




问题描述
根据客户现场运维人员反馈新上的某业务对应的Flink作业经常定期异常退出,已有的历史Flink作业并没有这种现象。排查过JobManager日志提示心跳超时,现场人员曾经多次尝试调大过超时时间。但是,问题仍旧存在,日志如下:
java.util.concurrent.TimeoutException: Heartbeat of TaskManager with id container_**** timed out.at org.apache.flink.runtime.jobmaster.JobMaster$TaskManagerHeartbeatListener.notifyHeartbeatTimeout(JobMaster.java:1299)复制
详细查看本次故障任务对应的日志,发现除了上述心跳超时记录之外,日志还提示物理内存超分、被强制kill,记录如下:
beyond the 'PHYSICAL' memory limit. Current usage: 3.0 GB of 3 GB physical memory used; 6.1 GB of 6.3 GB virtual memory used. Killing container.Container killed on request. Exit code is 143Container exited with a non-zero exit code 143.复制
根据笔者经验,这种异常无外乎几种情况导致,细分如下:
1. TaskManager内存设置的不合理(过小),也就是不够用。
2. 业务逻辑存在内存泄漏的Bug,导致TaskManager内存溢出。
3. Flink框架自身存在内存泄漏的Bug,导致TaskManager内存溢出。
本文结合现场反馈,针对该作业逐步对上述情况展开排查,遂有此文!欢迎关注微信公众号:大数据从业者
问题分析
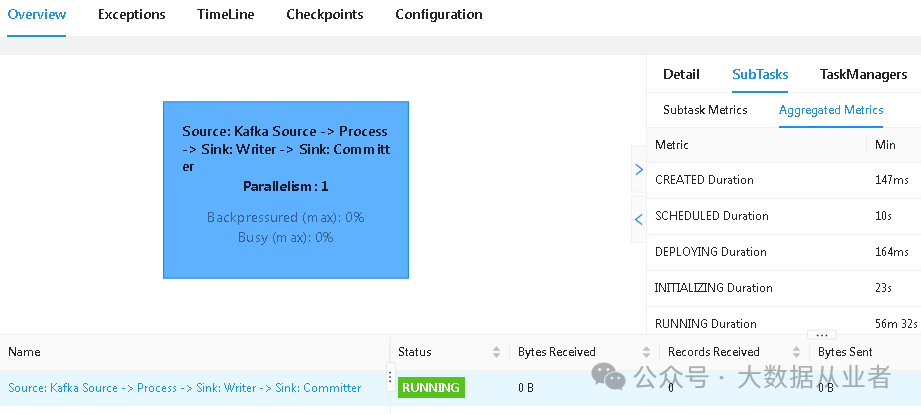
客户业务开发人员反馈该作业还在灰度阶段,入口数据未完全割接,目前只有极少数据进行灰度发布。并且,客户称业务逻辑很简单,不可能有问题。从发过来的业务代码对应的FlinkUI界面来看,确实很简单:
综合考虑现场情况:业务作业数据量小、逻辑简单、未引入任何第三方的jar,那么问题直指Flink框架自身了。既然怀疑Flink存在问题,那么直接开发启动一个Flink作业测试用例,保持运行状态过程时,通过命令生成堆转储,分析内存泄漏情况:
jmap -dump:live,format=b,file=heaplive.bin <pid>复制
测试用例见:
https://github.com/felixzh2020/felixzh-flink/tree/master/Kafka2Kafka复制
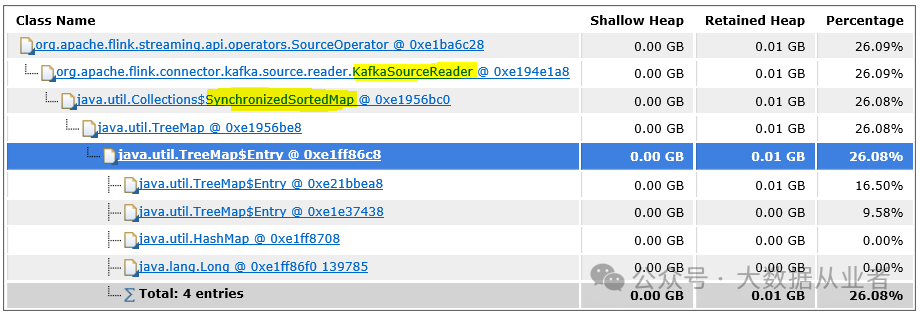
上述dump文件分析发现,即使源端Kafka没有业务数据,Flink作业KafkaSourceReader类中的SynchronizedSortedMap仍然存在大量数据,详见如下:
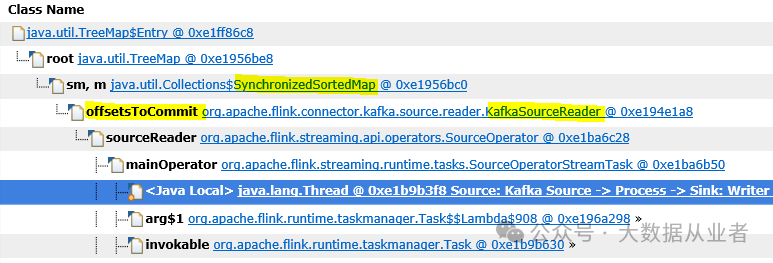
从相关源码来看,每次checkpoint触发时调用snapshotState方法会使用offsetsToCommit存储当前批次checkpoint期间已经完成读取Kafka的分区及对应offsets。
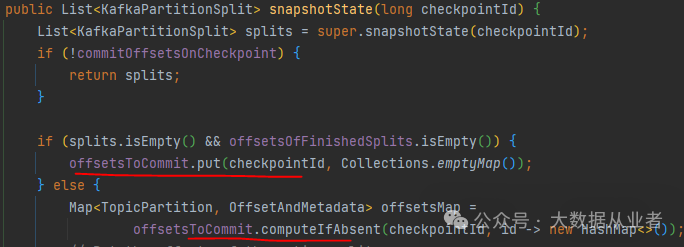
然后,在每次checkpoint成功时调用notifyCheckpointComplete方法、commitOffsets方法将offsets信息提交到Kafka。同时会清理上述offsetsToCommit中小于当前checkpointID的记录。
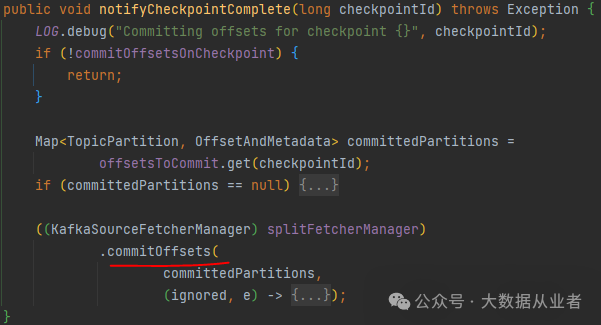
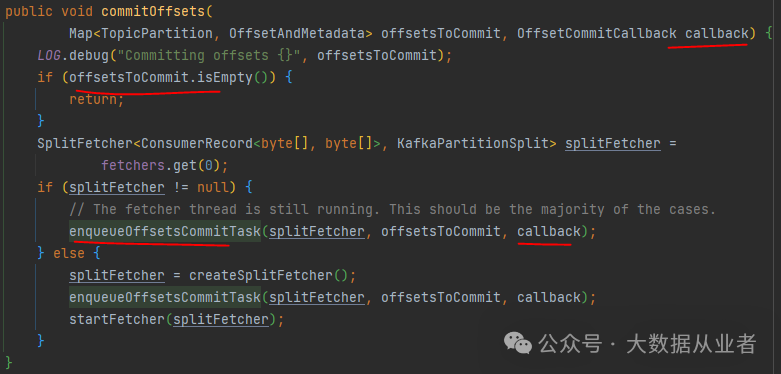
深入看下commitOffsets方法内容:enqueueOffsetsCommitTask方法就是实现提交offsets到Kafka,而callback就是实现清理上述offsetsToCommit(注意并不是下图中的offsetsToCommit)。关键问题是:下图中的入参committedPartitions(也就是下图中的offsetsToCommit)如果为空,则不会触发提交offset,这个没毛病。但是也不会触发清理上述offsetsToCommit,这个就有毛病了。
定位根因:数据量很小或者压根没有数据时,每次checkpoint都写入信息到offsetsToCommit,但是并不会删除历史,最终导致offsetsToCommit数据量越来越大!
源码修改
在notifyCheckpointComplete方法中,提前判断待提交的offsets是否为空?如果为空,说明没有读取到数据,那就不需要提交offset,那么可以复用已有的代码逻辑清理offsetsToCommit,不再执行commitOffsets方法即可。

完整代码修改PR:
https://github.com/felixzh2020/flink/commit/6da4b59d1d371cd6e18504bee5df2a80c9f82833复制
效果验证
源码修改之后,进行源码编译,替换flink-connector-kafka相关jar包。
mvn clean install -DskipTests -Dfast -Dhadoop.version=3.2.3 -T 1复制
针对该Flink作业定制配置prometheus监控,方便验证效果如下:
metrics.reporter.promgateway.factory.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporterFactorymetrics.reporter.promgateway.hostUrl: http://felixzh:9091metrics.reporter.promgateway.jobName: felixzhJobmetrics.reporter.promgateway.randomJobNameSuffix: truemetrics.reporter.promgateway.deleteOnShutdown: false复制
flink_taskmanager_Status_JVM_Memory_Heap_Used复制
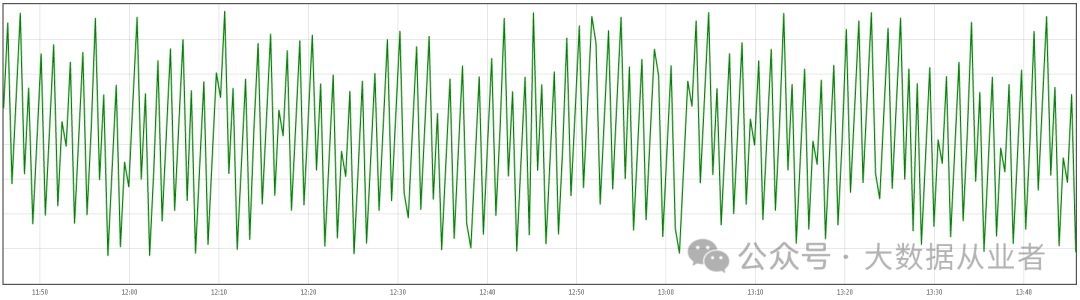
至此,Flink作业出现TaskManager内存溢出超分被杀原生bug问题定位解决完成!
