





“ 「效能(Effective)」如何只能从企业外部评价,而不是企业内部。企业内部只有成本要素,所以,使用「效率」这个词可能更加贴切一些。”
作者:乔梁
来源:《持续交付2.0》第三章
1
狭义的研发效能就是指
2
以「瀑布开发方法」为代表的传统软件开发方法,虽然强调每个阶段的输入输出质量,但是在项目前期只是产出大量的详细文档,却没有开发出可以运行的软件。直到进入后期集成测试阶段,才将所有代码模块放在一起运行起来。
这种做法导致发现软件问题的时机较晚,缺陷被发现之后的修复成本也比较高。《代码大全2》一书,对于缺陷产生的成本也有如下的表述:
「发现错误的时间要尽可能接近引入该错误的时间。缺陷在软件食物链里面呆的时间越长,它对食物链的后级造成损害就越严重。由于需求是首先要完成的事情,需求的缺陷就有可能在系统中潜伏更长的时间,代价也更加昂贵。」
详见以下引用图表,从表中数据可以看出“引入缺陷的时间和找到缺陷的时间”与“修复缺陷成本”之间的成本倍数关系。
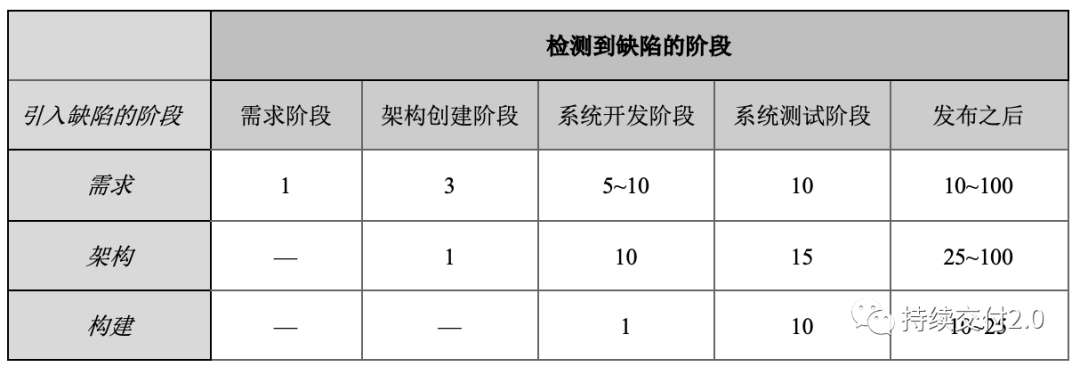
缺陷引入阶段、发现阶段与修复成本之间的关系
这种企图通过后期大规模检查达成软件质量目标的做法,恰恰与戴明博士的质量观点背道而驰。戴明博士是世界著名的质量管理大师,他提出的质量管理“十四条”是全面质量管理的重要理论基础。
其中的第三要点如下:
「我们无法依靠大批量的检验来达到质量标准。依靠检验提高质量已经太迟了,且成本高而效益低。正确的做法,从生产过程的开始之处,就做到质量内建。」
「质量内建」就是从生产过程的第一个环节开始,就要注重产出物的质量,并且在每个环节中都要开展质量保障活动,消除因质量问题导致的返工及次品率,以此降低最终的质量风险,保障进度。
3
在第一章中,我们讨论了精益思想关于“浪费”的定义,显然“等待”就是不必要的一种浪费。在日常工作中,我们经常会遇到一些等待,而这些等待已司空见惯,大家习以为常。然而,提升效率的最有效方法也许就是消除各环节的等待。
1、通过「拉动(Pull)」让价值流动起来
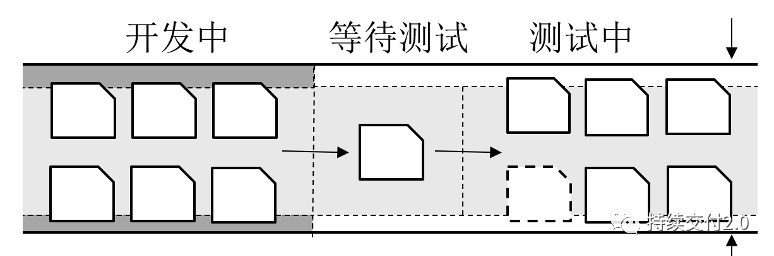
当管理者把重心放到「人」的效率上时,很容易出现的现象是:「所有人都很忙,但产出并没有提升」的情况。这是局部优化的结果。此时通常会出现中间产物堆积等待现象,如下图所示。
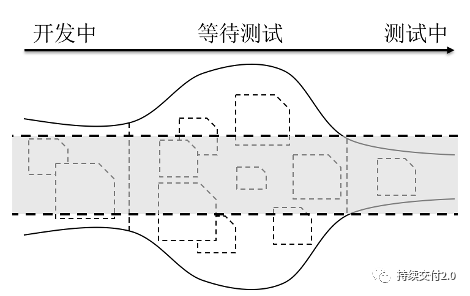
由于下游环节的产能相对不足,导致中间产物流动不畅。而就是此时,所有人可能都在满负荷工作。
开发人员继续开发更多的需求,对团队的整体产出并没有直接帮助,只会增加测试环节的压力。而压力过载后,可能会引发更多的问题,比如开发人员在质量尚不确定的代码上继续开发更多的功能,可能导致更多的缺陷。要想解决这个问题,需要将管理关注点先从「人」转移到「物」上。
正确的做法应该是提升下游「瓶颈」的处理能力,让更多的需求交付出去。例如,可以通过增加专职测试人员的方式,扩大测试环节的通行能力。
但是,我们很难通过增加人手的方式持续保持各环节输入与产出平衡的理想状态。此时还可以通过「临时减少开发人员,增加测试人员的方式,即:将团队部分开发人力调整到测试环节」来临时扩大测试环节的能力,达到整个系统的最大化产出。
《持续交付 2.0 》第 15 章 “小团队的逆袭之旅”所讲述的实际案例中,就使用了这种临时手段来临时提高测试环节的处理能力,保证团队的产出。
当然,这是一个临时性的解决方案。如果从整个系统的角度出发,应该根据下游的生产能力来确定上游的生产速度,即下游环节拉动上游的需求。一旦等待队列中出现空位,立即从上游填补,以此类推。
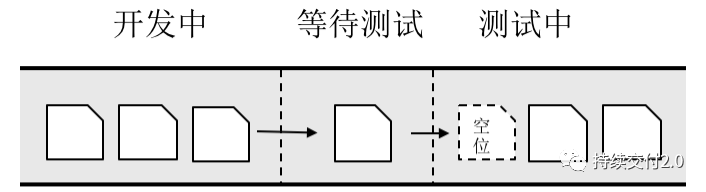
「为了达到这样的流畅效果,对于管道内的工作单元,其颗粒度应该均匀化」。也就是说,在构建环节,通过需求分解方法,将大需求分解成多个工作量相近的小需求,才能让工作变得平滑顺畅。就像在高速公路上,如果只有小轿车时,通行能力比较容易提升,但当大货车与小轿车混行时,道路的通行能力就会下降。
团队的瓶颈通常都是动态变化的。既使我们做了需求分解工作,也不能保证在任何时刻,整个系统都是平滑运行的。怎么办呢?
我们还有另外一种解决方案,那就是:利用开发环节暂时过剩的人力来建设工具平台,提升下游的基础能力,使得在不增加测试人力的情况下,永久提升团队整体产能。当然,通过提升人员整体技能水平也能达到同样的目的,如下图所示。
开发工具、提升能力、或增加瓶颈人力后,整体吞吐量提升
企业应该在工具平台建设方面改变一下建设思路,即:运用先进的生产技术,使得环境部署、数据统计这一类事务性操作不再依赖「专家型」人才,而是让每个人在其需要时都能够「自助完成」。那么每个人都可以流畅的工作,而且“专家型”人才被“打断工作”的次数也会减少。
例如,对于微服务架构的软件服务来说,如果开发人员自己无法随时搭建一套用于微服务开发调试的环境,却需在测试人员的帮助下才能搭建完成,这会令开发人员的高效工作状态被打断,同时也会打断那个提供帮助的测试人员的工作。而对于开发人员手上的工作任务来说,也只能停下来,等待测试人员搭建完调试环境才能继续。
开发人员为什么自己不能一键就搭建好自己所需的调试环境呢?这样不会打断任何人的工作,浪费任何时间。
当然,还有很多类似的场景。比如,产品人员需要一些数据统计需求,只能向数据分析师和数据工程师提出需求,由他们先排期,再去编写脚本,最后执行脚本把数据捞出来。这也会出现等待。
4
在软件研发过程中,还有很多后工且重复性的工作,即「琐事」。比如,搭建测试环境,以及应用的发布部署与发布等。在交付频率不高的情况下,这些活动并不会占用很多的工作时间。
然而,随着验证环运转速度的提高,意味着在固定的时间周期内,软件的发布频率提高,这种事务性工作的固定成本所占比例也会越来越大。当原来每个月才发布 1 次,而现在每个月发布 8 次,那么这些固定成本就提升 8 倍。而且,这种事务性工作多具有手工且机械重复性质,不应该让「人」来完成,而是应该交给善于做这类重复性工作的机器。
因此,我们必须通过优化流程和自动化措施,有效降低这些固定的事务性成本,同时避免不必要的人为操作失误,才能使其具有可持续性。《持续交付 2.0 》第 16章介绍的「研发推动的DevOps」案例中,该团队将「每三个月发布 1 次」提高为 「每两周发布 1 次」,就遇到了频繁发布所带来的成本问题,最终也是通过自动化方式解决的。
5
当软件在生产环境运行之后,我们需要能够及时准确地收集并分析数据。
对生产系统的监测有两个目的:
应用健康:确认软件的确在正常运行,一旦发现异常,我们可以及时采取措施,纠正错误,以免影响用户的使用。
业务反馈:要及时得到有效的业务数据,验证我们在探索环中提出的假设。
对于第一个目的的监测,可以称为「应用健康监测」。一般来说,传统运维领域的多数系统监控软件,都是围绕这方面展开的,例如最基础的软硬件系统健康(包括CPU、内存、存储空间、网络连接等等)。再进一步的应用健康监控则是应用自身的运行状态,如服务响应延迟时间、页面异常、缓存大小等。
对于第二个目的的监测,可以称为「业务健康监测」。其主要是针对业务指标的监测。虽然有一些基础性的日志收集整理展示平台能够展示一些业务指标。但是对于如何定义业务监控指标,通常需要业务团队根据自身的业务上下文和需求进行定制。
只有通过全面的系统监测,并在第一时间内发现异常,才能够及时应对,以确保业务可持续性发展。
6
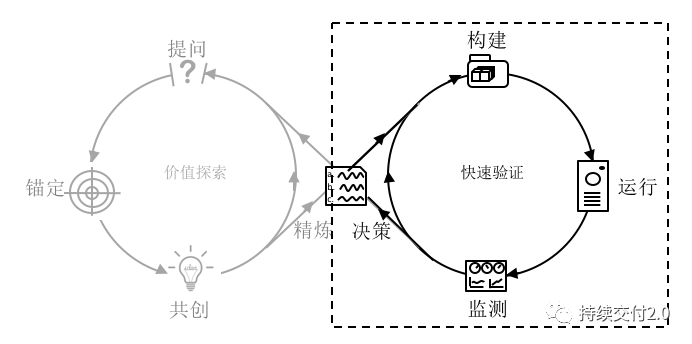
快速验证环以快速高质量交付为主,主要包括四个环节,分别是(1)构建;(2)运行;(3)监测;(4)决策。
在持续交付2.0「识别并消除一切浪费」理念的指导下,验证环的四个工作原则分别是:(1)质量内建;(2)消除等待;(3)消除琐事;(4)监测一切。
只有坚持这些指导原则,不断发现并消除工作中的浪费,才能够提升验证环的运转效度,加快对最小可行性解决方案的验证。
如果你想了解更多关于《持续交付 2.0》和 DevOps 相关内容,请点击下方链接购买。
