




VLDB 2023 - OceanBase Paetica- A Hybrid Shared-nothing_Shared-everything Database for Supporting Single Machine and Distributed Cluster.pdf
免费下载

OceanBase Paetica: A Hybrid Shared-nothing/Shared-ever ything
Database for Supporting Single Machine and Distributed Cluster
Zhifeng Yang
∗
OceanBase, Ant Group
Quanqing Xu
∗
OceanBase, Ant Group
Shanyan Gao
OceanBase, Ant Group
Chuanhui Yang
†
OceanBase, Ant Group
Guoping Wang
OceanBase, Ant Group
Yuzhong Zhao
OceanBase, Ant Group
Fanyu Kong
OceanBase, Ant Group
Hao Liu
OceanBase, Ant Group
Wanhong Wang
OceanBase, Ant Group
Jinliang Xiao
OceanBase, Ant Group
OceanBaseLabs@service.oceanbase.com
ABSTRACT
In the ongoing evolution of the OceanBase database system, it
is essential to enhance its adaptability to small-scale enterprises.
The OceanBase database system has demonstrated its stability and
eectiveness within the Ant Group and other commercial orga-
nizations, besides through the TPC-C and TPC-H tests. In this
paper, we have designed a stand-alone and distributed integrated
architecture named Paetica to address the overhead caused by the
distributed components in the stand-alone mode, with respect to the
OceanBase system. Paetica enables adaptive conguration of the
database that allows OceanBase to support both serial and parallel
executions in stand-alone and distributed scenarios, thus provid-
ing eciency and economy. This design has been implemented in
version 4.0 of the OceanBase system, and the experiments show
that Paetica exhibits notable scalability and outperforms alternative
stand-alone or distributed databases. Furthermore, it enables the
transition of OceanBase from primarily serving large enterprises
to truly catering to small and medium enterprises, by employing a
single OceanBase database for the successive stages of enterprise or
business development, without the requirement for migration. Our
experiments conrm that Paetica has achieved linear scalability
with the increasing CPU core number within the stand-alone mode.
It also outperforms MySQL and Greenplum in the Sysbench and
TPC-H evaluations.
PVLDB Reference Format:
Zhifeng Yang, Quanqing Xu, Shanyan Gao, Chuanhui Yang, Guoping
Wang, Yuzhong Zhao, Fanyu Kong, Hao Liu, Wanhong Wang, and Jinliang
Xiao. OceanBase Paetica: A Hybrid Shared-nothing/Shared-everything
Database for Supporting Single Machine and Distributed Cluster. PVLDB,
16(12): 3728 - 3740, 2023.
doi:10.14778/3611540.3611560
∗
These authors contributed equally to this work.
†
Chuanhui Yang is the corresponding author.
This work is licensed under the Creative Commons BY-NC-ND 4.0 International
License. Visit https://creativecommons.org/licenses/by-nc-nd/4.0/ to view a copy of
this license. For any use beyond those covered by this license, obtain permission by
emailing info@vldb.org. Copyright is held by the owner/author(s). Publication rights
licensed to the VLDB Endowment.
Proceedings of the VLDB Endowment, Vol. 16, No. 12 ISSN 2150-8097.
doi:10.14778/3611540.3611560
PVLDB Artifact Availability:
The source code, data, and/or other artifacts have been made available at
https://github.com/oceanbase/obdeploy.
1 INTRODUCTION
Initially, we have designed and developed the OceanBase system in
version 0.5, which utilizes a divided storage and computing layer,
thus resulting in signicant scalability. For further improvement
of the performance, we have then implemented version 3.0 of the
system, which features enhancements that enable higher through-
put and lower write latency, thus being capable of supporting the
various business operations within the Ant Group and other com-
mercial organizations. Furthermore, we made the system available
as open-source, and shared the design and technology of the sys-
tem within the open-source community. We have commercialized
OceanBase, for applying its technology and capabilities to the busi-
nesses of numerous large, medium, and small enterprises since
2017. It is worth noting that OceanBase was the only distributed
database that passed the TPC-C benchmark in 2020. However, the
version 3.0 of OceanBase was not that well-suited to medium and
small enterprises, probably owing to the overhead incurred by the
log streams and partition bounds in small-scale machines, besides
the additional overhead resulting from the interaction among the
distributed components during the deployment.
The emergence of distributed databases has resolved the issue
of horizontal scalability, but the stand-alone performance and SQL
functionality are signicantly inferior when compared to central-
ized databases, e.g., Oracle [
23
], MySQL [
34
], and PostgreSQL [
37
].
Many distributed databases have emerged during this process, and
some of them are distributed storage systems that only support
simple NoSQL functionality or limited SQL functionality, such as
Amazon Dynamo [19]. Furthermore, certain distributed databases
support both horizontal scalability and complete SQL functionality,
often referred to as NewSQL, such as CockroachDB [
42
] and Google
Spanner [
9
]. Citus [
17
] is an open source distributed PostgreSQL
for data-intensive applications through the PostgreSQL extension
APIs. However, their single-node performance is less than one-third
of that of MySQL.
Therefore, the choice between the stand-alone and distributed
system has become strenuous. Thus the typical decision-making is
3728

based on the data volume; i.e., if the data volume is relatively small, a
centralized database with complete functionality is chosen. Further,
if the data volume is huge, a distributed database or distributed
storage system is selected, thus sacricing the functionality and
stand-alone performance in order to address the issue by modifying
the business or adding machines.
We further enhanced OceanBase [
47
] to version 4.0, expecting
that it would better support small-scale enterprises. The system
integrates several storage shards with a shared log stream and
provides a high-availability service. Owing to the advancement
in technology, contemporary machines have come to feature mul-
tiple cores, large amounts of DRAM, and high-speed storage de-
vices. This highlights the importance of considering both horizontal
and vertical scalability in the design of a distributed database sys-
tem. Accordingly, we have developed Paetica
1
as a hybrid shared-
nothing/shared-everything cloud database system capable of sup-
porting both stand-alone and distributed integrated architecture.
We will describe the concept of Paetica in detail with the following
contributions.
•
We propose Paetica, a stand-alone and distributed inte-
grated architecture that is implemented in version 4.0 of
the OceanBase system. Paetica features independent SQL,
transaction, and storage engines in both the stand-alone
and distributed systems, which enables the dynamic cong-
uration switching by the user. The integrated architecture
design allows OceanBase to operate eciently without in-
curring the distributed interaction overhead in the stand-
alone mode. Furthermore, while operating in the distributed
mode, the system achieves high performance besides pro-
viding disaster tolerance.
•
We have developed a stand-alone and distributed integrated
SQL engine that is capable of processing SQL in diverse
situations. The engine has been designed to execute SQL
both in the serial and parallel manner to fully utilize the
available CPU cores. Furthermore, in distributed execu-
tion scenarios, the engine is capable of parallelism across
multiple machines that allows ecient processing of SQL
commands.
•
We have constructed a stand-alone and distributed inte-
grated LSM-Tree storage engine that includes various com-
paction optimizations for both the stand-alone and dis-
tributed modes. These optimizations include the techniques
such as incremental major compaction and staggered round-
robin compaction, which intends to achieve a balance be-
tween the write performance and storage space utilization.
•
For the stand-alone and distributed integrated transaction
processing engine, we have proposed an optimized version
of the 2-Phase Commit (2PC) protocol. This optimization
intends to reduce the message processing and log volume,
and subsequently decrease transaction latency. In the stand-
alone mode, Paetica does not require the use of 2PC and
instead utilizes a single log stream to process transactions
without accessing the global time service (GTS). Conse-
quently, the eciency of the transaction engine is compa-
rable to that of a stand-alone database.
1
Paetica is OceanBase version 4.0.
We have conducted scalability experiments to demonstrate the
linear scalability of Paetica. Our OLTP (Online Transaction Pro-
cessing) experiments also demonstrate that Paetica exhibits high
concurrency and low latency in both stand-alone and distributed
modes. We have also compared OceanBase 4.0 with MySQL 8.0 in a
separate experiment and found that OceanBase 4.0 performs better
than MySQL 8.0 in small-scale and stand-alone situations. Further-
more, we have compared Paetica with OceanBase version 3.1 and
Greenplum [
31
] 6.22.1 on the TPC-H [
7
] 100GB experiments, and it
is observed that Paetica outperforms OceanBase 3.1 5x on average.
Compared with Greenplum 6.22.1, Paetica demonstrates a superior
performance across all queries.
The paper is organized as follows. §2 presents the OceanBase
evolution. §3 provides an overview of the stand-alone and dis-
tributed architecture. §4 and §5 describe the integrated engine of
SQL and transaction processing. We present the experiments in §6
to prove the ecacy and economy of Paetica. We present discussion
including polymorphisim, dynamism and native multi-tenancy in
§7, and we review the related work in §8. Finally, we give the con-
clusions in §9. OceanBase is an open-source project under Mulan
Public License 2.0 [
2
] and the source code referenced in this paper
is available on both gitee [3] and GitHub [4].
2 OCEANBASE EVOLUTION
In this section, we illustrate the evolution of OceanBase from ver-
sion 0.5 to version 4.0.
2.1 OceanBase 0.5
OceanBase [
4
] has been developed since 2010. Figure 1 is the over-
all architecture diagram of OceanBase version 0.5. Concomitantly,
OceanBase has been divided into two layers, viz., storage and com-
puting. The upper layer is a service layer that provides SQL services
statelessly, and the lower layer is a storage cluster composed of two
kinds of servers: ChunkServer and UpdateServer. The ChunkServer
is characterized by the capability for automatic partitioning and
horizontal scalability of storage. The UpdateServer utilizes the Paxos
protocol [
28
] to attain strong consistency and availability. However,
the UpdateServer does not possess the capability for distributed
transactions. Such an architecture can enable OceanBase to bet-
ter support businesses similar to Taobao favorites [
1
]. Further, it
has certain scalability, particularly a relatively strong scalability of
reading, and the SQL layer is stateless and can be scaled freely.
Despite the advantages of this architecture, a major issue is that
the UpdateServer node is a single-point write, multi-point read archi-
tecture, which is similar to PolarDB [
13
][
29
] and makes it dicult
to expand when higher levels of concurrency become necessary.
Furthermore, according to Figure 1, splitting the storage and SQL
layers results in a high query delay. It is dicult to control the net-
work jitter, and controlling the jitter of latency can be challenging
under conditions of extremely high latency requirements.
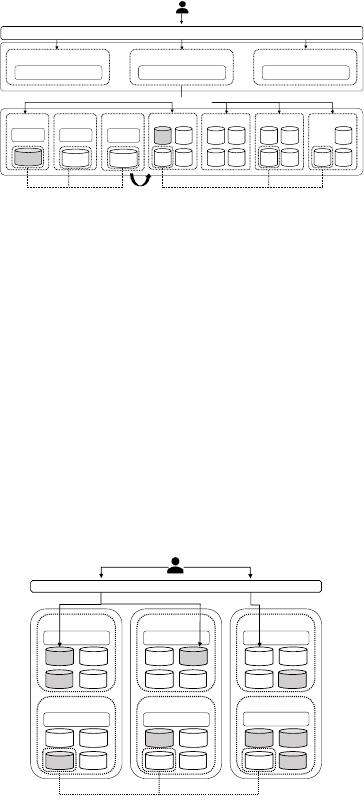
2.2 OceanBase 1.0 ~ 3.0
To address the aforementioned issues, OceanBase has abandoned
its previous architecture and developed the version 1.0 ~ 3.0, which
is characterized by a fully peer-to-peer (P2P) structure as shown
Figure 2. Each OBServer contains SQL, storage, and transaction
3729
Writes Reads
SQL
MergeServer
SQL
MergeServer
SQL
MergeServer
R1 R5
R4
Chun kServer
R3
Chunk Replicas
R1 R2
R4
Chun kServer
R5
R1 R2
R5
Chun kServer
R3
R2
R4
Chun kServer
R3
TABLE API
UpdateServer 1
Memtable
UpdateServer 2
clog
Memtable
UpdateServer 3
clog
Memtable
Paxos Group
Compaction
ReadsWrites
Driver
clog
Figure 1: OceanBase 0.5
engines. All the servers are able to process SQL and handle trans-
actions besides simultaneously storing data. As depicted in this
diagram, the vertical direction represents the distributed and scal-
able layer, whereas the horizontal direction represents the repli-
cation layer. The horizontal direction provides high availability
capabilities, whereas the vertical direction is achieved through the
continuous addition of machines to enhance the overall scalabil-
ity of the service. It employs several optimizations to achieve low
latency. In the stand-alone mode, local execution plan, local trans-
action API and the elimination of network overhead in the read
and write operations are the key features that contribute to the
low latency. In the distributed mode, the use of duplicated tables,
parallel execution engines, and multiple partition indexes are the
key factors that enable the low latency performance.
ZONE_1
P5 P6
P8
OBServer
P7
ZONE_2
P5 P6
P8
OBServer
P7
ZONE_3
P5 P6
P8
OBServer
P7
Paxos Group
P1 P2
P4
OBServer
P1
RS P4
OBServer
P1
RS
P2
OBServer
RS
P2
P4
Driver/OBProxy
Weak consistency
reads
Writes Reads
SQL SQL SQL
SQL
SQLSQL
Figure 2: OceanBase 1.0~3.0
Prior the evolution to OceanBase 4.0, the original architecture
had excellent scalability. Under this scalability, we performed the
TPC-C benchmark [
6
][
16
] with OceanBase 3.0. OceanBase is the
only distributed database that passed the TPC-C benchmark at
that time. This also reects that the OceanBase 3.0 architecture
has exceptional adaptability in terms of horizontal scalability. Ac-
cording to Figure 2, from three nodes to 1,557 nodes OceanBase’s
ranking with a tpmC [
6
] index of 707 million, as the number of
nodes increases, the entire tpmC indicator has appreciable linear
scalability. While performing the TPC-C evaluation, OceanBase uti-
lizes a large cluster composed of 1,557 machines, and within eight
hours of pressure testing, it has the ability to process twenty million
transactions per second. This result shows that the previous archi-
tecture can support excellent scalability, and almost this scalability
and concurrent processing capabilities can satisfy the requirements
of most current online service systems, globally. Furthermore, by
employing a single zone deployment over a distributed storage
system, OceanBase passed TPC-H benchmark test and gained over
15 million QphH@30,000GB [5] in May 2021.
2.3 OceanBase 4.0
However, with the iteration of business requirements, we developed
the OceanBase 4.0 architecture, as shown in Figure 3. OceanBase
4.0 has the following features.
•
More partitions: The architecture of OceanBase 4.0 reduces
the cost of partition maintenance. Furthermore, the opti-
mization of memory should not be underestimated. In the
previous versions, we have maintained one metadata for
every 2MB macroblock, and the ratio of metadata to data
is approximately 1:1000. Therefore, for models with larger
disks, the overhead of metadata would also increase signi-
cantly. In this iteration, we have made the storage memory
overhead as on-demand loading, thus maintaining only the
root node (very small) in memory. When the user needs
to access the metadata, the leaf node and data node are
then loaded. This method reduces the overhead of the resi-
dent memory and brings the feature of small-size memory
optimization.
•
More DDL support: In OceanBase 4.0, Data Denition Lan-
guage (DDL) allows the users to easily modify partitions
and alter primary keys, thereby facilitating existing data-
base usage practices. The implementation of DDL is rela-
tively straightforward. Initially, a hidden table is created,
and the pre-DDL transaction is initiated with attained snap-
shot point. The original table is then locked for reading
and writing. Subsequently, a Data Manipulation Language
(DML) statement is employed to supplement the data in the
hidden table. Finally, the original table is renamed. The pro-
cess involves three key technologies, viz., 1) table locking,
which prevents write operations while the modications
are being made, 2) Partitioned DML (PDML), which is used
to accelerate the queries and streamline the code, and 3)
direct insertion, which allows for writing directly to static
data, thus avoiding memory overload and providing faster
speeds.
•
Less resource consumption: In OceanBase 4.0, the production
specications have been decreased from 16C/64G to 4C/16G
(CPU/memory), thus improving the user eciency. We have
primarily optimized the following aspects, viz., 1) thread
stack optimization to reduce thread-local variables and use
of SmartVar to decrease the stack variables, 2) improvement
of metadata overhead from per-partition to per-logstream
storage, thus allowing metadata to be loaded on demand,
and 3) improved stability through the default activation
of input restriction, thus enabling greater stability under
4C/16G.
•
Tenant isolation: We have optimized the tenant coupling
logic, primarily in the following three aspects, viz., 1) tenant-
level merging, whereby the default merging behavior is
triggered by tenants instead of cluster-wide, 2) tenant-level
metadata, in which the metadata is adjusted from the sys-
tem tenant to the user tenant and the TableId and TenantId
are decoupled, and 3) tenant I/O isolation, with Clog (Com-
mit log) les being split into tenants and SSTable supporting
the tenant-level I/O restriction.
3730
of 13
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
最新上传
下载排行榜
1
2
9-数据库人的进阶之路:从PG分区、SQL优化到拥抱AI未来(罗敏).pptx
3
1-PG版本兼容性案例(彭冲).pptx
4
2-TDSQL PG在复杂查询场景中的挑战与实践-opensource.pdf
5
6-PostgreSQL 哈希索引原理浅析(文一).pdf
6
3-AI时代的变革者-面向机器的接口语言(MOQL)_吕海波.pptx
7
8-基于PG向量和RAG技术的开源知识库问答系统MaxKB.pptx
8
4-IvorySQL V4:双解析器架构下的兼容性创新实践.pptx
9
7-拉起PG好伙伴DifySupaOdoo.pdf
10
《云原生安全攻防启示录》李帅臻.pdf

相关文档
评论