




Sql: select
a.u_id,
b.b_id,
c.c_id,
from a.a a
left join b.b b on a.u id=b.u_id
left join c.c c on b.c_id=c.c_id
limit 100000;
首先把 sql 拿到生产测试发现确认要很长时间,跑了几分钟根本跑不出来。
尝试去除一个 left join 条件,等了一会跑出来了

耗时 1 分 50 秒
再看表数据量
a 表 四万条记录
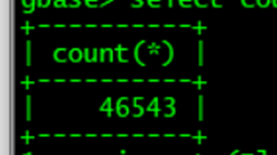
b 表将近八千万条记录
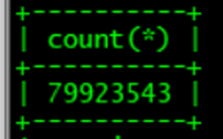
查询方式也符合查询逻辑 大小表关联查询一般用小表驱动大表
尝试用 in 看能不能快点

有一定的提升 但是根据业务逻辑需要用到 b 表中很多的字段 而 in 后面的字段 只能有一个 。
改变思路 看表的分布方式
复制表:isReplicate=YES
hash 分布表:hash_column= col_name,分布键是 col_name
随机分布表:isReplicate=NO,hash_column=null

可以看到小表 a 是随机分布表

大表 b 是哈希分布表
再看执行计划
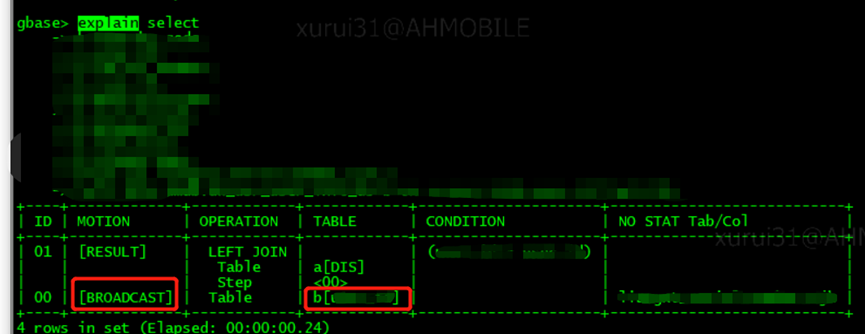
显示界面主要组成部分:
ID:SQL 执行步骤,顺序从下向上
MOTION:某个步骤的结果处理方式
OPERATION:某个步骤内的具体执行操作
TABLE:某个 operation 涉及的表
CONDITION:某个 operation 操作涉及的条件
可以看到 Motion 列有个 BROADCAST 步骤
因为小表是随机分布 即使大表是哈希分布也无法走分布键 所以小表拉了复制表
这个笔者理解应该是类似重广播 就是每一个节点都会有一份复制表
测试如果小表加上分布键会不会提升查询速度
因为 Gbase 无法在表建成后加分布键 所以新建一张测试表
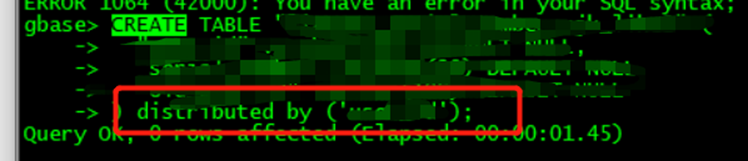
需要注意括号内的字段加单引号
再将数据导入

测试

结果是毫秒级 如果不加分布键则需要 1 分 50 秒
再看执行计划
没有了 BROADCAST 这个步骤
将结果与建议反馈业务侧



