




最近在做一个DPU项目解决分布式训练的AllReduce问题,当然对标的肯定是nVidia(卖螺丝)的解决方案咯, 我们的内部测试成绩远好于它,等过段时间发了论文再给大家汇报
什么是AllReduce
由于数据规模
和模型规模
的扩大必须利用计算机集群
来构建分布式
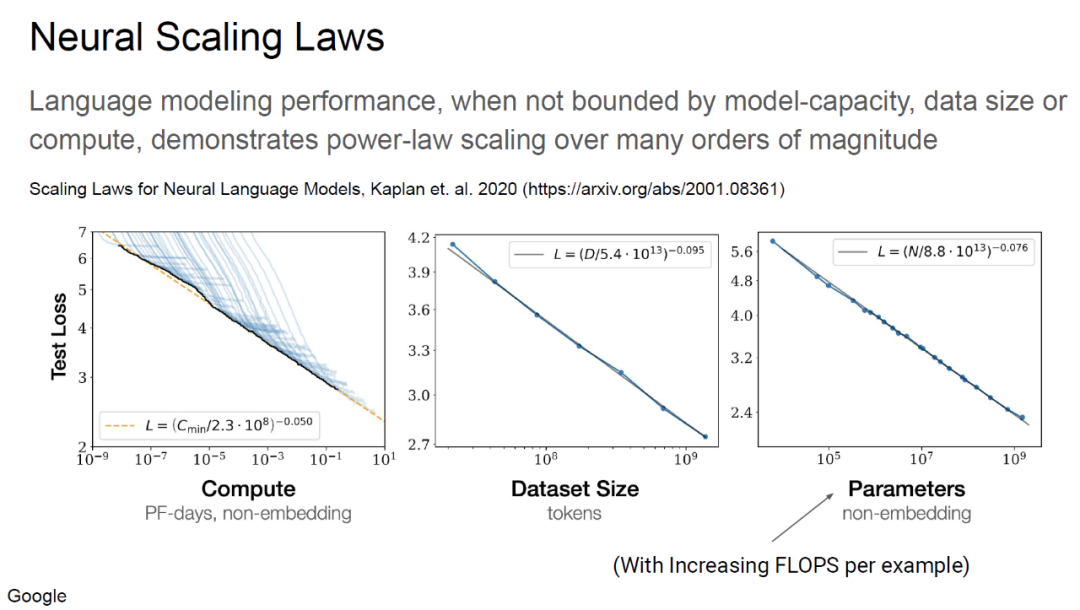
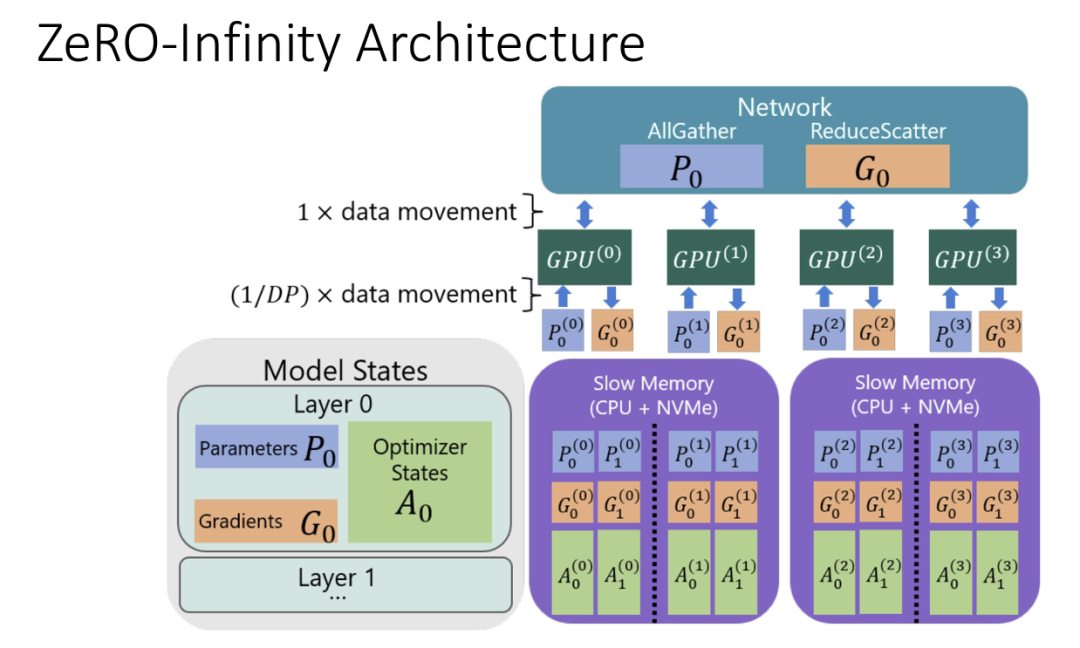
机器学习框架,并行处理的方式主要是在两个维度。数据规模比较好理解随着IOT和数据采集,可供于训练的数据集通常可以达到数十TB, 而模型规模主要是业界竞争的重点,下图来自于HotChip33中微软介绍ZeRO-Infinity的胶片:

可以看到参数规模已经接近10TB了,其它几个模型,例如GPT-3参数已经达到1700亿,而常见的各厂家模型也到了数十亿级(nVidia MegatronLM 83亿,微软Turing-NLG 170亿,阿里PLUG 270亿).而本质上对于NLP一类的模型,参数个数就是提高准确性的最直接的手段:
在这么大量规模下,分布式集群训练是必然趋势,这也是nVidia为什么要买Mellanox的原因:
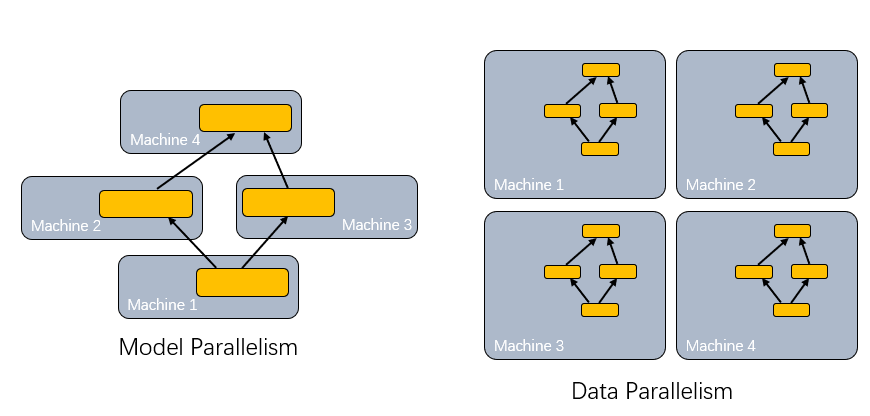
数据并行
很容易解释,主要是如何存储训练样本,并且在多机器之间传递混淆样本,基本上大家大同小异的都在采用SSD、分布式存储解决这些问题.另一个问题便是模型并行
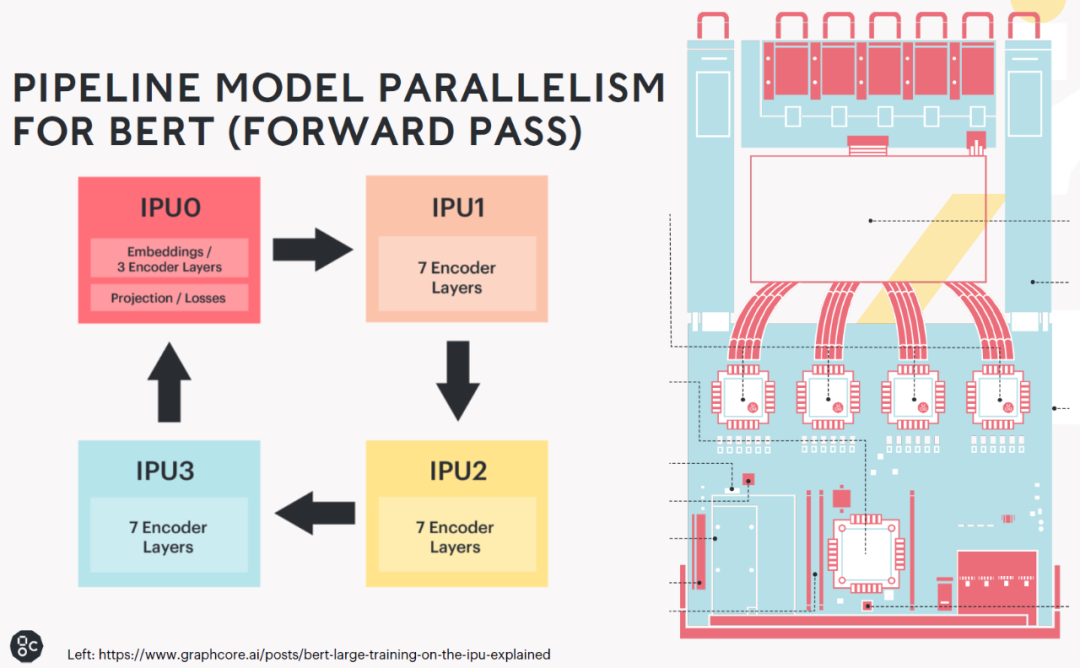
,当单个工作节点无法存储时,就需要对模型本身进行分割,而如何分割这个模型又是一个最优化的过程...而且也是一个软硬件协同的过程,例如GraphCore
对于分布式AI训练而言,每次迭代都需要将参数进行同步,通常是将每个模型对应的参数加总求和再获得平均值
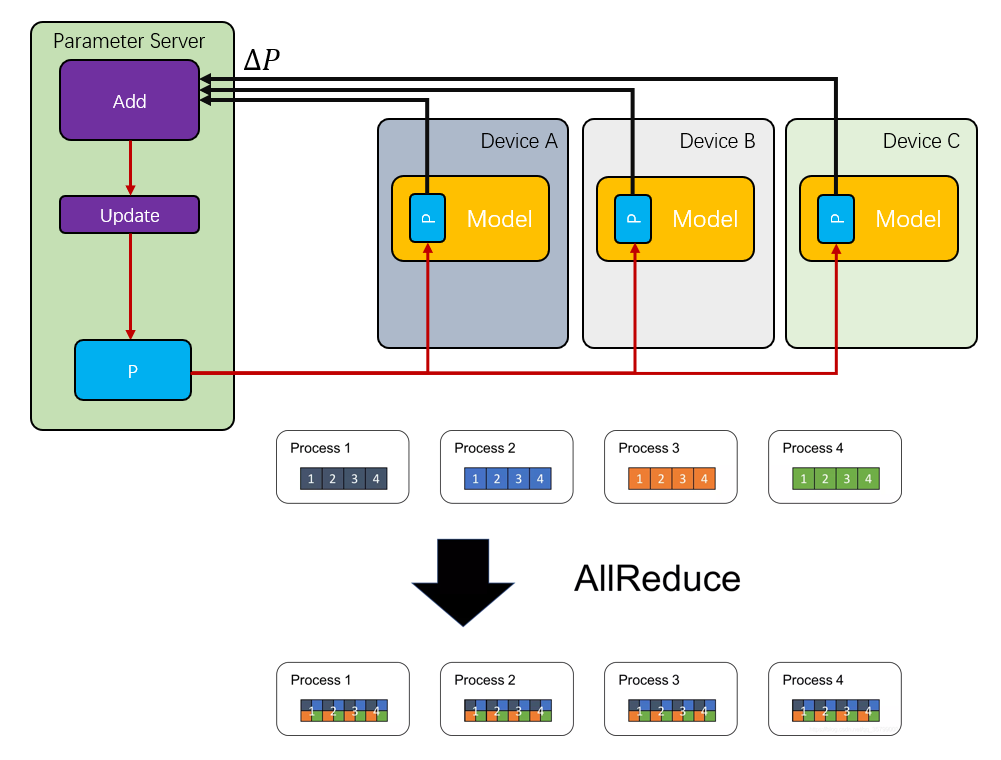
最开始的时候,是采用一个集中式的参数服务器(Parameter Server)构建,但是很快就发现它成了整个集群的瓶颈,然后又有了一些环形拓扑的All-Reduce
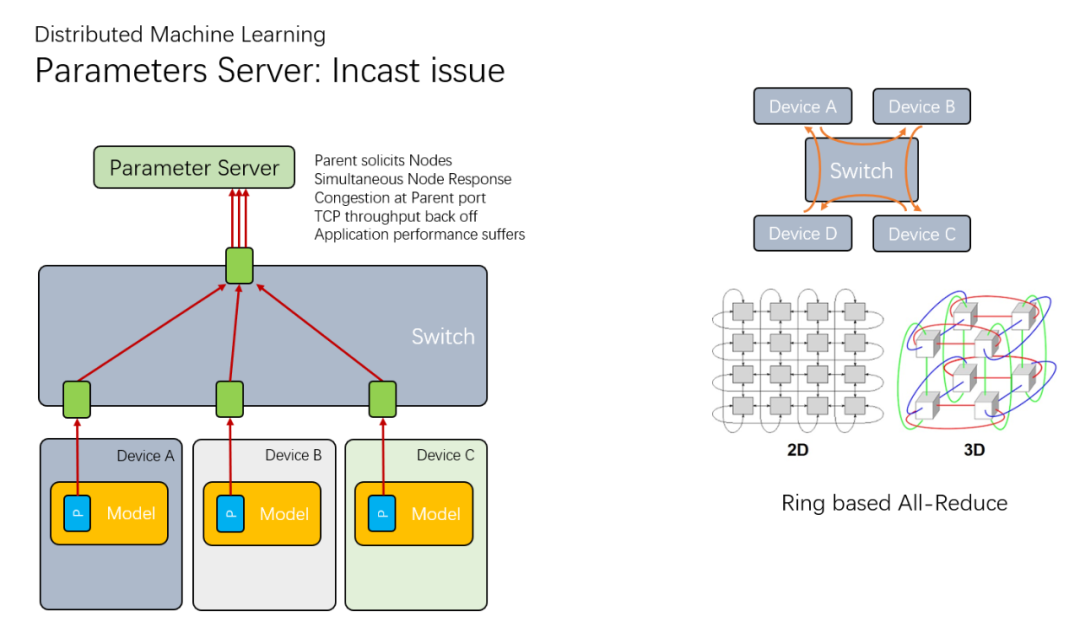
而对于nVidia而言,它们极力的扩大NVLink的带宽,同时也快速的迭代NCCL,都是为了解决这个AllReduce的问题,但是这些只在单机或者一个极度紧耦合的集群内部。另一方面主机间的通信,自然就选择了超算中非常常见的RDMA了。
但是即便如此,AllReduce的延迟还是极大的影响了整个训练集群的规模:
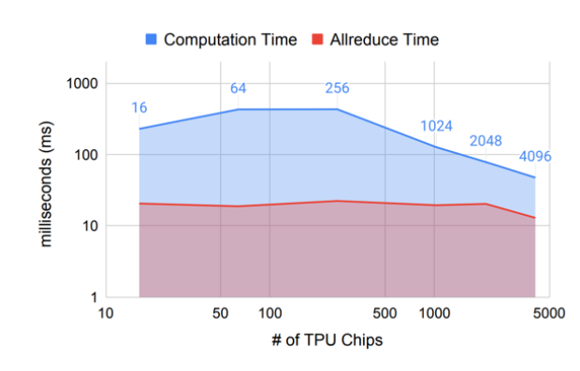
本文实现了四个节点做RoCEv2 AllReduce的测试结果,可以看到在参数规模较高时耗时非常长,例如 0.5Billion 个float32参数做AllReduce需要接近3s的时间,具体测试方法参见本文后半部分
即便是ZeRO-Infinity解决了GPU内存墙的问题,也不得不面对AllReduce的瓶颈:
Ring-Allreduce算法
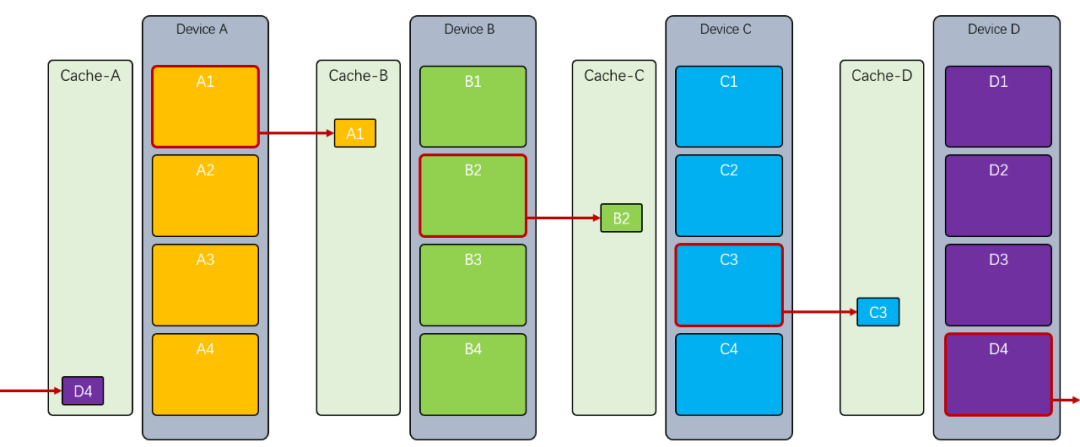
我们以最常见的Ring Allreduce为例来介绍整个算法,然后我们再通过MPI手把手实现并进行性能评估.首先每个设备都有自己训练好的参数,我们根据节点数将其分为块,例如时,设备的参数为 ,B为 以此类推
int comm_rank;
int comm_size;
MPI_Comm_rank(communicator, &comm_rank);
MPI_Comm_size(communicator, &comm_size);
//split dataset
int segment_size = count / comm_size;
int residual = count % comm_size;
int *segment_sizes = (int *)malloc(sizeof(int) * comm_size);
int *segment_start_ptr = (int *)malloc(sizeof(int) * comm_size);
int segment_ptr = 0;
for (int i = 0; i < comm_size; i++)
{
segment_start_ptr[i] = segment_ptr;
segment_sizes[i] = segment_size;
if (i < residual)
segment_sizes[i]++;
segment_ptr += segment_sizes[i];
}
if (segment_start_ptr[comm_size - 1] + segment_sizes[comm_size - 1] != count)
{
MPI_Abort(MPI_COMM_WORLD, MPI_ERR_COUNT);
}复制
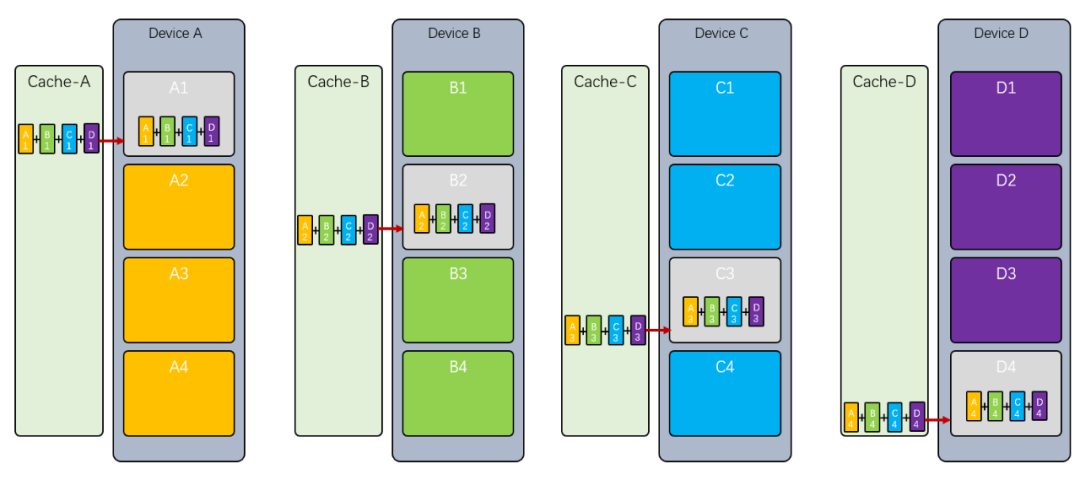
首先我们将 发到 , 发到 , 发到 , 发到 ,然后设备将其接收到的数据和其相同下标的值相加,并发送给下一个节点, 例如 收到后,将的结果发送给:
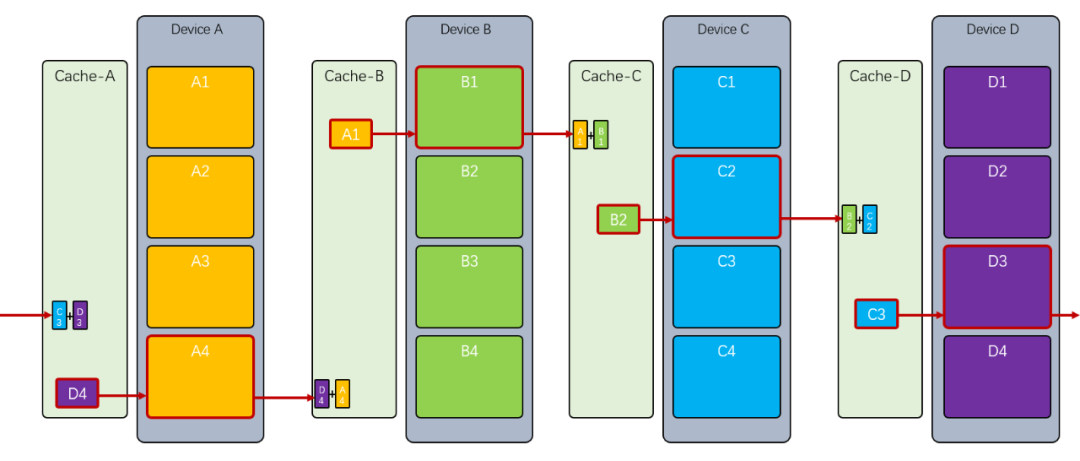
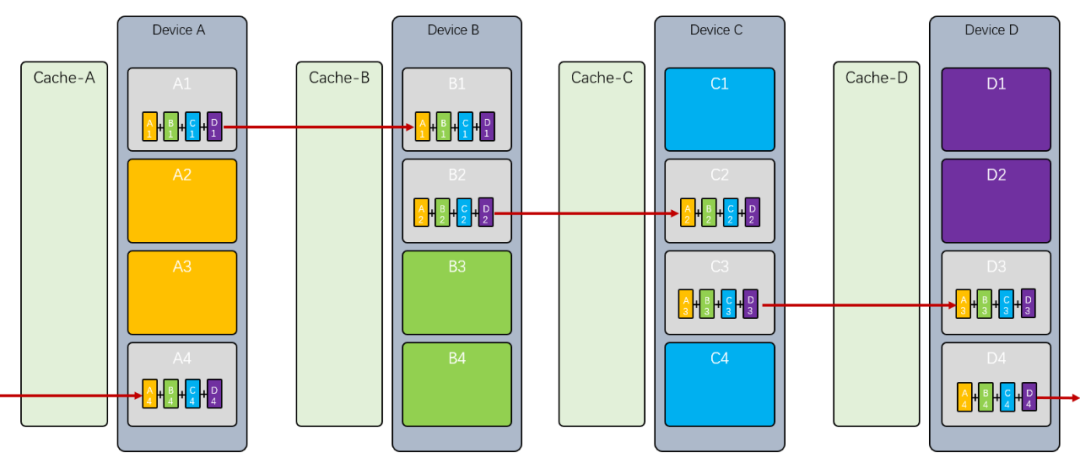
然后 收到后,又和本地的 相加,并发送给,其它节点以此类推:
MPI_Status recv_status;
MPI_Request recv_req;
float *buffer = (float *)malloc(sizeof(float) * segment_sizes[0]);
for (int iter = 0; iter < comm_size - 1; iter++)
{
int recv_chunk = (comm_rank - iter - 1 + comm_size) % comm_size;
int send_chunk = (comm_rank - iter + comm_size) % comm_size;
float *sending_segment = &(data[segment_start_ptr[send_chunk]]);
MPI_Irecv(buffer, segment_sizes[recv_chunk], datatype, prev(comm_rank, comm_size), 0, communicator, &recv_req);
MPI_Send(sending_segment, segment_sizes[send_chunk], datatype, next(comm_rank, comm_size), 0, communicator);
float *updating_segment = &(data[segment_start_ptr[recv_chunk]]);
MPI_Wait(&recv_req, &recv_status);
//after send recieve finshed, execute reduce
reduceSUM(updating_segment, buffer, segment_sizes[recv_chunk]);
}
MPI_Barrier(communicator);
void reduceSUM(float *dst, float *src, int size)
{
for (int i = 0; i < size; i++)
dst[i] += src[i];
}复制
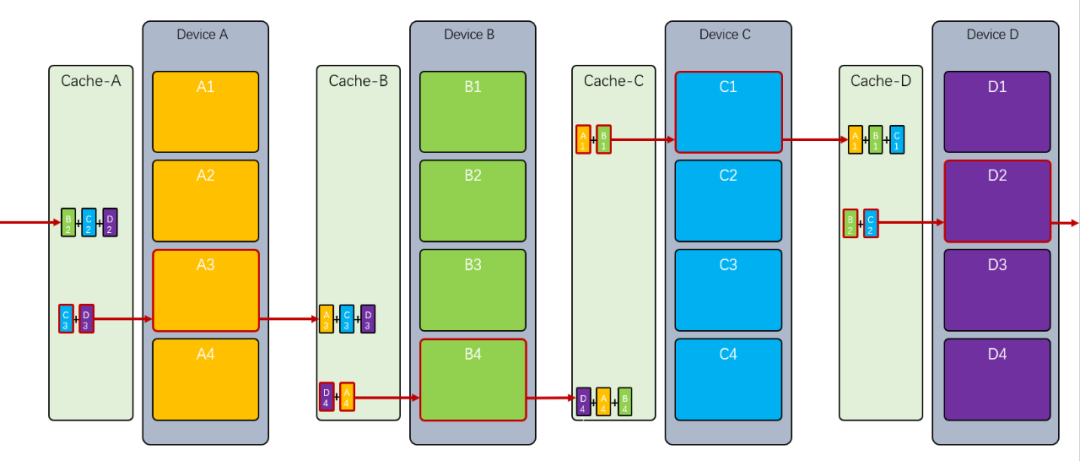
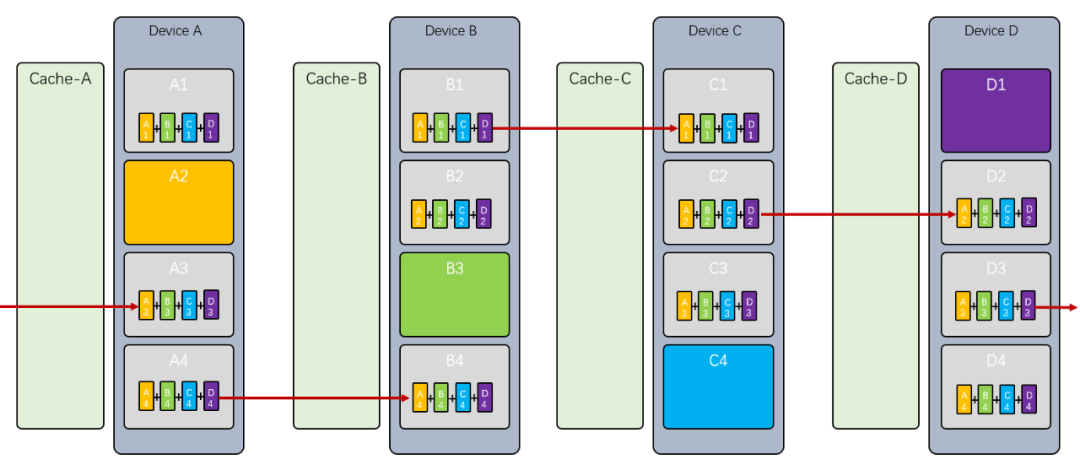
最后将 算好后,发送给,将 算好后,发送给,以此类推:
//allGather
for (int iter = 0; iter < comm_size - 1; iter++)
{
int recv_chunk = (comm_rank - iter + comm_size) % comm_size;
int send_chunk = (comm_rank - iter + 1 + comm_size) % comm_size;
float *sending_segment = &(data[segment_start_ptr[send_chunk]]);
float *updating_segment = &(data[segment_start_ptr[recv_chunk]]);
MPI_Sendrecv(sending_segment, segment_sizes[send_chunk], datatype, next(comm_rank, comm_size), 0, updating_segment, segment_sizes[recv_chunk], datatype, prev(comm_rank, comm_size), 0, communicator, &recv_status);
}复制
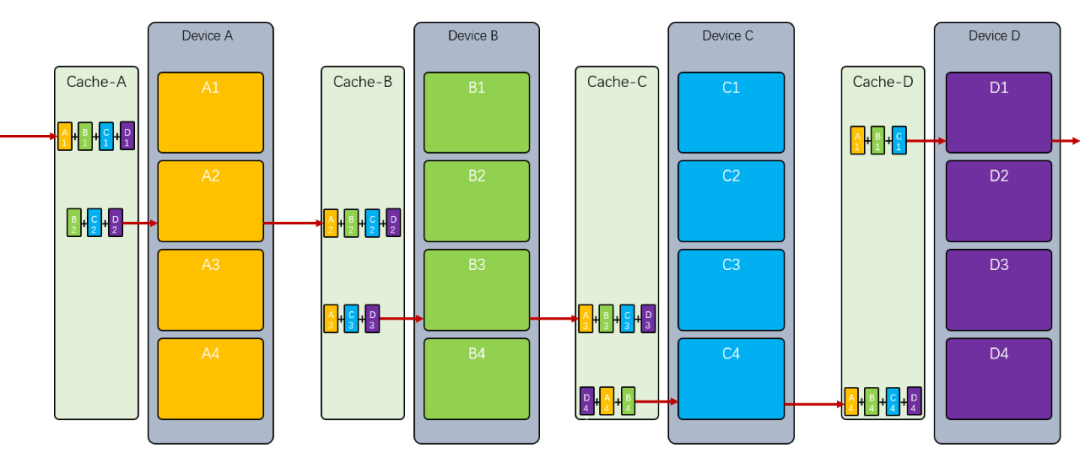
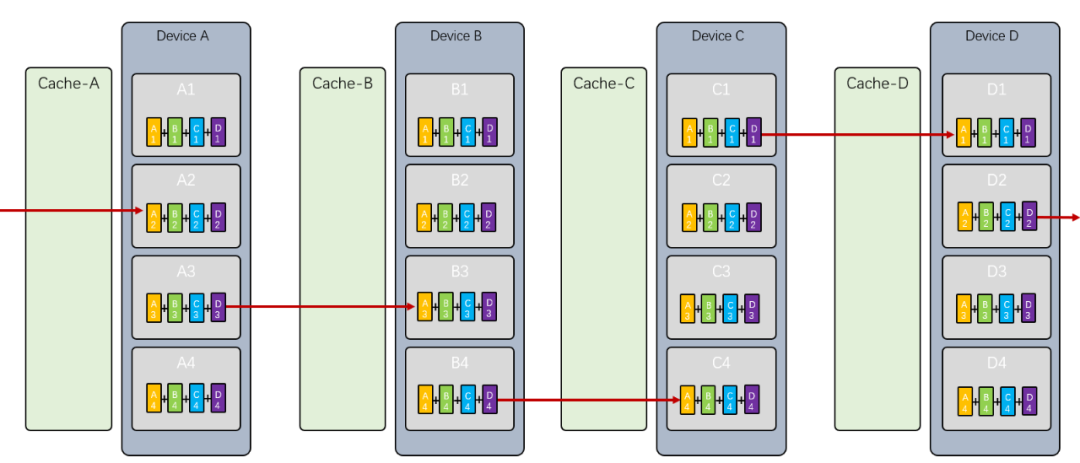
最终拥有了同步好的, 拥有了同步好的 ,拥有了同步好的, 拥有了同步好的
下一步就是将顺序写入, 将顺序写入 ,将顺序写入, 将顺序写入
最终就完成了同步
实战1:构建RoCEv2环境
专用的IB集群容易导致Vendor Locking等问题,而且从效率和成本上而言,以太网有更大的优势, 因此通常在一些超算或者云NVMeOF等环境中还是选择RoCEv2,本次搭建RoCEv2的设备如下,交换机采用了Cisco Nexus93180FX2, 四台Cisco UCS C240M5服务器,配置如下
| 型号 | 数量 | 备注 | |
|---|---|---|---|
| CPU | Intel Xeon Gold 6230R | 2 | |
| 内存 | DDR4 2933Mhz 32GB | 12 | |
| 网卡 | Mellnanox CX516A | 1 | |
| 操作系统 | CentOS 8.4 |
系统安装
1.添加PowerTools并更新系统:
sudo dnf -y install dnf-plugins-core
sudo dnf -y install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm
sudo dnf config-manager --set-enabled powertools
yum makecache
yum update复制
验证PCIe带宽是否满足要求,8GT为PCIe3.0,但是一定要16x才能满足100G单口同时收发传输. 选择支持PCIe4.0的处理器会更好:)
[zartbot@C240M5-1 mpi]$ lspci | grep Mell
5e:00.0 Ethernet controller: Mellanox Technologies MT28800 Family [ConnectX-5 Ex]
5e:00.1 Ethernet controller: Mellanox Technologies MT28800 Family [ConnectX-5 Ex]
[zartbot@C240M5-1 mpi]$ lspci -n | grep 5e:00
5e:00.0 0200: 15b3:1019
5e:00.1 0200: 15b3:1019
[zartbot@C240M5-1 mpi]$ sudo lspci -d 15b3:1019 -vvv
[sudo] password for zartbot:
5e:00.0 Ethernet controller: Mellanox Technologies MT28800 Family [ConnectX-5 Ex]
Subsystem: Cisco Systems Inc Device 02ac
Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr+ Stepping- SERR+ FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0, Cache Line Size: 32 bytes
Interrupt: pin A routed to IRQ 42
NUMA node: 0
IOMMU group: 84
Region 0: Memory at 3fffc000000 (64-bit, prefetchable) [size=32M]
Expansion ROM at c5e00000 [disabled] [size=1M]
Capabilities: [60] Express (v2) Endpoint, MSI 00
DevCap: MaxPayload 512 bytes, PhantFunc 0, Latency L0s unlimited, L1 unlimited
ExtTag+ AttnBtn- AttnInd- PwrInd- RBE+ FLReset+ SlotPowerLimit 0.000W
DevCtl: CorrErr+ NonFatalErr+ FatalErr+ UnsupReq-
RlxdOrd+ ExtTag+ PhantFunc- AuxPwr- NoSnoop+ FLReset-
MaxPayload 256 bytes, MaxReadReq 512 bytes
DevSta: CorrErr+ NonFatalErr- FatalErr- UnsupReq+ AuxPwr- TransPend-
LnkCap: Port #0, Speed 16GT/s, Width x16, ASPM not supported
ClockPM- Surprise- LLActRep- BwNot- ASPMOptComp+
LnkCtl: ASPM Disabled; RCB 64 bytes, Disabled- CommClk+
ExtSynch- ClockPM- AutWidDis- BWInt- AutBWInt-
LnkSta: Speed 8GT/s (downgraded), Width x16 (ok) <<<<<<<<<<<<<<<<<<关注此行
TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-复制
安装开发软件
主要是用于后面安装mlx5 ofed和编译DPDK所需的工具,注意下面的一个都不能少, 特别是注意 libnl3-devel,如果缺失编译DPDK会出现找不到libibverbs很多函数的错误.但是DPDK不是本次测试的必须项目,只是为了另一个项目验证VPP性能而安装的
yum groupinstall -y "Development tools"
yum install -y gcc-gfortran kernel-modules-extra tcl tk tcsh tmux kernel-rpm-macros elfutils-libelf-devel libnl3-devel meson createrepo numactl-devel
pip3 install pyelftools复制
启用iommu
sudo vi /etc/default/grub
//在 GRUB_CMDLINE_LINUX 行添加"intel_iommu=on iommu=pt"
GRUB_CMDLINE_LINUX="crashkernel=auto resume=/dev/mapper/cl-swap rd.lvm.lv=cl/root rd.lvm.lv=cl/swap rhgb quiet intel_iommu=on iommu=pt"
//保存退出复制
然后更新grub
sudo grub2-mkconfig -o /boot/grub2/grub.cfg
sudo grub2-mkconfig -o /boot/efi/EFI/centos/grub.cfg复制
重启系统准备安装 此时必须要重启一次系统, 否则在ofed安装的时候会由于前面yum update了kernel报错.
reboot复制
安装MLX-OFED驱动
重启后继续使用root登录,在如下连接下载:
https://www.mellanox.com/products/infiniband-drivers/linux/mlnx_ofed
然后解压安装,注意安装时选择带上参数--upstream-libs --dpdk --add-kernel-support
tar vzxf MLNX_OFED_LINUX-5.4-1.0.3.0-rhel8.4-x86_64.tgz
cd MLNX_OFED_LINUX-5.4-1.0.3.0-rhel8.4-x86_64/
./mlnxofedinstall --upstream-libs --dpdk --add-kernel-support复制
安装时间有点慢,等一下,完成后按照提示更新initramfs,然后重启
dracut -f
reboot复制
重启后检查IB状态和接口名称:
[zartbot@C240M5-1 mpi]$ ibv_devinfo
hca_id: mlx5_0
transport: InfiniBand (0)
fw_ver: 16.28.4000
node_guid: b8ce:f603:00a9:2cca
sys_image_guid: b8ce:f603:00a9:2cca
vendor_id: 0x02c9
vendor_part_id: 4121
hw_ver: 0x0
board_id: CIS0000000003
phys_port_cnt: 1
port: 1
state: PORT_ACTIVE (4)
max_mtu: 4096 (5)
active_mtu: 1024 (3)
sm_lid: 0
port_lid: 0
port_lmc: 0x00
link_layer: Ethernet复制
检查协议是不是RoCEv2
sudo cma_roce_mode -d mlx5_0
RoCE v2
如果不是按照如下方式设置:
sudo cma_roce_mode -d mlx5_0 -m 2复制
安装HPC-X
下载地址:
https://developer.nvidia.com/networking/hpc-x
使用非root登录
下载,并将其解压到/opt/hpcx
tar -xvf hpcx-v2.9.0-gcc-MLNX_OFED_LINUX-5.4-1.0.3.0-redhat8.4-x86_64.tbz
mv hpcx-v2.9.0-gcc-MLNX_OFED_LINUX-5.4-1.0.3.0-redhat8.4-x86_64 /opt/hpcx
cd /opt/hpcx复制
验证:
export HPCX_HOME=$PWD
source $HPCX_HOME/hpcx-init.sh
hpcx_load
env | grep HPCX
mpicc $HPCX_MPI_TESTS_DIR/examples/hello_c.c -o $HPCX_MPI_TESTS_DIR/examples/hello_c
mpirun -np 2 $HPCX_MPI_TESTS_DIR/examples/hello_c
oshcc $HPCX_MPI_TESTS_DIR/examples/hello_oshmem_c.c -o $HPCX_MPI_TESTS_DIR/examples/hello_oshmem_c
oshrun -np 2 $HPCX_MPI_TESTS_DIR/examples/hello_oshmem_c
hpcx_unload复制
配置.bashrc
>> 将如下内容添加到~/.bashrc
# User specific aliases and functions
export HPCX_HOME=/opt/hpcx
source $HPCX_HOME/hpcx-init.sh
hpcx_load复制
配置IP地址
| 主机名 | 别名 | 地址 |
|---|---|---|
| C240M5-1 | hpc1 | 10.0.0.1 |
| C240M5-2 | hpc2 | 10.0.0.2 |
| C240M5-3 | hpc3 | 10.0.0.3 |
| C240M5-4 | hpc4 | 10.0.0.4 |
配置/etc/hosts
cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.0.1 hpc1
10.0.0.2 hpc2
10.0.0.3 hpc3
10.0.0.4 hpc4复制
6.配置免密SSH登录及NFS共享
ssh-key-gen
ssh-copy-id -i .ssh/id_rsa.pub zartbot@hpc2
ssh-copy-id -i .ssh/id_rsa.pub zartbot@hpc3
ssh-copy-id -i .ssh/id_rsa.pub zartbot@hpc4复制
在/etc/fstab添加您的NFS路径
192.168.99.67:/opt/ruta /opt/ruta nfs复制
配置mpi的host file,并放入NFS目录供四台机器访问,例如/opt/ruta/mpi/hf1
hpc1 slots=1
hpc2 slots=1
hpc3 slots=1
hpc4 slots=1复制
关闭防火墙并配置网卡PFC和DSCP
sudo systemctl stop firewalld.service
sudo systemctl disable firewalld.service
sudo sysctl -w net.ipv4.tcp_ecn=0
sudo cma_roce_tos -d mlx5_0 -t 106
sudo echo 106|sudo tee /sys/class/infiniband/mlx5_0/tc/1/traffic_class复制
PFC
[zartbot@C240M5-1 mpi]$ sudo mlnx_qos -i ens2f0 --pfc 0,0,0,0,0,1,0,0
DCBX mode: OS controlled
Priority trust state: pcp
default priority:
Receive buffer size (bytes): 130944,130944,0,0,0,0,0,0,
Cable len: 7
PFC configuration:
priority 0 1 2 3 4 5 6 7
enabled 0 0 0 0 0 1 0 0
buffer 0 0 0 0 0 1 0 0
tc: 1 ratelimit: unlimited, tsa: vendor
priority: 0
tc: 0 ratelimit: unlimited, tsa: vendor
priority: 1
tc: 2 ratelimit: unlimited, tsa: vendor
priority: 2
tc: 3 ratelimit: unlimited, tsa: vendor
priority: 3
tc: 4 ratelimit: unlimited, tsa: vendor
priority: 4
tc: 5 ratelimit: unlimited, tsa: vendor
priority: 5
tc: 6 ratelimit: unlimited, tsa: vendor
priority: 6
tc: 7 ratelimit: unlimited, tsa: vendor
priority: 7复制
交换机配置
hardware access-list tcam region ing-l3-vlan-qos 256
congestion-control random-detect forward-nonecn
hardware qos nodrop-queue-thresholds Queue-green 1000
priority-flow-control watch-dog-interval on
class-map type qos match-all RoCEv2-CNP
match dscp 48
class-map type qos match-all RoCEv2-DATA
match dscp 26
policy-map type qos QOS_MARKING
class RoCEv2-DATA
set qos-group 5
class RoCEv2-CNP
set qos-group 6
policy-map type network-qos QOS-NETWORK
class type network-qos c-8q-nq5
pause pfc-cos 5
mtu 2240
system qos
service-policy type network-qos QOS-NETWORK
policy-map type queuing QOS-EGRESS-100G-PORT
class type queuing c-out-8q-q5
bandwidth remaining percent 70
random-detect minimum-threshold 400 kbytes maximum-threshold 800 kbytes drop-probability 5 weight 7 ecn
class type queuing c-out-8q-q6
priority level 2
shape min 0 mbps max 50000 mbps
class type queuing c-out-8q-q3
bandwidth remaining percent 0
class type queuing c-out-8q-q4
bandwidth remaining percent 0
class type queuing c-out-8q-q2
bandwidth remaining percent 0
class type queuing c-out-8q-q1
bandwidth remaining percent 0
class type queuing c-out-8q-q-default
bandwidth remaining percent 20
class type queuing c-out-8q-q7
priority level 1
class type queuing c-out-8q-q-default
bandwidth remaining percent 15
policy-map type queuing QOS-INGRESS-100G-PORT
class type queuing c-in-q5
pause buffer-size 147456 pause-threshold 114688 resume-threshold 107688
interface eth1/51-54
priority-flow-control mode on
priority-flow-control watch-dog-interval on
service-policy type qos input QOS_MARKING
service-policy type queuing input QOS-INGRESS-100G-PORT
service-policy type queuing output QOS-EGRESS-100G-PORT复制
MPI AllReduce代码
首先是通过malloc伪造一些数据用于计算,其中local_param用于系统原生的AllReduce操作,而local_param2用于Ring AllReduce的操作
float *local_param = (float *)malloc(sizeof(float) * num_ele_per_node);
float *local_param2 = (float *)malloc(sizeof(float) * num_ele_per_node);
for (int i = 0; i < num_ele_per_node; i++)
{
local_param[i] = world_rank;
local_param2[i] = world_rank;
}复制
系统原生API使用
float *global_sum = (float *)malloc(sizeof(float) * num_ele_per_node);
MPI_Allreduce(local_param, global_sum, num_ele_per_node, MPI_FLOAT, MPI_SUM, MPI_COMM_WORLD);复制
Ring-Allreduce collective.h文件内容
void ringAllReduce(float *data, int count, MPI_Datatype datatype, MPI_Comm communicator);复制
collective.c文件内容
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include "mpi.h"
#include "collective.h"
int next(int rank, int size)
{
return ((rank + 1) % size);
}
int prev(int rank, int size)
{
return ((size + rank - 1) % size);
}
void reduceSUM(float *dst, float *src, int size)
{
for (int i = 0; i < size; i++)
dst[i] += src[i];
}
void ringAllReduce(float *data, int count, MPI_Datatype datatype, MPI_Comm communicator)
{
int comm_rank;
int comm_size;
MPI_Comm_rank(communicator, &comm_rank);
MPI_Comm_size(communicator, &comm_size);
//split dataset
int segment_size = count / comm_size;
int residual = count % comm_size;
int *segment_sizes = (int *)malloc(sizeof(int) * comm_size);
int *segment_start_ptr = (int *)malloc(sizeof(int) * comm_size);
int segment_ptr = 0;
for (int i = 0; i < comm_size; i++)
{
segment_start_ptr[i] = segment_ptr;
segment_sizes[i] = segment_size;
if (i < residual)
segment_sizes[i]++;
segment_ptr += segment_sizes[i];
}
if (segment_start_ptr[comm_size - 1] + segment_sizes[comm_size - 1] != count)
{
MPI_Abort(MPI_COMM_WORLD, MPI_ERR_COUNT);
}
MPI_Status recv_status;
MPI_Request recv_req;
float *buffer = (float *)malloc(sizeof(float) * segment_sizes[0]);
for (int iter = 0; iter < comm_size - 1; iter++)
{
int recv_chunk = (comm_rank - iter - 1 + comm_size) % comm_size;
int send_chunk = (comm_rank - iter + comm_size) % comm_size;
float *sending_segment = &(data[segment_start_ptr[send_chunk]]);
MPI_Irecv(buffer, segment_sizes[recv_chunk], datatype, prev(comm_rank, comm_size), 0, communicator, &recv_req);
MPI_Send(sending_segment, segment_sizes[send_chunk], datatype, next(comm_rank, comm_size), 0, communicator);
float *updating_segment = &(data[segment_start_ptr[recv_chunk]]);
MPI_Wait(&recv_req, &recv_status);
//after send recieve finshed, execute reduce
reduceSUM(updating_segment, buffer, segment_sizes[recv_chunk]);
}
MPI_Barrier(communicator);
//allGather
for (int iter = 0; iter < comm_size - 1; iter++)
{
int recv_chunk = (comm_rank - iter + comm_size) % comm_size;
int send_chunk = (comm_rank - iter + 1 + comm_size) % comm_size;
float *sending_segment = &(data[segment_start_ptr[send_chunk]]);
float *updating_segment = &(data[segment_start_ptr[recv_chunk]]);
MPI_Sendrecv(sending_segment, segment_sizes[send_chunk], datatype, next(comm_rank, comm_size), 0, updating_segment, segment_sizes[recv_chunk], datatype, prev(comm_rank, comm_size), 0, communicator, &recv_status);
}
free(buffer);
}复制
测BenchMark的主程序内容 main.c
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include "mpi.h"
#include "collective.h"
int main(int argc, char **argv)
{
/*if (argc != 3)
{
fprintf(stderr, "Usage: allreduce node_per_host num_ele_per_node\n");
exit(1);
}*/
int ret; //return code
char hn[257];
ret = gethostname(hn, 257);
if (ret)
{
perror("gethostname");
return ret;
}
printf("Hostname: %s\n", hn);
int node_per_host = 4; //= atoi(argv[1]);
long num_ele_per_node = 32; // atoi(argv[2]);
double mpi_start_time, mpi_end_time, ring_mpi_start_time, ring_mpi_end_time;
int world_rank, world_size;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
if (world_size % node_per_host != 0)
{
printf("Invalid configuration...");
MPI_Abort(MPI_COMM_WORLD, MPI_ERR_BASE);
}
if (world_rank == 0)
{
printf("%20s %20s %22s %22s\n", "DataSize(Bytes)", "Num of float", "Native Allreduce", "Ring Allreduce");
}
for (int i = 0; i < 13; i++)
{
// Prepare Data
float *local_param = (float *)malloc(sizeof(float) * num_ele_per_node);
float *local_param2 = (float *)malloc(sizeof(float) * num_ele_per_node);
for (int i = 0; i < num_ele_per_node; i++)
{
local_param[i] = world_rank;
local_param2[i] = world_rank;
}
//Build-in Allreduce as a reference
float *global_sum = (float *)malloc(sizeof(float) * num_ele_per_node);
MPI_Barrier(MPI_COMM_WORLD);
mpi_start_time = MPI_Wtime();
MPI_Allreduce(local_param, global_sum, num_ele_per_node, MPI_FLOAT, MPI_SUM, MPI_COMM_WORLD);
MPI_Barrier(MPI_COMM_WORLD);
MPI_Allreduce(local_param, global_sum, num_ele_per_node, MPI_FLOAT, MPI_SUM, MPI_COMM_WORLD);
MPI_Barrier(MPI_COMM_WORLD);
MPI_Allreduce(local_param, global_sum, num_ele_per_node, MPI_FLOAT, MPI_SUM, MPI_COMM_WORLD);
MPI_Barrier(MPI_COMM_WORLD);
mpi_end_time = MPI_Wtime();
/* if (world_rank == 0)
printf("build-in mpi time:%15.0fus\n", (mpi_end_time - mpi_start_time) * 1e6);
*/
#ifdef DEBUG
if (world_rank == 0)
{
for (int i = 0; i < num_ele_per_node; i++)
printf("global_sum[%d]: %f, avg: %f\n", i, global_sum[i], global_sum[i] / world_size);
}
#endif
MPI_Barrier(MPI_COMM_WORLD);
ring_mpi_start_time = MPI_Wtime();
ringAllReduce(local_param2, num_ele_per_node, MPI_FLOAT, MPI_COMM_WORLD);
MPI_Barrier(MPI_COMM_WORLD);
ringAllReduce(local_param2, num_ele_per_node, MPI_FLOAT, MPI_COMM_WORLD);
MPI_Barrier(MPI_COMM_WORLD);
ringAllReduce(local_param2, num_ele_per_node, MPI_FLOAT, MPI_COMM_WORLD);
MPI_Barrier(MPI_COMM_WORLD);
ring_mpi_end_time = MPI_Wtime();
/*if (world_rank == 0)
{
printf("allnode-ring time:%15.0fus\n", (ring_mpi_end_time - ring_mpi_start_time) * 1e6);
}*/
free(global_sum);
free(local_param);
free(local_param2);
if (world_rank == 0)
{
printf("%20ld %20ld %20.1fus %20.1fus\n", num_ele_per_node * 4, num_ele_per_node, (mpi_end_time - mpi_start_time) / 3 * 1e6, (ring_mpi_end_time - ring_mpi_start_time) / 3 * 1e6);
}
MPI_Barrier(MPI_COMM_WORLD);
num_ele_per_node = num_ele_per_node * 4;
}
MPI_Finalize();
}复制
编译
mpicc collective.c main.c -o foo复制
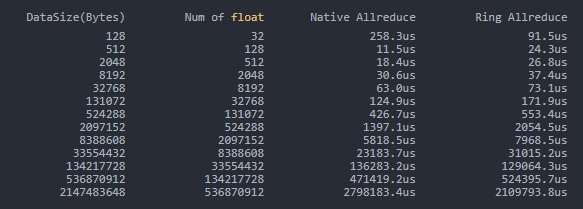
RoCEv2 AllReduce性能测试
[zartbot@C240M5-1 mpi]$ mpirun -mca pml ucx -x UCX_NET_DEVICES=mlx5_0:1 -x UCX_IB_ETH_PAUSE_ON=y -x UCX_TLS=sm,ud -hostfile hf1 /opt/ruta/mpi/allreduce/foo
Hostname: C240M5-1
Hostname: C240M5-3
Hostname: C240M5-2
Hostname: C240M5-4
DataSize(Bytes) Num of float Native Allreduce Ring Allreduce
128 32 258.3us 91.5us
512 128 11.5us 24.3us
2048 512 18.4us 26.8us
8192 2048 30.6us 37.4us
32768 8192 63.0us 73.1us
131072 32768 124.9us 171.9us
524288 131072 426.7us 553.4us
2097152 524288 1397.1us 2054.5us
8388608 2097152 5818.5us 7968.5us
33554432 8388608 23183.7us 31015.2us
134217728 33554432 136283.2us 129064.3us
536870912 134217728 471419.2us 524395.7us
2147483648 536870912 2798183.4us 2109793.8us复制
备注
如果遇到性能问题,交换机debug
PrivN9K# show interface counters brief | in "Input|Frame|Eth1/5"复制
Interface Input Rate (avg) Output Rate (avg)
MB/s Frames MB/s Frames interval (seconds)
Eth1/5 0 0 0 0 30
Eth1/50 0 0 0 0 5
Eth1/51 1567 1529034 1566 1523520 5
Eth1/52 1566 1527008 1568 1540948 5
Eth1/53 1568 1534834 1567 1525220 5
Eth1/54 1568 1532755 1567 1534030 5复制
PrivN9K# show queueing interface e1/51 | grep -B 1 -A 12 "QOS GROUP 5"+-------------------------------------------------------------+
| QOS GROUP 5 |
+-------------------------------------------------------------+
| | Unicast |Multicast |
+-------------------------------------------------------------+
| Tx Pkts | 202328436| 0|
| Tx Byts | 203884632744| 0|
| WRED/AFD & Tail Drop Pkts | 0| 0|
| WRED/AFD & Tail Drop Byts | 0| 0|
| Q Depth Byts | 0| 0|
| WD & Tail Drop Pkts | 0| 0|
+-------------------------------------------------------------+
| QOS GROUP 6 |
+-------------------------------------------------------------+复制
PrivN9K# show queuing interface e1/51 | grep -A 40 "Ingress"复制
Ingress Queuing for Ethernet1/51
-----------------------------------------------------
QoS-Group# Pause
Buff Size Pause Th Resume Th
-----------------------------------------------------
7 - - -
6 - - -
5 348608 77376 75712
4 - - -
3 - - -
2 - - -
1 - - -
0 - - -
Per Port Ingress Statistics
--------------------------------------------------------
Hi Priority Drop Pkts 0
Low Priority Drop Pkts 0
Ingress Overflow Drop Pkts 19490
--------------------------------------------------------
Per Slice Ingress Statistics
--------------------------------------------------------
Ingress Overflow Drop Pkts 71206
PFC Statistics
------------------------------------------------------------------------------
TxPPP: 150, RxPPP: 0
------------------------------------------------------------------------------
PFC_COS QOS_Group TxPause TxCount RxPause RxCount
0 0 Inactive 0 Inactive 0
1 0 Inactive 0 Inactive 0
2 0 Inactive 0 Inactive 0
3 0 Inactive 0 Inactive 0
4 0 Inactive 0 Inactive 0
5 5 Inactive 150 Inactive 0
6 0 Inactive 0 Inactive 0
7 0 Inactive 0 Inactive 0
------------------------------------------------------------------------------复制
PrivN9K# show interface priority-flow-control detail | grep -A 40 Ethernet1/51复制
Admin Mode: On
Oper Mode: On
VL bitmap: (20)
Total Rx PFC Frames: 0
Total Tx PFC Frames: 150
---------------------------------------------------------------------------------------------------------------------
| Priority0 | Priority1 | Priority2 | Priority3 | Priority4 | Priority5 | Priority6 | Priority7 |
---------------------------------------------------------------------------------------------------------------------
Rx |0 |0 |0 |0 |0 |0 |0 |0
---------------------------------------------------------------------------------------------------------------------
Tx |0 |0 |0 |0 |0 |150 |0 |0
Ethernet1/52
Admin Mode: On
Oper Mode: On
VL bitmap: (20)
Total Rx PFC Frames: 0
Total Tx PFC Frames: 143
---------------------------------------------------------------------------------------------------------------------
| Priority0 | Priority1 | Priority2 | Priority3 | Priority4 | Priority5 | Priority6 | Priority7 |
---------------------------------------------------------------------------------------------------------------------
Rx |0 |0 |0 |0 |0 |0 |0 |0
---------------------------------------------------------------------------------------------------------------------
Tx |0 |0 |0 |0 |0 |143 |0 |0
Ethernet1/53
Admin Mode: On
Oper Mode: On
VL bitmap: (20)
Total Rx PFC Frames: 0
Total Tx PFC Frames: 101
---------------------------------------------------------------------------------------------------------------------
| Priority0 | Priority1 | Priority2 | Priority3 | Priority4 | Priority5 | Priority6 | Priority7 |
---------------------------------------------------------------------------------------------------------------------
Rx |0 |0 |0 |0 |0 |0 |0 |0
---------------------------------------------------------------------------------------------------------------------
Tx |0 |0 |0 |0 |0 |101 |0 |0
Ethernet1/54
Admin Mode: On复制
PrivN9K# show interface priority-flow-control detail | grep -A 60 Ethernet1/51复制
Ethernet1/51
Admin Mode: On
Oper Mode: On
VL bitmap: (20)
Total Rx PFC Frames: 0
Total Tx PFC Frames: 150
---------------------------------------------------------------------------------------------------------------------
| Priority0 | Priority1 | Priority2 | Priority3 | Priority4 | Priority5 | Priority6 | Priority7 |
---------------------------------------------------------------------------------------------------------------------
Rx |0 |0 |0 |0 |0 |0 |0 |0
---------------------------------------------------------------------------------------------------------------------
Tx |0 |0 |0 |0 |0 |150 |0 |0
Ethernet1/52
Admin Mode: On
Oper Mode: On
VL bitmap: (20)
Total Rx PFC Frames: 0
Total Tx PFC Frames: 143
---------------------------------------------------------------------------------------------------------------------
| Priority0 | Priority1 | Priority2 | Priority3 | Priority4 | Priority5 | Priority6 | Priority7 |
---------------------------------------------------------------------------------------------------------------------
Rx |0 |0 |0 |0 |0 |0 |0 |0
---------------------------------------------------------------------------------------------------------------------
Tx |0 |0 |0 |0 |0 |143 |0 |0
Ethernet1/53
Admin Mode: On
Oper Mode: On
VL bitmap: (20)
Total Rx PFC Frames: 0
Total Tx PFC Frames: 101
---------------------------------------------------------------------------------------------------------------------
| Priority0 | Priority1 | Priority2 | Priority3 | Priority4 | Priority5 | Priority6 | Priority7 |
---------------------------------------------------------------------------------------------------------------------
Rx |0 |0 |0 |0 |0 |0 |0 |0
---------------------------------------------------------------------------------------------------------------------
Tx |0 |0 |0 |0 |0 |101 |0 |0
Ethernet1/54
Admin Mode: On
Oper Mode: On
VL bitmap: (20)
Total Rx PFC Frames: 0
Total Tx PFC Frames: 4
---------------------------------------------------------------------------------------------------------------------
| Priority0 | Priority1 | Priority2 | Priority3 | Priority4 | Priority5 | Priority6 | Priority7 |
---------------------------------------------------------------------------------------------------------------------
Rx |0 |0 |0 |0 |0 |0 |0 |0
---------------------------------------------------------------------------------------------------------------------
Tx |0 |0 |0 |0 |0 |4 |0 |0复制
