




前一篇文章中,我介绍了关于阅读TF源码的经验和方法,传送门如下:
教你一个读源码不会累的方法
二环宇少,公众号:互联网西门二少我是如何阅读TF源码的——方法论
文章中提到的一些阅读源码的工具,今天share给大家。
总体来说,我主要使用以下四种工具。
源代码编辑器:Visual Studio Code
Python调试工具:PDB
C++调试工具:GDB
绘图工具:draw.io或者processon
关于如何正确使用它们,且听我娓娓道来。
1
可视化跳转——借助编辑器的功能
源代码编辑器还是必要的。
虽然有人喜欢简单粗暴的用vim,配合grep命令完成调用栈的跟踪,但是在大型项目里还是略显吃力,尤其你在不怎么熟悉该项目的情况下。
所以,我还是建议选择一款在laptop上,能够可视化的代码编辑器。
关于源代码编辑器的选择,我使用了Visual Studio Code。选择原因是配色好看,且插件齐全。
在阅读源码方面,我并没有安装过多的插件,只有C++、Python、和Vim相关的东西。
Python插件和C++插件便于我追踪代码进行跳转,节省了我人工搜索代码位置的时间。
跳转方法:对着函数所在的行,按住Ctrl(或Command)+鼠标点击即可。
也可以选择其他的产品,只要基本的功能配置好,不影响体感即可。
2
细粒度跟读调用栈——使用调试器
对于大型的项目,一定存在大量类的继承、函数重载等写法。
这可能会影响代码跳转功能:多个文件存在同名同参函数,导致跳转目标不容易确定。这是编辑器常见的功能缺陷。
另一方面,我们在跟读函数调用栈时,可能会因为某个条件判断在大脑中模拟错误,导致阅读到错误的branch。这种情况如何避免?
配合PDB或GDB,确定正确的调用栈,是很好的方式。
使用PDB或者GDB的目的,就是通过单步执行,一步一步地跟着程序走。
当遇到函数调用时,我们通过输入step in命令,一定可以确定其真正的调用栈,这比编辑器中的跳转功能要靠谱得多。
使用PDB阅读Python层源码
PDB是Python的调试工具,使用极其简单,一般我会手动插入到Python文件中感兴趣的位置作为初始断点,具体如下:
假设我们写了个脚本叫做main.py,该脚本使用TensorFlow进行构图、执行训练过程。
那么当我们想窥探session.run的调用栈时,我将在下面的位置插入两行代码。
import tensorflow as tf
a = tf.constant(1.0)
sess = tf.Session()
# We import pdb module and set initial break point
import pdb
pdb.set_trace()
ret_a = sess.run(a)复制
然后我们正常启动python main.py程序即可,你会发现它停到了sess.run之前的位置。

此时,我们敲击s命令(step in)即可进入sess.run函数内部。

自此,我们知道sess.run实际的调用点位于:源码中tensorflow/python/client/session.py的第840行处,这里定义的run函数即为我们的跳转目标。
需要注意的是,我们的TensorFlow最终一定是通过pip install安装到Python的安装目录下,所以上文才跟踪到了Python安装目录中。如果你直接在自己clone的TensorFlow源码中插入PDB,是不会生效的。
你可以图方便,直接在安装目录下的TensorFlow中手动插入PDB,但调试完切记一定要改回来。
使用GDB阅读C++层源码
关于GDB的使用就麻烦多了。
当我们有了阅读C++代码的需求时,我的建议是以C++作为程序入口文件进行跟踪,而不要在从Python端调到C++的通路中进行调试。
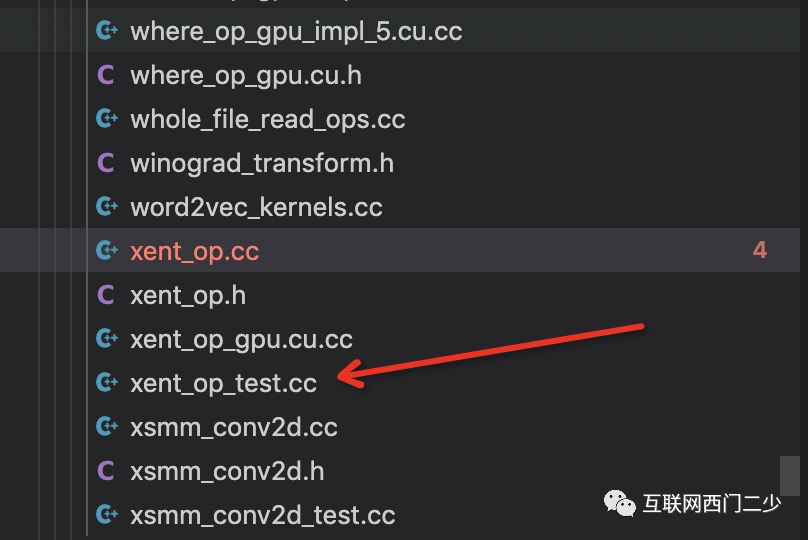
还是拿TensorFlow举例说明,假设我对xent_op.cc中的代码感兴趣(交叉熵的计算实现),我会遵循以下步骤:
先找到其目录:tensorflow/core/kernels/xent_op.cc。然后我会去找到它对应的unit test(一般情况下,大型开源项目都需要有UT保证正确性)。
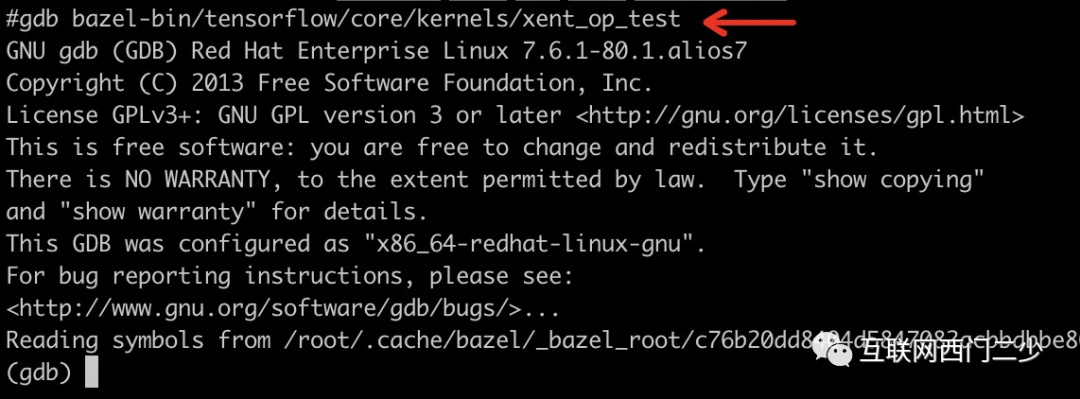
编译UT的Debug版本。我们得想办法编译这个xent_op_test.cc文件。下面这行命令将使用bazel编译xent_op_test.cc的debug版本。bazel中编译debug版本的binary需要加入-c dbg的flag。
bazel build --copt=-O -c dbg //tensorflow/core/kernels:xent_op_test复制使用gdb启动程序,并设置断点。然后你就可以按照调试正常程序一样跟读代码了。
对刚上手的同学来说,bazel的使用可能是个拦路虎。我建议花个一天到两天的时间先研究一下bazel的构建方式,这对后面阅读代码很有帮助。其实bazel并不难,它是Python的语法,干着Makefile的事。
如果TensorFlow中的某个test并不支持单独编译怎么办?比如placer_test.cc就是一个实例。
这还能怎么办,自己在BUILD文件中添加一条可以编译placer_test.cc的规则呗!
调试器的使用时机
我总结,关于PDB或者GDB的使用时机有三:
当我无法确定调用目标函数是哪一个时;
当我反复阅读,却总是在逻辑上混乱时;
当我完全读不下去时
3
好的记录习惯——绘图保存
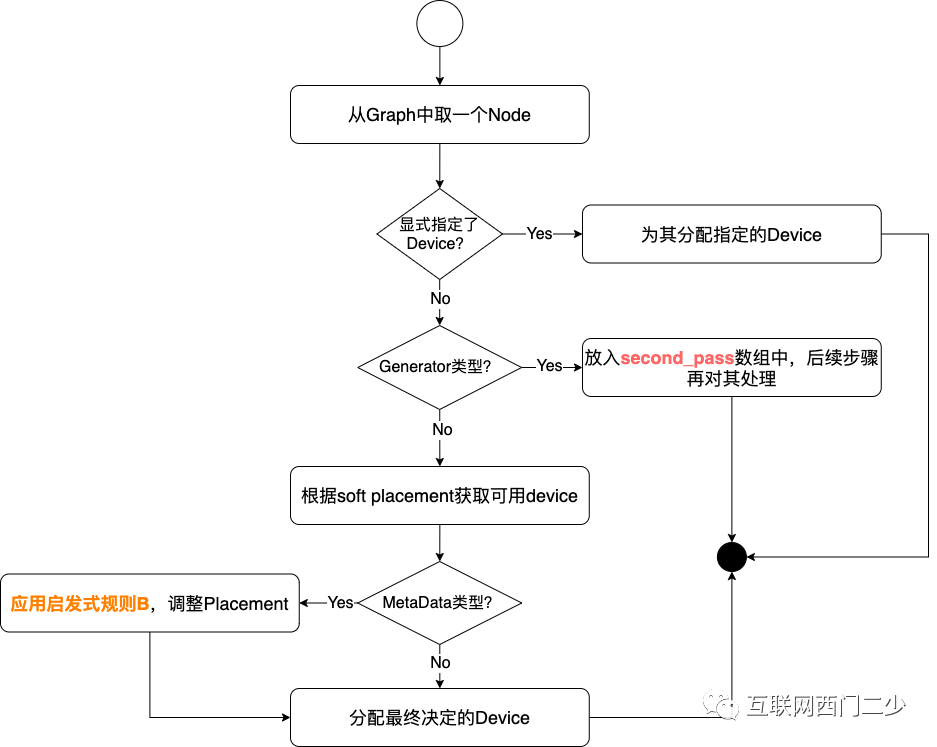
最后,为了避免遗忘,我们在梳理调用栈时和代码时最好做一些笔记,绘制调用栈层次图是一个非常有效的记录方式。
在此,我推荐draw.io或者processon这两款免费工具。它们既可以绘制普通的流程图,也可以绘制UML图。
下面是我在总结tensorflow的placer.cc中,梳理的一个过程,作为示例share在这里。
至此,你已掌握了阅读源码的方法和工具,接下来请耐心阅读自己感兴趣的模块吧!
讲技术,也谈风月,更关注程序员的生活状况,欢迎联系二少投稿你感兴趣的话题。
