




「目录」
数据聚合与分组运算
Data Aggregation and Group Operations
10.1 => GroupBy机制
10.2 => 数据聚合
10.3 => apply:拆分 - 应用 - 合并
10.4 => 透视表和交叉表

apply方法
听一下上面的音乐哦,不知道有人知道出处吗 。
。
感觉又是好久没更公众号了 ,接下来正式开始吧!
,接下来正式开始吧!
apply是最通用的GroupBy方法,apply会将待处理的对象拆分成多个片段,然后对各片段调用传入的函数,最后将各片段组合到一起。
下面是本篇要用到的库:
import numpy as np
import pandas as pd复制
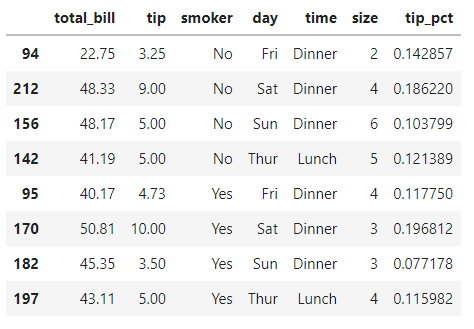
回到原书之前那个小费数据集:
tips = pd.read_csv(r'.\tips.csv')
tips['tip_pct'] = tips['tip'] / tips['total_bill']
tips.head()复制
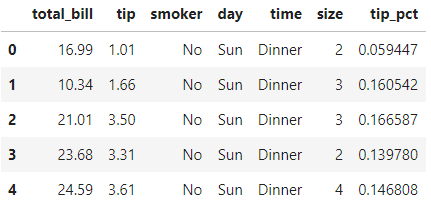
假设我们想要选择最高的5个小费百分比tip_pct值。
首先,我们编写一个函数,这个函数可以对指定列排序,并选取最大的n个值:
def top(df, n=5, column='tip_pct'):
return df.sort_values(by=column)[-n:]复制
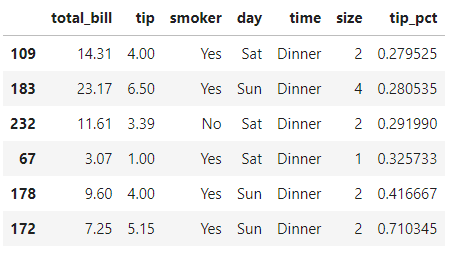
来看一下效果吧,传入小费的DataFrame:
top(tips, n=6)复制
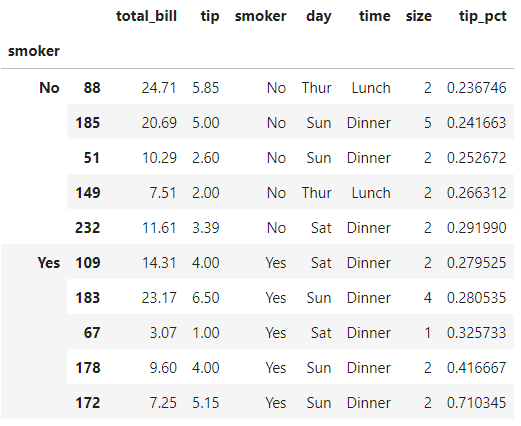
现在我们对smoker分组,并通过apply方法对每一个分组调用我们刚刚写的top函数,就会得到层次化索引的DataFrame(其内层索引值来自原DataFrame):
tips.groupby('smoker').apply(top)复制
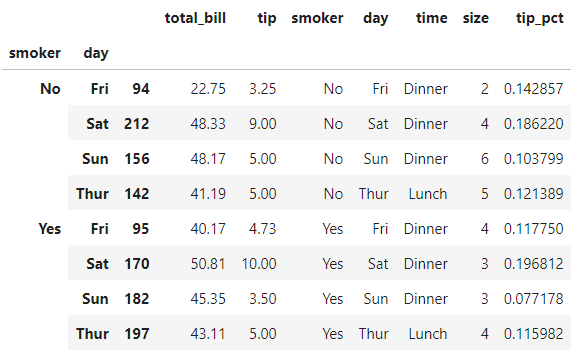
如果我们想要改变top函数的参数,该怎么办呢 ?
?
答案是若函数可以接受多个参数,则可以将这些内容放在函数名后面一并传入。
比如我们编写的top函数除了要传入的df,还可以接受n和column两个参数,那我们在传入top函数后,还可以传入top函数的n和column参数
tips.groupby(['smoker', 'day']).apply(top, n=1, column='total_bill')复制
最后,从上面的例子可以看出,分组键会跟原始对象的索引共同组成层次化索引,传入group_keys=False可禁止该效果
tips.groupby(['smoker', 'day'], group_keys=False).apply(top, n=1, column='total_bill')复制
那就这样吧,BYE-BYE
往期回顾
Pandas之你点开就知道了


Stay hungry, stay foolish
文章转载自Yuan的学习笔记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
[MYSQL] 服务器出现大量的TIME_WAIT, 每天凌晨就清零了
大大刺猬
143次阅读
2025-04-01 16:20:44
mysql提升10倍count(*)的神器
大大刺猬
123次阅读
2025-03-21 16:54:21
演讲实录|分布式 Python 计算服务 MaxFrame 介绍及场景应用方案
阿里云大数据AI技术
122次阅读
2025-03-17 13:27:37
官宣,Milvus SDK v2发布!原生异步接口、支持MCP、性能提升
ZILLIZ
96次阅读
2025-04-02 09:34:13
[MYSQL] query_id和STATEMENT_ID在不同OS上的关系
大大刺猬
64次阅读
2025-03-26 19:08:13
DataWorks :Data+AI 一体化开发实战图谱
阿里云大数据AI技术
46次阅读
2025-03-19 11:00:55
国密算法介绍
漫步者
44次阅读
2025-03-21 09:20:39
如何使用 RisingWave 和 PuppyGraph 构建高性能实时图分析框架
RisingWave中文开源社区
37次阅读
2025-03-18 10:49:54
WingPro for Mac 强大的Python开发工具 v10.0.9注册激活版
一梦江湖远
33次阅读
2025-03-29 10:33:27
python操作MySQL数据库
怀念和想念
29次阅读
2025-03-30 23:22:07
