




Key Technologies of Distributed Transactional Database Storage Engine_中国移动.pdf
免费下载
Key Technologies of Distributed Transactional
Database Storage Engine
*Note: Sub-titles are not captured in Xplore and should not be used
line 1: 1
st
Given Name Surname
line 2: dept. name of organization
(of Affiliation)
line 3: name of organization
(of Affiliation)
line 4: City, Country
line 5: email address
line 1: 4
th
Given Name Surname
line 2: dept. name of organization
(of Affiliation)
line 3: name of organization
(of Affiliation)
line 4: City, Country
line 5: email address
line 1: 2
nd
Given Name Surname
line 2: dept. name of organization
(of Affiliation)
line 3: name of organization
(of Affiliation)
line 4: City, Country
line 5: email address
line 1: 5
th
Given Name Surname
line 2: dept. name of organization
(of Affiliation)
line 3: name of organization
(of Affiliation)
line 4: City, Country
line 5: email address
line 1: 3
rd
Given Name Surname
line 2: dept. name of organization
(of Affiliation)
line 3: name of organization
(of Affiliation)
line 4: City, Country
line 5: email address
line 1: 6
th
Given Name Surname
line 2: dept. name of organization
(of Affiliation)
line 3: name of organization
(of Affiliation)
line 4: City, Country
line 5: email address
Abstract—With the development of information technology
at home and abroad and the rapid popularization of mobile
Internet, the data of business systems has increased
exponentially. The processing and storage capabilities of
traditional centralized databases are facing great challenges.
Distributed databases have become the only way for
enterprises to transform their digitalization. At the same time,
in order to break through the market monopoly of traditional
database vendors, it is a strong demand for the domestic
database market to realize the localization of distributed
database brands. This technical research paper constitutes a
storage engine for distributed databases by studying consistent
hash distributed storage, data sharding technology and
transaction consistency. On the basis of the above technical
research, further discussion on the hierarchical design of
distributed storage engines, distributed system expansion and
data rebalancing, provides theoretical and practical basis for
creating mature and stable distributed database innovative
products.
Keywords—distributed transactional database, storage engine,
consistent hash distribution, transaction consistency, dynamic
expansion, data rebalancing
I. INTRODUCTION
The most important function of a distributed
transactional database is data sharding[1-3]. Data
Sharding refers to distributing a database to multiple
back-end data node instances. In the research and
discussion of transaction consistency, we start with the
basic theory of transaction consistency, and further
analyze the implementation of classic algorithms of
related theories, including some relatively new distributed
transaction consistency algorithms[4]. Finally, this thesis
will summarize the design and implementation of key
technologies of database storage engine based on the
thesis.
II. KEY TECHNOLOGIES OF DISTRIBUTED DATABASE
STORAGE ENGINE
A. Consistent hash distributed storage
Consistent Hashing Algorithm is one of the
important distributed algorithms. This algorithm is often
used in load balancing to solve data hotspot problems in
general hash algorithms[5-6]. The consistent hashing
algorithm mainly uses a circle of 0~232-1. The consistent
hash algorithm suppresses the redistribution of hash keys
to the maximum level, and solves the problem of server
additions and deletions that cannot be dealt with by
traditional modulo algorithms.
B. Data Sharding Technology
Data sharding—generally called data sharding, is its
main purpose to solve the problem of database scalability.
Data sharing mainly includes data sharding strategy,
primary key generation, route merging and distributed
transactions.
(1)Sharding strategy
Vertical segmentation is to divide the tables that are
related to the realized business functions and the tables
are closely related to achieve the cohesion of the functions
of each business. The segmentation rule for horizontal
segmentation is generally to use ordinary hash or
consistent hash algorithm to hash certain columns, and
then hash the data into the corresponding table.
(2)Primary key generation strategy
The data using horizontal segmentation is
distributed to multiple tables. In order to ensure the
convenience of data migration and the correctness of data
access, the global uniqueness of the primary key needs to
be guaranteed.
(3)Route merge
The data in the same logical table will be scattered
and stored in multiple physical tables after data sharding.
When adding, deleting, modifying and querying tables,
the operation of one SQL statement may involve multiple
physical data tables.
(4)Distributed transaction
After the data is stored in multiple physical data
tables through data sharding, it is also necessary to ensure
the consistency and integrity of the data in a distributed
environment, which requires the use of distributed
transactions. Distributed transactions generally use a two-
phase commit protocol (2pc protocol).
III. SCHEME DESIGN AND REALIZATION
A. Design and Implementation of Sharding Scheme of
Distributed Database Storage Engine
1. Database distributed design
In distributed database design, database distribution
design includes database fragmentation design and
fragment allocation design, which are closely related.
The database distribution design should consider the
following goals:
(1)Availability and reliability. A distributed
database system is composed of multiple nodes, and
multiple copies of data are stored on each node to ensure
the reliability and availability of the system.
(2)Deal with locality. Data distribution should be
based on satisfying local operations as much as possible,
even if most operations are completed in local sites. This
requires dividing the data and placing the data fragments
on the most frequent site or the closest site as possible.
(3)Storage cost. The distribution of multiple data
copies is affected by the storage capacity of each node.
Although storage capacity is not very important compared
to the application's CPU, I/O, and network transmission
costs, it is still a factor that should be considered when
designing.
(4)Load distribution. Reasonably distribute
workloads on various sites of the network, so as to give
full play to the capabilities of computers in various places
and increase the parallelism of the execution of various
applications. Load distribution and processing locality
may conflict, so a comprehensive trade-off must be made
when designing data distribution.
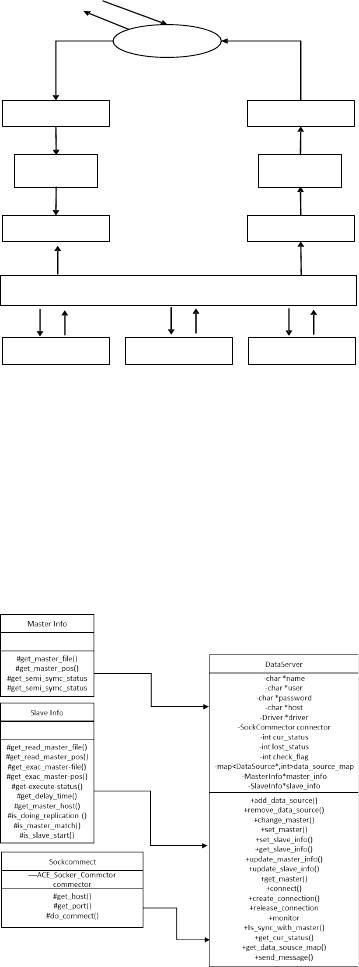
2 Distributed storage design
In order to realize data sharding, the distributed
transactional database uses a three-tier architecture model.
The three-tier architecture diagram mode is shown in
Figure1.
The three-layer model is an abstraction of data
nodes, which is divided into data node layer, data source
layer and data space layer. When receiving a SQL request
from the user, first query in the data space layer, and then
obtain the data source layer from the found data space
layer, and then obtain the data that needs to be executed
according to the read/write type of SQL and the
characteristics of the data source One or several back-end
data nodes, and then execute specific SQL statements.
Figure 1 Three-layer model diagram
3.Design of data node layer
A data node object is a specific back-end data node
instance. All SQL requests for distributed databases will
eventually be implemented on a specific one or several
data nodes, that is, one or several back-end data node
instances. on. The data node layer uses protocols to
directly deal with the network layer, so it is necessary to
provide network interface and network connection related
information. It is shown in Figure2.
Figure2 Data node design class diagram
The data node layer is the first level of abstraction
of the back-end single-node instance of the distributed
transaction database. A data node stores connection
information, master-slave information, and so on of a
back-end data node instance.
4 Design of data source layer
The data source layer is the interaction layer
between the data space layer and the data node layer, that
is, the data source of the data space layer. There are five
types of data sources in this article, namely, single-node
data sources, primary and backup data sources, separate
read-write data sources, master-slave replication data
sources, and load balancing data. The latter four are
assembled from single-node data sources, and the overall
design adopts a tree structure.It is shown in Figure3.
DBScale
Data space layer
Data source layer
Data node layer
Data node layer
Data space layer
Network protocol
Database
Database
Database
Data source layer
SQL
request
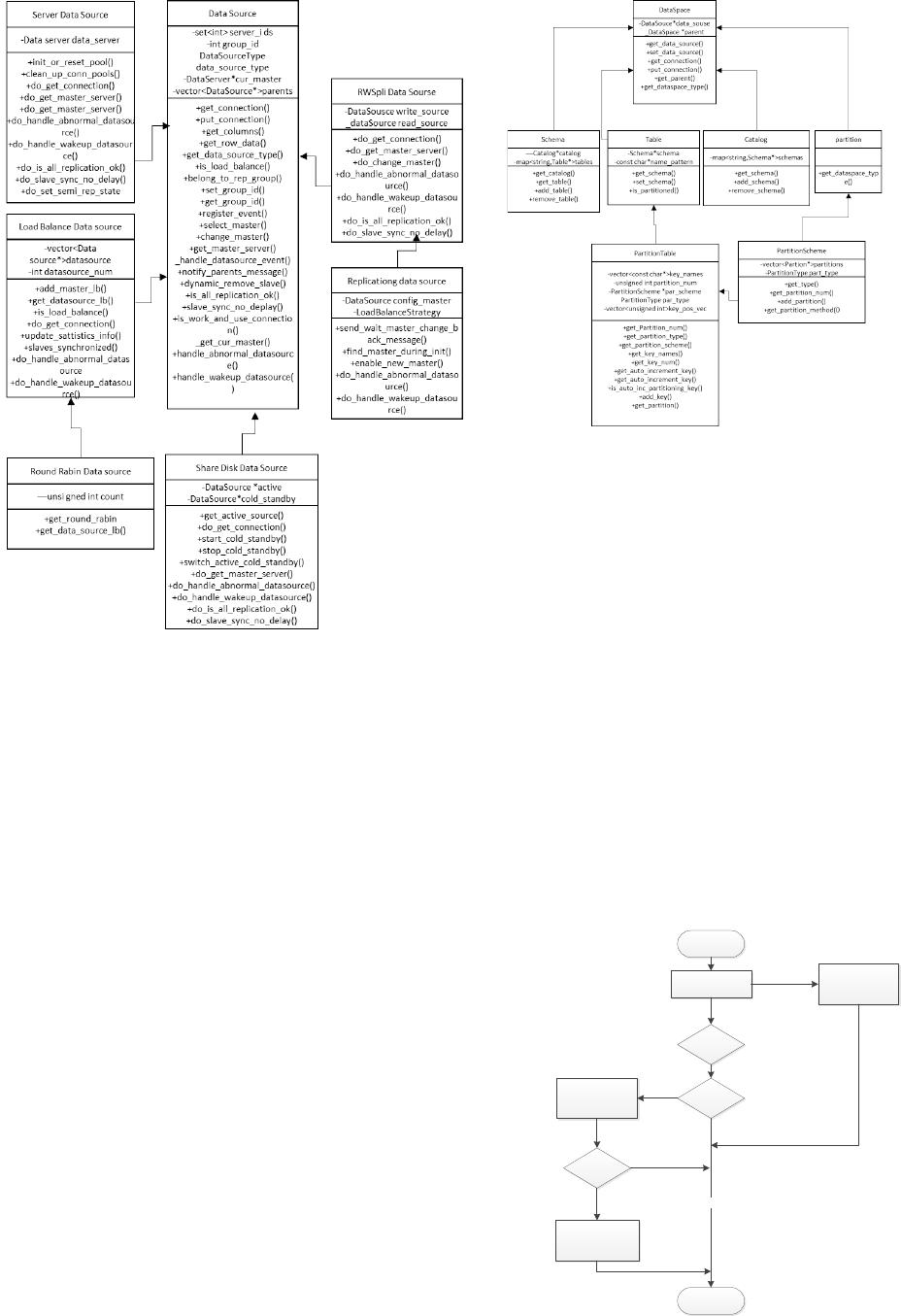
Figure 3 Data source design class diagram
5 Data space layer design
The data space layer is used for distributed
transactional database to realize data sharding. The data
space layer refers to the domain of the data, and the
domain refers to the source of the data, that is, the data
source layer improved above. The type of data space
should be divided into three categories, namely Catalog,
Schema and Table. Catalog is the continuation of the
meaning of a single data node; Schema is used for sub-
databases. If the parsed schema and table, where the table
is not configured but the schema is configured, the SQL
request is sent to the schema; the table is divided into
ordinary tables and partitions Table.It is shown in Figure4.
6 Storage engine Sharding solution implementation
Data Sharding is based on three layers of data
abstraction: data nodes, data sources and data spaces. The
realization of data source is the realization of various
special data clusters, the realization of data space is the
realization of data sharding.
Figure4 Data space design class diagram
7 Design and implementation of data node layer
In order to achieve high availability and real-time
understanding of the cluster status, there are threads for
monitoring the status of the back-end Server in the data
nodes. Once an abnormal state occurs, the cluster
corresponding to this server will be notified to the data
source layer, and different types of data sources will give
different processing methods.
(1)First, do some initial work on the monitoring
connection of the monitoring thread, mainly to obtain a
valid connection from the back-end data node according
to the IP port of the back-end data node configured by the
user;
(2)Send the data node ping command to the
back-end data node. If the return is not an ok packet, it
means that the back-end data node has been unable to
work for some reason. The message that it cannot work is
immediately sent to the upper data source layer, and the
upper data source will Process according to your own data
source type. It is shown in Figure5.
Figure5 Flow of back-end monitoring thread
Begin
Initialize connection
information
Sending MySQL failed
to Ping
It can be pinged
It is a slaveCheck slave status
Slave status is
normal
Send slave exception
message
End
否
Yes
Yes
Yes
No
否
of 6
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
最新上传
下载排行榜
1
2
白鳝-DBAIOPS:国产化替换浪潮进行时,信创数据库该如何选型?.pdf
3
centos7下oracle11.2.0.4 rac安装详细图文(虚拟机模拟多路径).docx
4
PostgreSQL 缓存命中率低?可以这么做.doc
5
李飞-AI 引领的企业级智能分析架构演进与行业实践.pdf
6
达梦数据2024年年度报告.pdf
7
刘杰-江苏广电:从Oracle+Hadoop到TiDB,数据中台、实时数仓运维0负担.pdf
8
Sunny duan-大模型安全挑战与实践:构建 AI 时代的安全防线.pdf
9
晋鑫宇_AI Agent 赋能社交媒体-构建未来社交生态的核心驱动力.pdf
10
刘晓国-基于 Elasticsearch 创建企业 AI 搜索应用实践.pdf

相关文档
评论