
Unfortunately, Paxos has two significant drawbacks.The first drawback is that Paxos is exceptionally difficult to understand...The second problem with Paxos is that it does not provide a good foundation for building practical implementations.
翻译:不幸的是,Paxos有两个明显的缺点。第一个缺点是Paxos非常难以理解.......Paxos的第二个问题是,它没有为构建实际实现提供良好的基础。
Diego Ongaro 提出了一种更容易理解、工程落地的分布式一致性算法——Raft。Raft 可分为领导者选举、日志复制和安全性三大块,先通过选举产生一个领导者,由领导者协调日志管理,从而大大简化了 Paxos 中的状态考虑,增量可理解性,降低了工程实践难度。
Raft 集群中的节点可分为三类,分别是 领导者(Leader)、跟随者(Follower)、候选人(Candidate)。和Paxos 不同的是,Raft 中通常领导者节点只有一个,其余节点均为跟随者。领导者负责管理副本日志,接受客户端的请求后,将请求同步到各个跟随者,在安全时告知所有跟随者应用请求。如果领导者故障,则跟随者会选出新的领导者。跟随者资深不发送任何请求,只负责处理领导者的安排以及选举新的领导者。
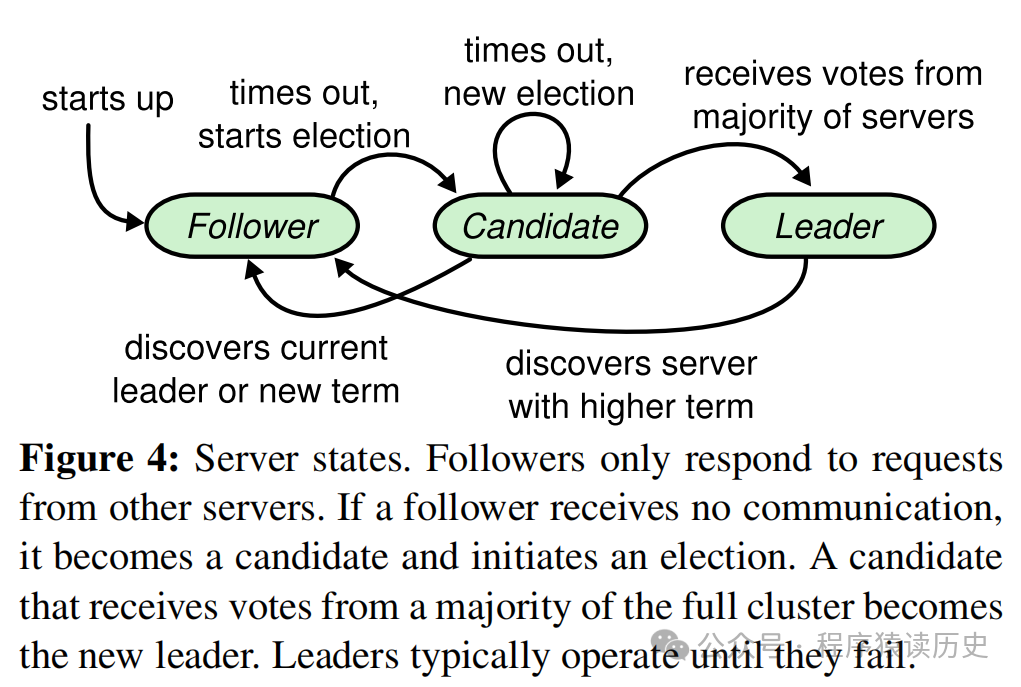
Raft 三者关系转换图,图来自Raft Paper
Raft 的领导者选举是通过节点间的心跳触发。系统一开始,每个节点都是跟随者。系统开始启动时,所有节点均为跟随者,此时和领导者通过 RPC 交互超时,跟随者变为获选人,并给自己投票并将投票请求发生给其他的跟随者,每个跟随者都会获得多个投票请求,按照先到先得原则透出一票,并且候选人所有拥有的日志信息不能比自己更早。
在选出领导者后,分布式系统开始对外提供服务。领导者开始处理来客户端的请求,每个请求包含一个作用于副本状态机的命令。领导者将每个请求封装成日志,追加到日志尾部,同时将日志按顺序并行的发给所有跟随者。每个日志包含状态机命令和领导者收到该请求时的当前任期号,以及该日志的在文件中的位置索引。当日志被安全的复制到多数跟随者后,该日志被提交,领导者向客户端返回给请求,并通知各跟随者按照相同顺序将日志中的命令应用到复制状态机中。
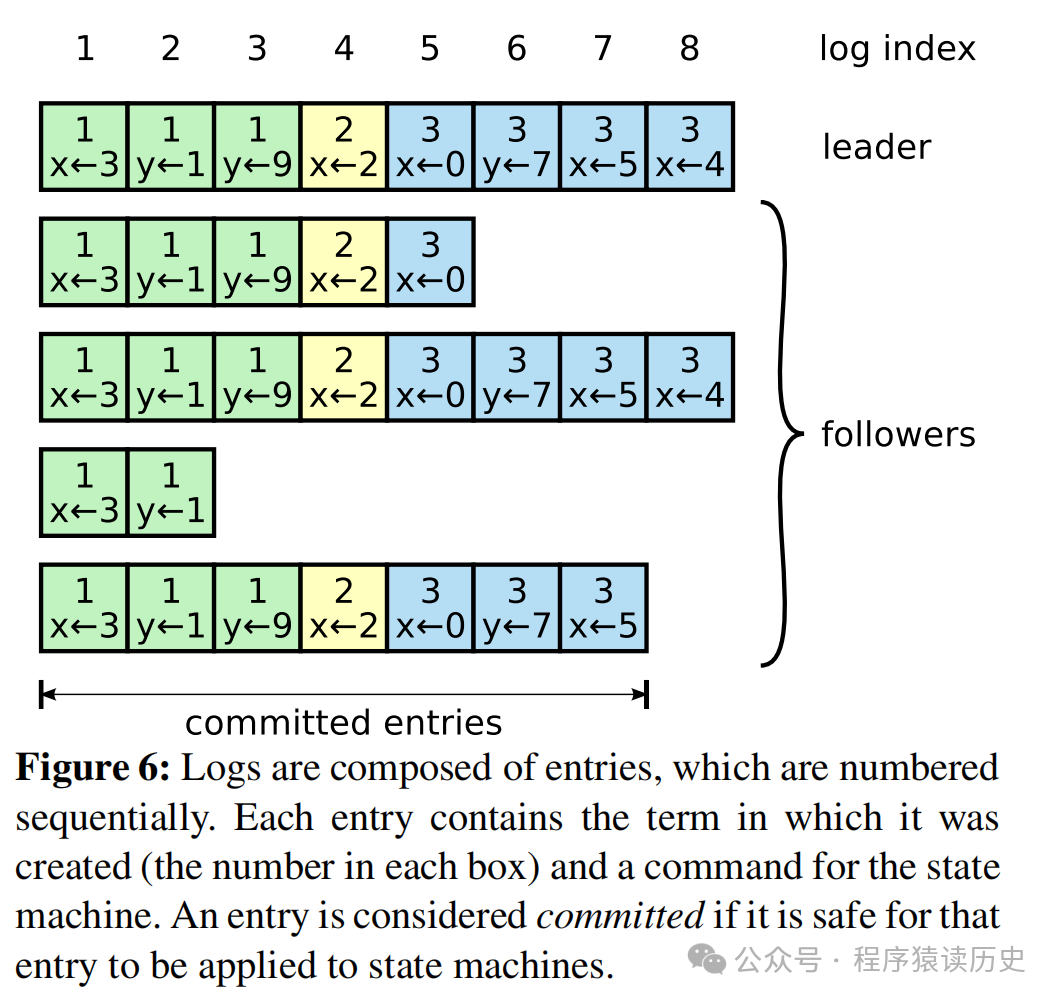
Raft 日志复制过程,图来自Raft Paper
Raft 算法是一个标准的多数派协议,最多能容忍 n/2 - 1 个节点崩溃故障,领导者会为异常的跟随者补完日志。跟随者的日志补充是通过两者一致的索引位置实现。此外,领导者还为每个跟随者维护了一个 nextindex,用来表示领导者将要发生给每个跟随者的下一条日志条目索引。
以上就是 Raft 的简要介绍。相比 Lamport 的paxos 算法,两则都是通过多个阶段的通信协议,确保即使在网络不稳定或部分节点失效的情况下,实现分布式系统的一致性。然而,Paxos 的复杂性和晦涩难懂的描述,使其学习成本大、工程实践难。但由于发展较早,又有 Google、AWS 等大厂的产品背书(其实相关产品并没有公开如何实现 Paxos 算法,只是宣传实现了)paxos 的知名度更高。
相比之下,Raft 是为了简化共识算法的理解和实现而设计的,它通过清晰的角色划分(领导者、跟随者和候选人)和明确的状态转换流程,以及将复杂的共识问题分解为几个相对独立的子问题,如领导者选举、日志复制和安全性保障,从而大大降低了学习曲线和实现难度,国内的 PolarDB、TiDB 产品均使用该算法实现分布式数据库副本间的数据一致性。
在介绍拜占庭容错法前,先要了解拜占庭问题。1982年,前面多次提到的分布式大神 Lamport 发表《The Byzantine Generals Problem》一文,提出了“拜占庭将军之问”,那什么是拜占庭将军问题呢?
拜占庭将军问题
拜占庭帝国因幅员辽阔,军队被分成了多支小分队,每支小分队由一个将军领导。这些将军们彼此之间只能依靠信使传递消息,每个将军在观察自己方位的敌情以后,会给出一个各自的行动建议,比如进攻、撤退。但最终将军们会根据少数服从多少,达成一致的作战计划并共同执行,否则就会被敌人各个击破。但是,这些将军中可能有叛徒,他们会破坏将军达成一致的作战计划。
为了确保所有忠诚的将军能够作出一致的决定,必须设计一种策略,使得即使一部分将军(忠诚将军必须大于三分之一)受到了叛徒的影响,其余忠诚的将军依然能达成一致的决定。这就是“拜占庭将军问题”的核心思想:即一个分布式系统,能够容忍一部分节点出现故障或者被篡改等问题时,整个系统仍然能够正确地达成共识。
拜占庭将军问题的经典应用场景便是区块链技术。在区块链中,因为网络中的节点可能存在恶意或故障节点。通过解决拜占庭将军问题,区块链确保了即使部分节点出现异常行为,整个系统依然能够维持数据的一致性和安全性。
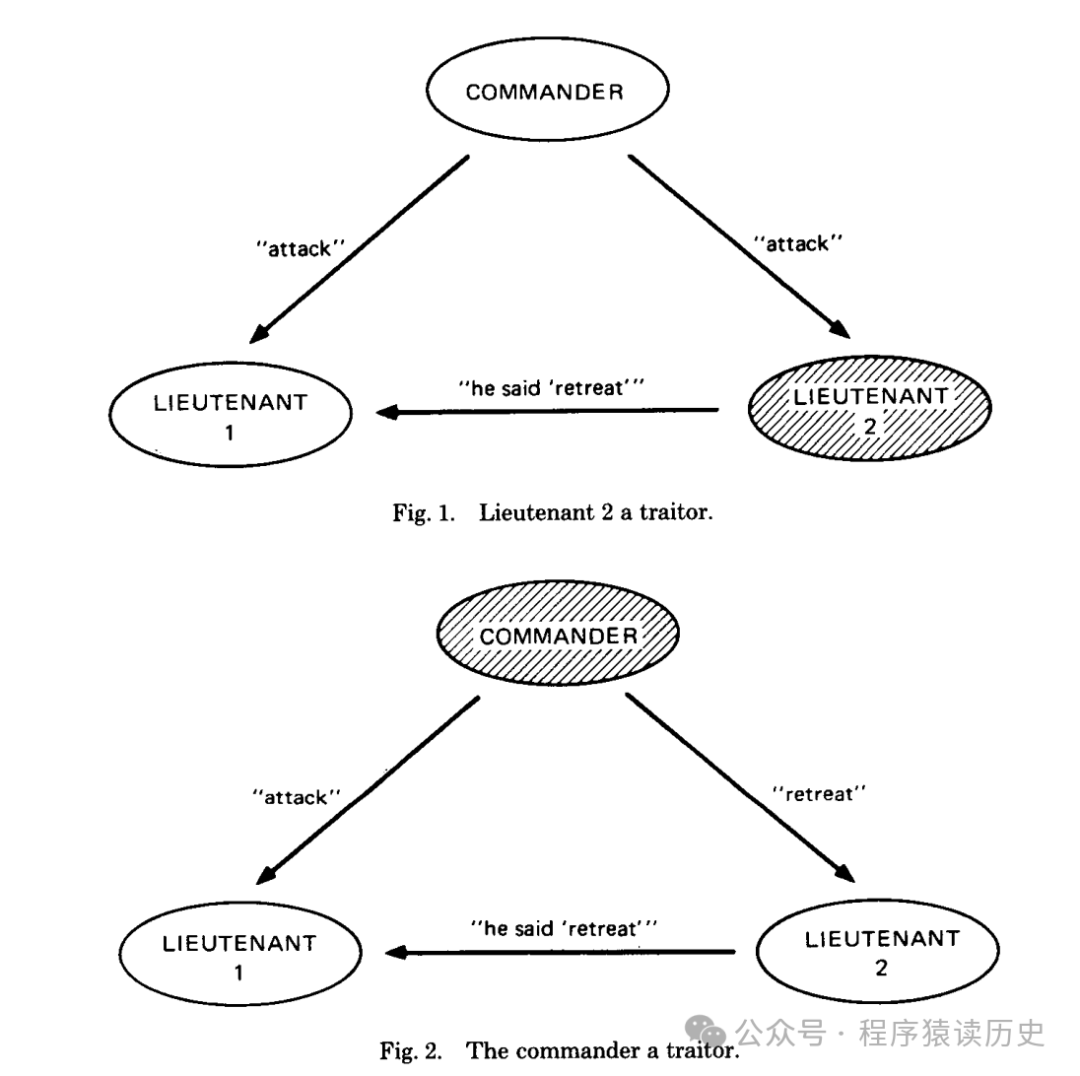
三节点系统出现一拜占庭节点,无法容错。图来自Paper
Lamport 在《The Byzantine Generals Problem》文中也给出了两个解决方案:
口头消息的解决方案(A solution with oral message)
签名消息的解决方案(A solution with signed message)
这两个方案更多是理论层面的模型,在实际分布式系统中,很难严格满足口头消息的传递条件,以及签名消息方案对系统的加密基础设施要求。另外,这两种算法在通信复杂度、工程落地上也存在较大难度。
PBFT
1999年, Castro 和 Liskov 发表了《Practical Byzantine Fault Tolerance》一文,提出了经典拜占庭容错共识算法,即PBFT。
PBFT 是基于节点之间多轮消息交换的确定性算法,分布式系统总节点数 n ≥ 3f+1 个,可在最多容忍 f 个恶意、崩溃节点情况下,分布式系统仍能达成共识。通过预准备(Pre-Prepare)、准备(Prepare)和提交(Commit)三阶段的交互,确保所有诚实节点对某个操作或状态变更达成一致。
客户端发送一个请求给主节点(Primary);主节点接收客户端的请求后,会给该请求分配一个序列号,并将包含序列号和请求内容的消息广播给所有的副本节点(Replicas),这为预准备阶段;当副本节点接收到预准备消息后,会进行验证。如果验证成功,副本节点会向其他所有节点发送准备消息。一旦一个副本节点从其他节点收到了足够数量(至少2f+1,其中f是可能的最大拜占庭节点数)的准备消息,它就进入了准备状态;客户端需要等待来自不同副本节点的足够多的响应(至少 n-f 个,n 是总节点数,f 是最大可能的拜占庭节点数),并且这些响应必须是一致的,这样客户端才能认为操作已经成功完成

拜占庭问题节点响应流程
PBFT 的好处是只要系统中有不超过1/3的节点是拜占庭节点,可以通过上述机制可以保证所有诚实节点实现共识。即使主节点失效或者成为拜占庭节点,系统也能够通过视图更换(View Change)协议选举新的主节点继续工作,从而保证系统的持续运作。关于视图更换的过程,限于篇幅不在此赘述,建议阅读论文原文。
PBFT 的缺点是扩展性较差,因为每个节点都需要与其他节点通信以达成共识,导致随着节点数量的增加,通信开销呈指数级增长。此外,他并没有做到去中心化,常用于区块链中的联盟链或私有链环境。因为在这些环境中,节点的数量通常是固定的,并且所有节点都需要被信任或经过认证。
PoW
2008年,神秘人物中本聪发表《Bitcoin: A Peer-to-Peer Electronic Cash System》一文,介绍了一种全新的、去中心化货币——比特币,提出了 Proof of Work(POW,工作量证明)算法,并且该算法支持完全无中心节点且不知道有多少拜占庭节点情况下,解决拜占庭将军问题。
在比特币中,PoW 算法要求矿工解决复杂的数学问题,而解这个数学问题需要大量的计算资源才能找到答案。同时,又要求所有节点遵循最长链原则。这样的设计,对于比特币来说,攻击者需要控制超过网络总计算力50%以上的算力才能进行所谓的“51%攻击”,即有能力改变交易。
PoW 算法有效地抵御了恶意攻击,特别是当网络足够大且分布广泛时,攻击成功的可能性几乎可以忽略不计。但由于挖坑过程中,需要进行大量算力和电力资源,这种高资源消耗的方法也称为一个争议点。对于PoW 算法笔者也不甚了解,有兴趣的读者可以阅读论文原文以及相关著作。
Spanner Paxos
Spanner 是Google的分布式数据库 (Globally-Distributed Database) ,其扩展性达到了令人咋舌的全球级,可以扩展到数百万的机器,数以百计的数据中心,上万亿的行。
Spanner is designed to scale up to millions of machines across hundreds of datacenters and trillions of database rows.——《Spanner: Google's Globally-Distributed Database》除了夸张的扩展性,Spanner 通过 Paxos 算法、TrueTime 和多版本来满足外部事务一致性以及水平扩展能力,极大的提高了系统的可用性、扩展性。由于 Spanner 并不是开源数据库,论文中也没有详细介绍Paxos 的实现过程。大致了解它主要使用 Paxos 管理数据分片(Splits)的跨区域复制,每个数据分片对应一个独立的 Paxos 组,组内通过选举领导者处理写请求,其他副本支持读请求。此外,Spanner 还通过双重日志存储、流水线化处理等方式来增强容错能力、提升高并发场景的吞吐性能。
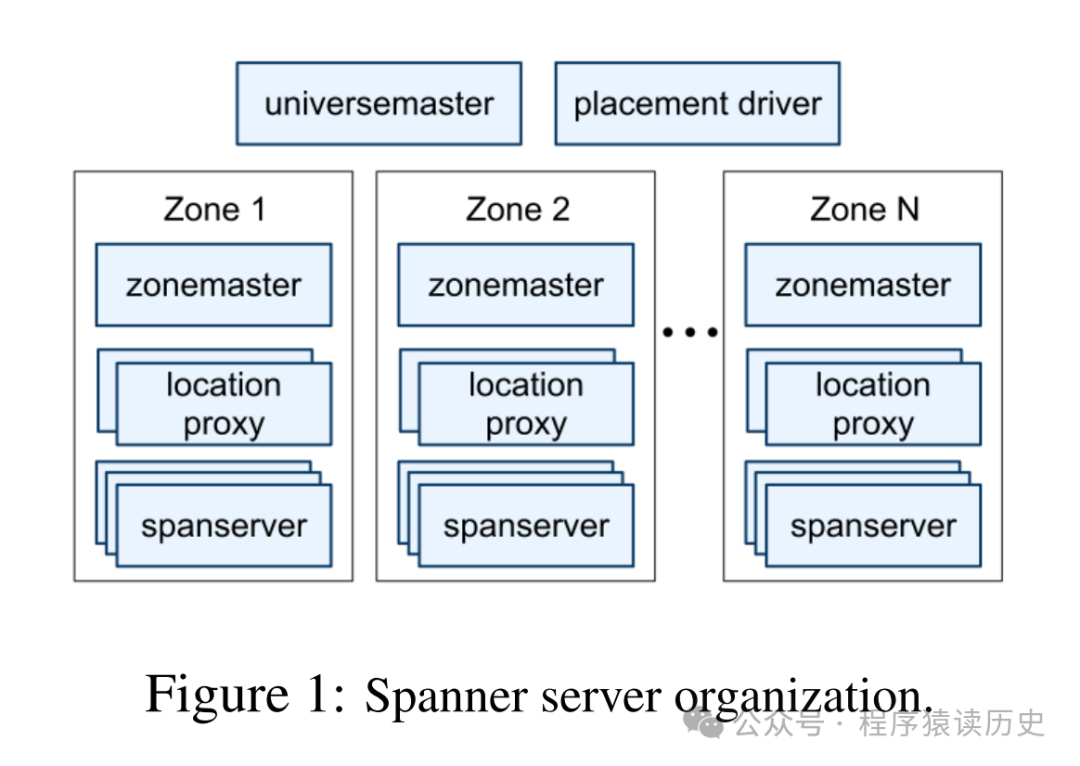
Spanner 架构图,图来自 Google Paper
Spanner 架构包括一个Universe 实例,按生产、开发、测试分共有3个 Universe,一个Universe 又包含多个物理隔离的 Zone,每个 Zone 又部署若干个 Spanserver 节点。Placement Driver 负责处理 Spanserver 的数据迁移以及元数据管理。
数据库中的数据按键值范围划分为 Tablet,每个 Tablet 对应一个 Paxos 组,支持跨多个 Zone 同步复制。领导者副本负责处理写操作,通过两阶段提交(2PC)协调跨分片事务。非领导者副本支持强一致性读,缓解领导者负载。当分片数据量或请求负载超过阈值时,系统自动将其拆分为更小的 Splits,并通过 Placement Driver 组件重新分布到不同 Zone。
OceanBase Paxos
OceanBase 最早诞生于阿里巴巴和蚂蚁集团的一款企业级、高性能、高可用的分布式数据库,基于 Paxos 协议的多副本同步算法,保证数据多个副本之间的一致性,并在机器硬件故障时快速切换。OceanBase 不仅作为国产数据库首次刷新了被誉为“数据库领域的奥运会”的 TPC-C 和 TPC-H 世界纪录,而且还是全球唯一一家同时打破并夺得 TPC-C 和 TPC-H 这两项世界纪录的分布式数据库。
从OceanBase 架构图可知,它主要由 OBProxy、OBserver 组成,每个 OBServer 节点内都包含 SQL 引擎、事务引擎、存储引擎,节点间的能力对等。
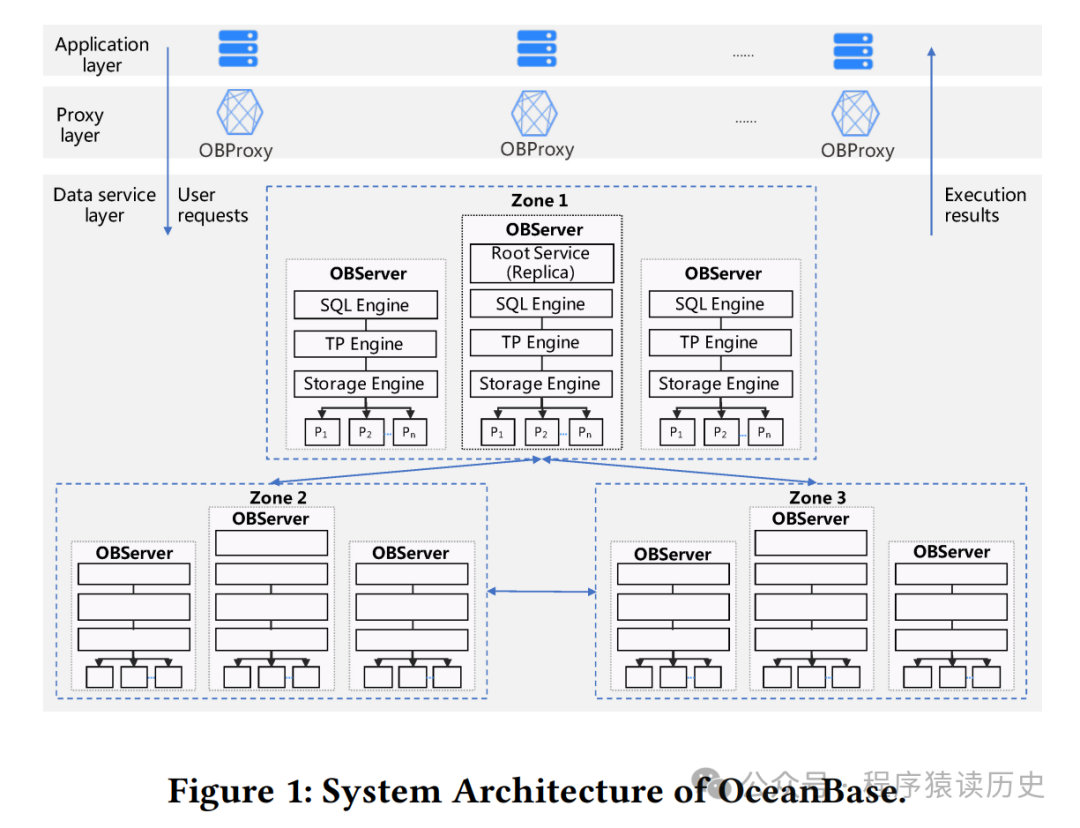
OceanBase 架构图,图来自OceanBase Paper
在OceanBase 数据库中,一个表的数据可以按照某种划分规则水平拆分为多个分片,每个分片叫做一个表分区,简称分区(Partition)。数据库中的某行数据属于且只属于一个分区,每个物理分区有一个用于存储数据的存储层对象,叫做 Tablet 。在更新数据时, Redo 日志到 Tablet 对应的日志流(Log Stream,LS)中,每个日志流及其所属的 Tablet 有多个副本。多副本中有且仅有一个副本接受修改操作,叫做主副本(Leader),其他副本是从副本(Follower)。
根据介绍,OceanBase 采用了不同于经典 Paxos 算法的 Multi-Paxos 进行日志数据同步,为每个分区的多个副本创建 Paxos 日志组进行日志和状态同步,从而实现不同副本之间的数据一致性。当主副本所在节点发生故障时,一个从副本会被选举为新的主副本并继续提供服务。
另外,OceanBase CTO 曾在 2021年一文中发表一观点:Paxos 是比 Raft 更高效、更安全的一致性算法。详见文章链接 。
PolarDB ParallelRaft
PolarDB 是阿里云自研的新一代云原生数据库,在计算存储分离架构下,利用了软硬件结合的优势,具备秒级弹性、高性能、海量存储、安全可靠等特性。蛇年前夕,PolarDB 登顶全球数据库性能及性价比排行榜,超越原纪录2.5倍的性能一举登顶TPC-C基准测试排行榜,以每分钟20.55亿笔交易(tpmC)和单位成本0.8元人民币(price/tpmC)的成绩刷新TPC-C性能和性价比双榜的世界纪录。
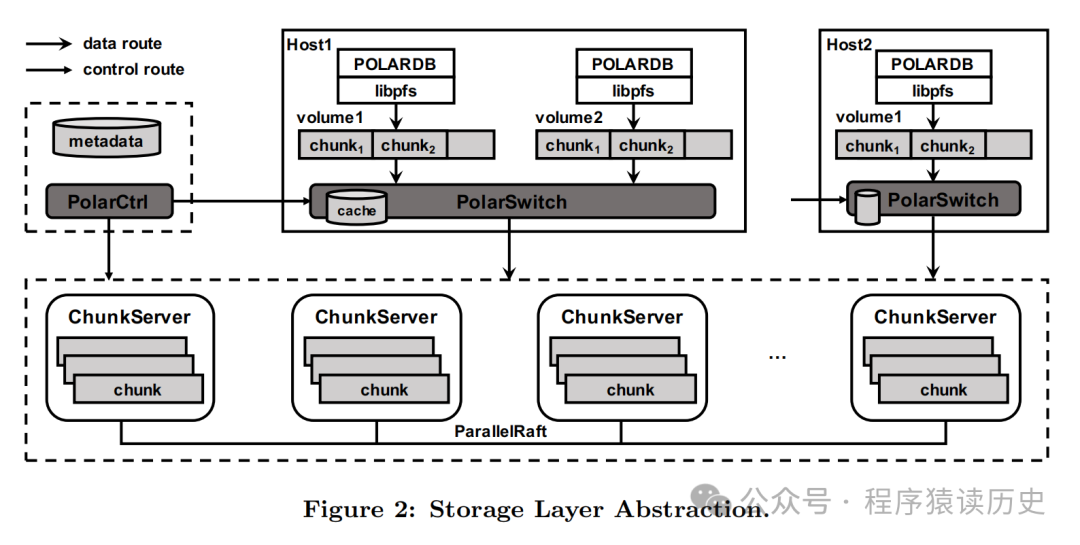
PolarDB 架构图,图来自PolarDB Paper
PolarDB 各副本之间数据一致性依赖 ParallelRaft 算法实现,通过打破串行化的限制、并行执行等优化措施了,提升了高并发场景的性能。根据介绍,ParallelRaft 引入了一种新型数据结构: Look Behind Buffer,该结构中存放了前面日志项修改的逻辑快地址信息。通过 LBB 结构,,各副本知道日志项是否有冲突或缺失,从而解决各副本之间日志项缺失、串行执行等问题。
TiDB Raft
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,具备水平扩容或者缩容、金融级高可用、实时 HTAP、百分百兼容 MySQL 生态等重要特性。根据其架构图介绍,TiDB 主要包括 PD 元数据管理组件,TiDB Server SQL 层组件,以及TiKV 和 TiFlash 两类存储引擎组件。其中TiKV 作为主要存储引擎,支持OLTP业务;TiFlash 通过列存,支持OLAP。两类引起之间,通过事务日志 CDC 实现数据同步。
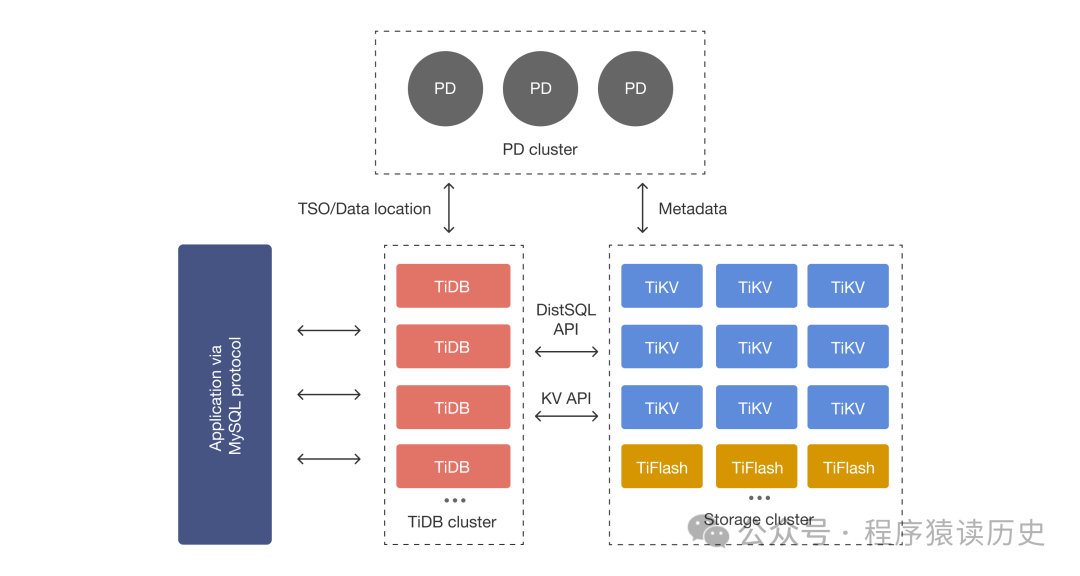 TiDB 架构图,图来自TiDB Dcoument
TiDB 架构图,图来自TiDB Dcoument
根据 TiDB 文档介绍,TiKV 存储引擎利用 Raft 来做数据复制,每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据安全可靠地同步到复制组的每一个节点中。不过在实际写入中,根据 Raft 的协议,只需要同步复制到多数节点,即可安全地认为数据写入成功。
2020年,TiDB 团队发表《TiDB:A Raft-based HTAP Database》一文,介绍了 TiDB HTAP 的能力实现原理。文章介绍 TiDB 通过Raft算法,保证行存多副本数据一致;新增一个 Learner 节点,以列存形式存在,Learner 节点和 Leader 通过 Raft 算法实现数据一致。行存实现OLTP,列存实现OLAP 能力,从而TiDB 具备 HTAP 能力。
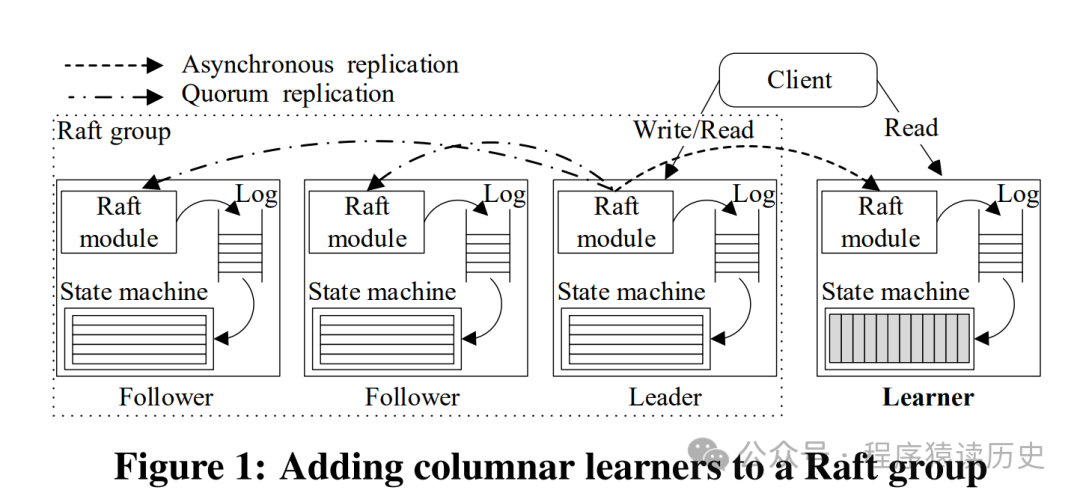
TiDB HTAP 架构图,图来自TiDB Paper
回顾本文可知,分布式系统中共识算法自上世纪 70 年代末发展至今,已成为保障系统可靠性、一致性与可用性的关键所在。从 Lamport 提出逻辑时钟理论开启分布式领域研究大门,到如今多种共识算法百花齐放,每一次突破都推动着分布式系统向前迈进一大步。
在崩溃容错方面,Paxos 虽晦涩难懂但奠定了理论基础,或许是发展较早,又或许是理论扎实,目前被众多大厂产品采用;而Raft 以其易理解、好实现的特性,成为后起之秀,在国内分布式数据库如 PolarDB、TiDB 中得到广泛应用。而在拜占庭容错方面,PBFT 通过多阶段交互确保系统在恶意节点存在时仍能达成共识,PoW 则在比特币中创造性地解决了去中心化场景下的拜占庭问题。
另外,崩溃容错法中以 ZooKeeper 基础的原子广播协议(ZooKeeper Atomic broadcast,ZAB),拜占庭容错法中不依赖大算力、更环保的权益证明(Proof of Stake,PoS)算法本文未涉及。
《Time, Clocks, and the Ordering of Events in a Distributed System》 Lamport
《The Byzantine Generals Problem》 Lamport
《Weighted Voting for Replicated Data》 Gifford
《The Part-Time Parliament》Lamport
《Paxos made simple》 Lamport
《Practical Byzantine Fault Tolerance》Castro
《Spanner: Google's Globally-Distributed Database》
《Bitcoin: A Peer-to-Peer Electronic Cash System》
《PolarFS: An Ultra-low Latency and Failure Resilient Distributed File System for Shared Storage Cloud Database》
《Spanner, TrueTime & The CAP Theorem》
《TiDB:A Raft-based HTAP Database》
《OceanBase: A 707 Million tpmC Distributed Relational Database System》
Spanner、OceanBase、TiDB、PolarDB Dcoumnet
《云原生数据库原理与实践》李飞飞等
