




212:通过索引访问表的成本,包括索引成本和回表成本。
对于索引会有独立的索引表,数据表本身也是索引组织表,这就代表了对有索引的表的ddl操作会增加大量I/O,并且索引也会占用空间甚至大于数据本身。
索引会消耗树高,根据条件进行数据的筛选。
索引会有两次IO消耗,第一次为索引的查询,第二次为回表的查询。
213:使用覆盖索引的执行计划标志,以及使用覆盖索引的优势。
Extra 字段里出现using index,表示直接访问索引就足够获取到所需要的数据,不需要通过索引回表,使用覆盖索引可以直接在索引页上获得所需要的数据,不需要再次回表查询,减少了一倍的IO,提高查询效率。
214:如何保证使用覆盖索引,select、group by、order by、having、where。
(1)索引条目通常远小于数据行大小,如果只读取索引,MySQL就会极大地减少数据访问量。
(2)索引按照列值顺序存储,对于I/O密集的范围查询会比随机从磁盘中读取每一行数据的I/O要少很多。
(3)InnoDB的辅助索引(亦称二级索引)在叶子节点中保存了行的主键值,如果二级索引能够覆盖查询,则可不必对主键索引进行二次查询了。
覆盖索引就是从索引中直接获取查询结果,要使用覆盖索引需要注意select查询列中包含在索引列中;where条件包含索引列或者复合索引的前导列;查询结果的字段长度尽可能少。
215:如何高效使用覆盖索引。
同时满足过滤和覆盖索引;
where 条件中要包括索引的第一个列;
覆盖索引的一个非常大的使用场合:特有技巧,从一个列非常多的大表中去除大量数据行,但是查询的少数列的信息保存在索引中;
216:总结索引的几大功能。
1.where 条件过滤数据。
索引是btree结构,如果where条件建立了索引,就会根据索引来进行快速查找,一般树高为2-4,在唯一度高的情况下效率大大高于全表扫。
2.表连接。
做表连接查询的时候如果没有索引都会进行全表扫,在表连接的条件列上给两个表都建立索引,相应的都会进行索引的查询,提高效率。
3.解决 order by。
索引的列是有序的,所以当order by 中的字段出现在where条件中时,会利用索引而不排序。
4.解决 group by。
索引的列是有序的,所以当group by 中的字段出现在where条件中时,会利用索引而不排序。
5、使用覆盖索引,解决回表和大表的问题
将上面的索引的几个应用场景,设计出例子,进行讲解。
217:Using where、Using index condition、Using index。
1.如果出现 Using index,表示使用了覆盖索引
2.如果出现了 Using where,表示访问了表(主键索引)
3.Using index condition 说明引擎优化了对表的访问,索引条件被下压到了引擎层
4.icp 的使用场合(知道这是 5.6 一个新特性就 ok 了):
1.二级索引;
2.where 条件中包含二级索引的多个列条件,但是一定包含二级索引的前导列;
3.这个是 5.6 的一个新特性,效果非常明显;
218:解释 5.6 在多列索引中为什么不害怕中间有空列,5.5 版本中害怕有空列。
5.5 中不仅仅是害怕空列,还害怕非=出现在前面的列中
select * from customer where c_w_id<2 and c_id <5and c_first like 'ab%'; //只能将第一个列压入;
select * from customer where c_w_id=1 and c_id <5and c_first like 'ab%'; //可以压入两个列;
5.5 中多列索引使用限制非常多,5.6 中解决了这个问题;
5.5 中最好将选择性最强的列放在最前面,但是要注意这个列必须被经常使用到;
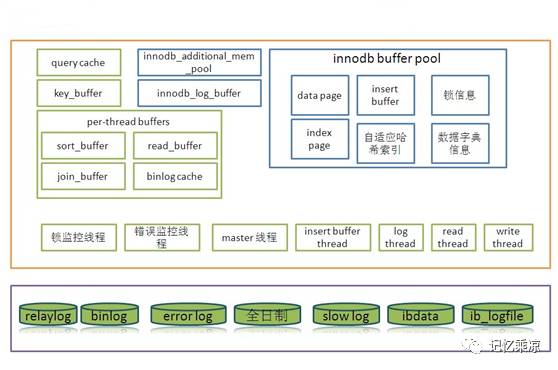
219:理解 server 层和引擎层的概念,统计信息统计的是 server 层的处理负载。
Server层:
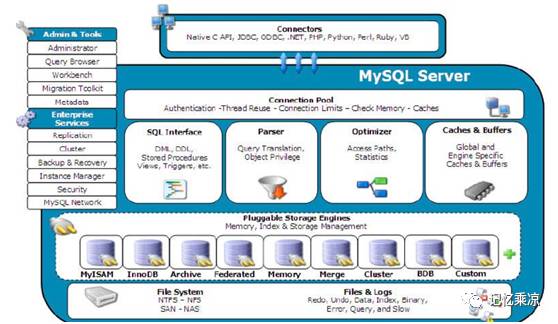
引擎层(innodb):
220:主键索引的特殊性,主键是最好的索引。
不受 30%的影响
慎重对待建立主键,将最常用的查询使用到主键
customer (c_first,c_last,c_id),这个作为这个表的主键
select * from customer where c_first like 'a%';
221:判断一个 SQL 是否合理的最稳妥的方式、以及是否走了低效的索引。
返回的行=访问的行-过滤的行
能够通过执行计划清晰的判断,谁走了索引、谁成为了过滤条件
rows-key-show index
计算返回的行数的方法:去掉 group by 和聚合函数,只保留 where 条件和 count(*)
