






安装 数据加载 数据探索(EDA) 训练预测模型 模型评价 模型解释
import pandas as pdimport warningswarnings.filterwarnings('ignore')import logginglogging.basicConfig(format='%(levelname)s:%(message)s', level=logging.ERROR)from ads.dataset.factory import DatasetFactory复制

flights = DatasetFactory.open("/home/datascience/ads-examples/3P_data/flights.csv")flights.head()复制
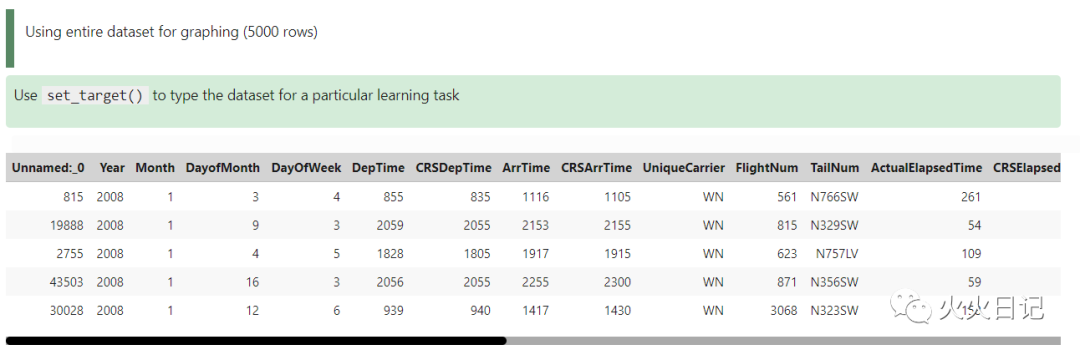
DepDelay设定为预测变量
DepDelay"DepDelay"以外的其他变量。通常我们表示为“X”
flights = flights.set_target('DepDelay')复制
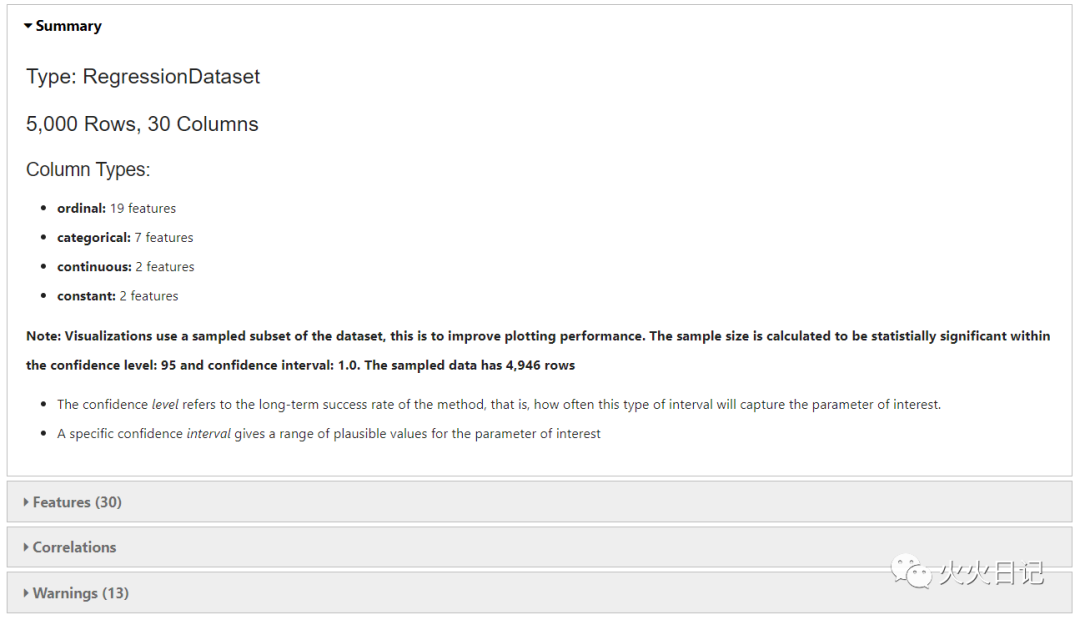
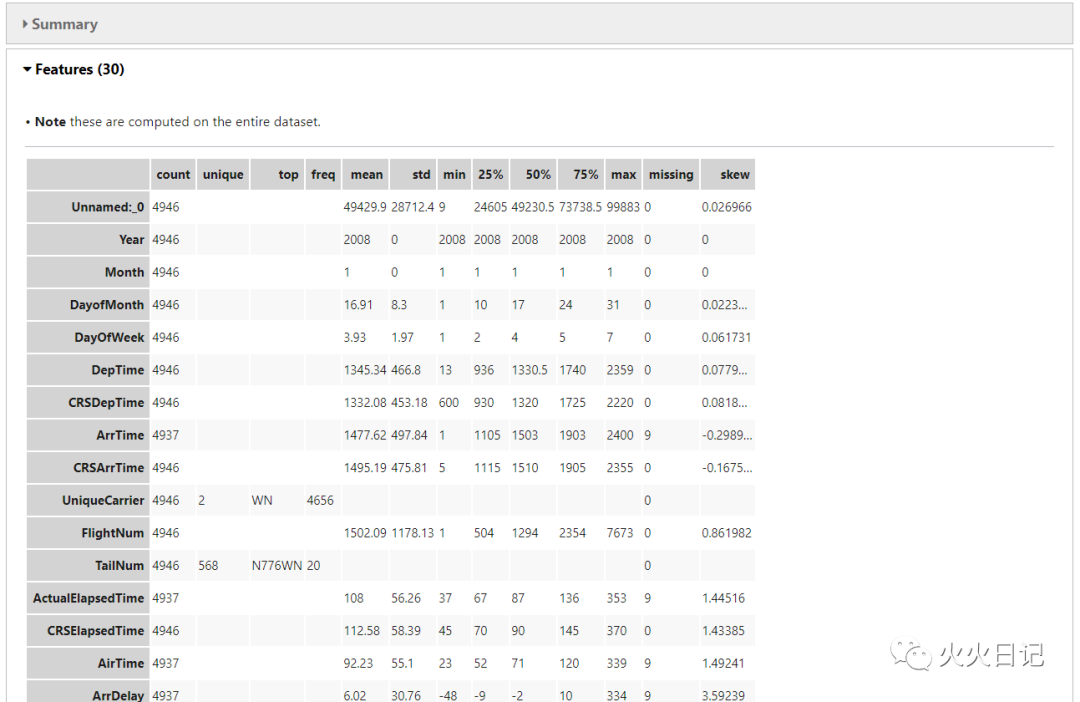
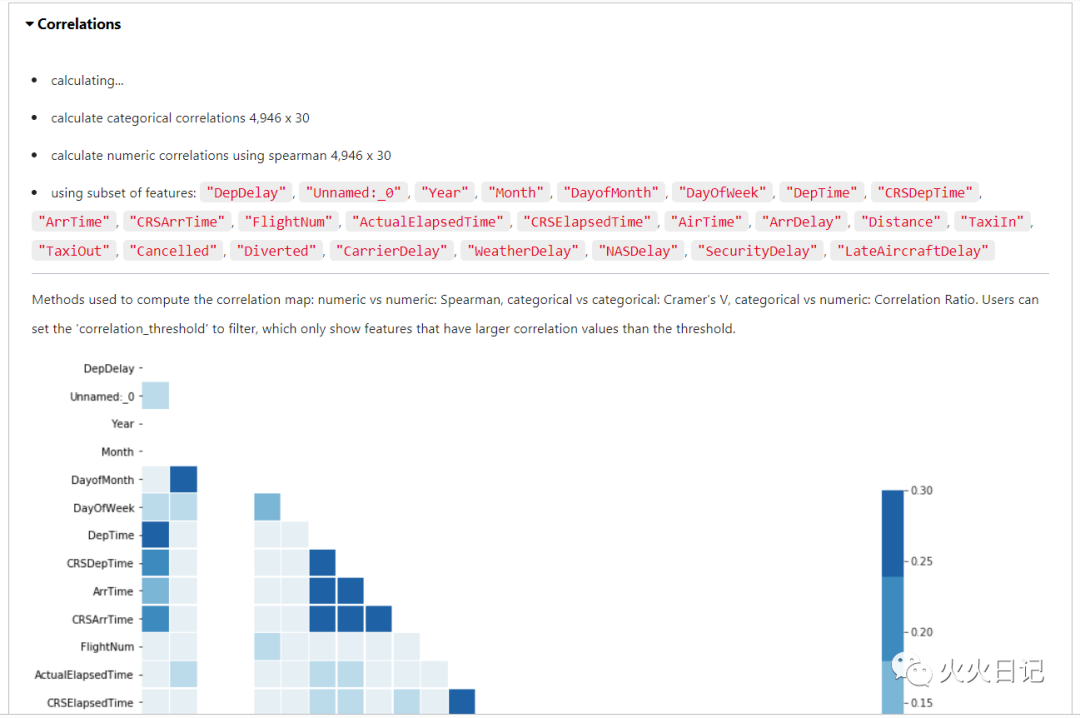
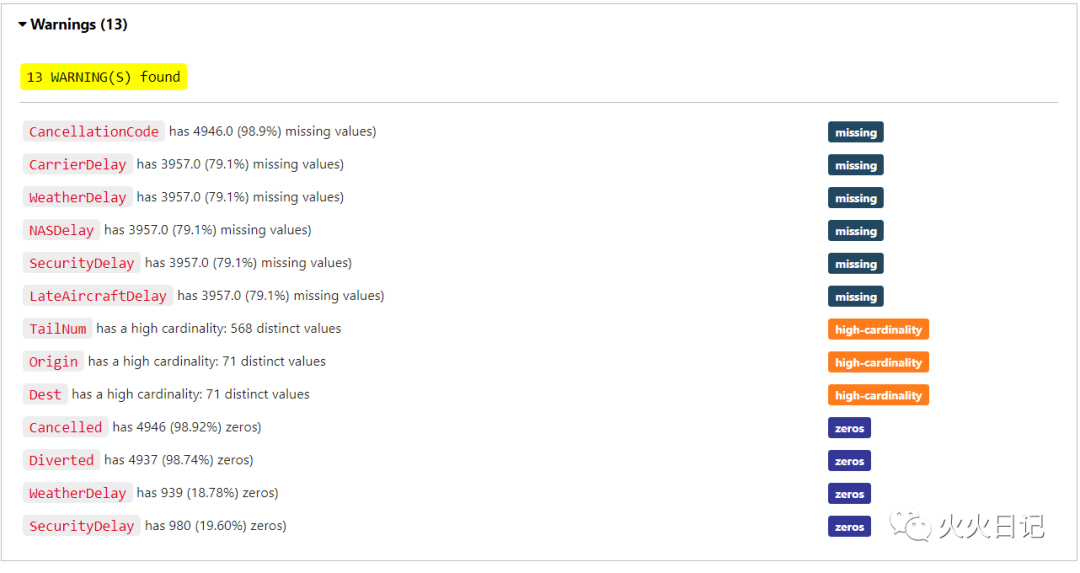
show_in_notebook()函数,可轻松确认数据分布情况,并对缺失数据、不均衡数据等问题进行自动化处理,无需单独写代码。
flights.show_in_notebook()复制
flights_nocheat = flights.drop_columns(["ArrDelay", "ArrTime", "DepTime","AirTime", "ActualElapsedTime"]).sample(frac=0.1)复制
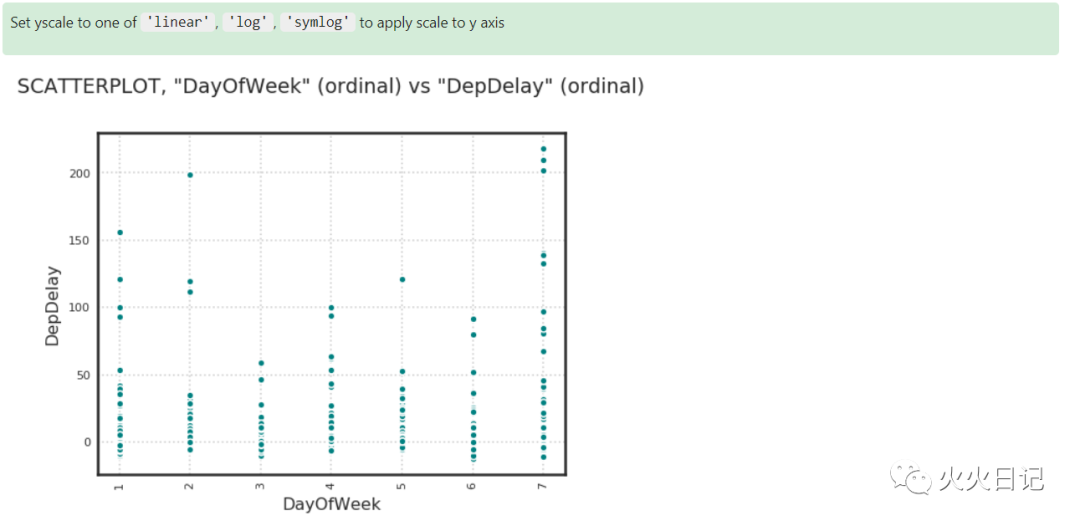
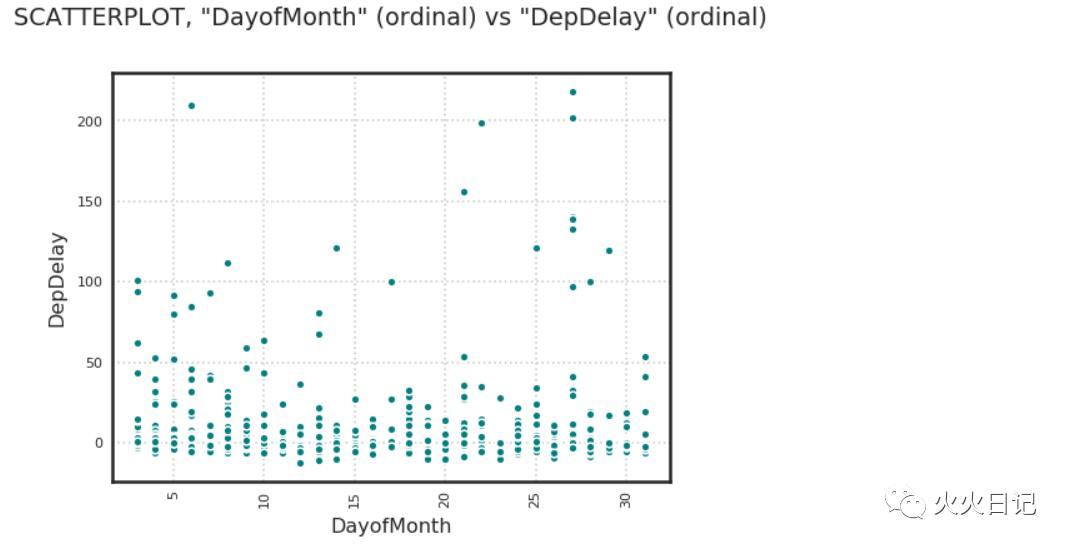
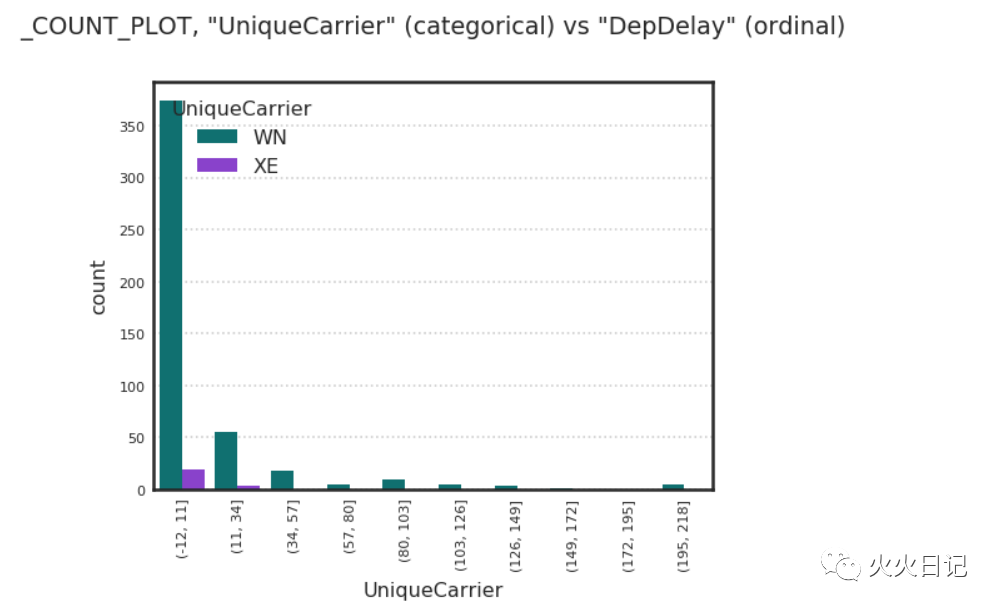
flights_nocheat.target.show_in_notebook(feature_names=["DayOfWeek", "DayofMonth","UniqueCarrier"])复制
type(flights_nocheat)# RegressionDataset复制
# 转换前show_in_notebook() 默认显示为 Histogram Graphflights_nocheat.target.show_in_notebook()复制
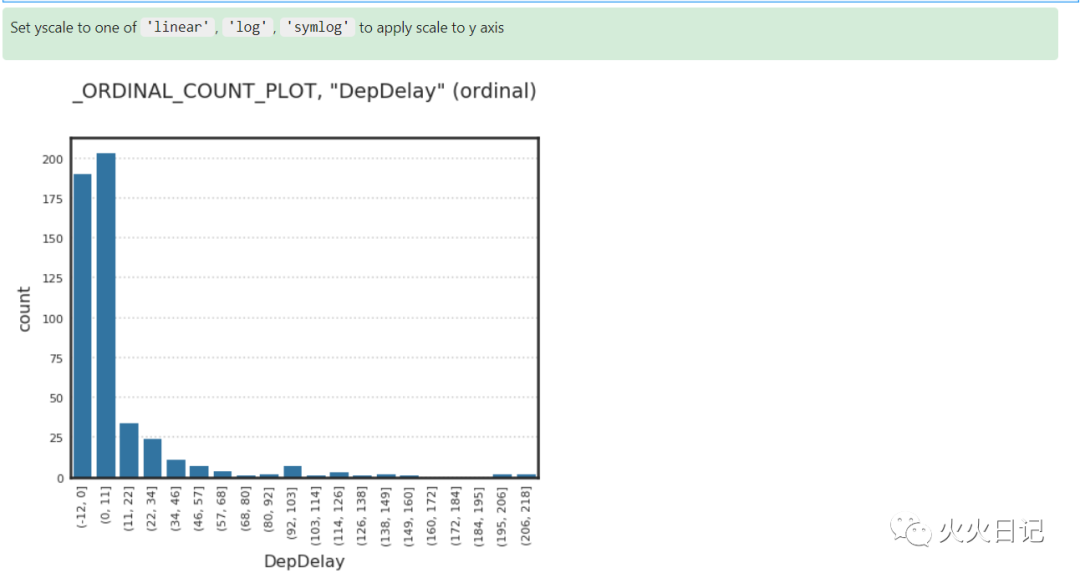
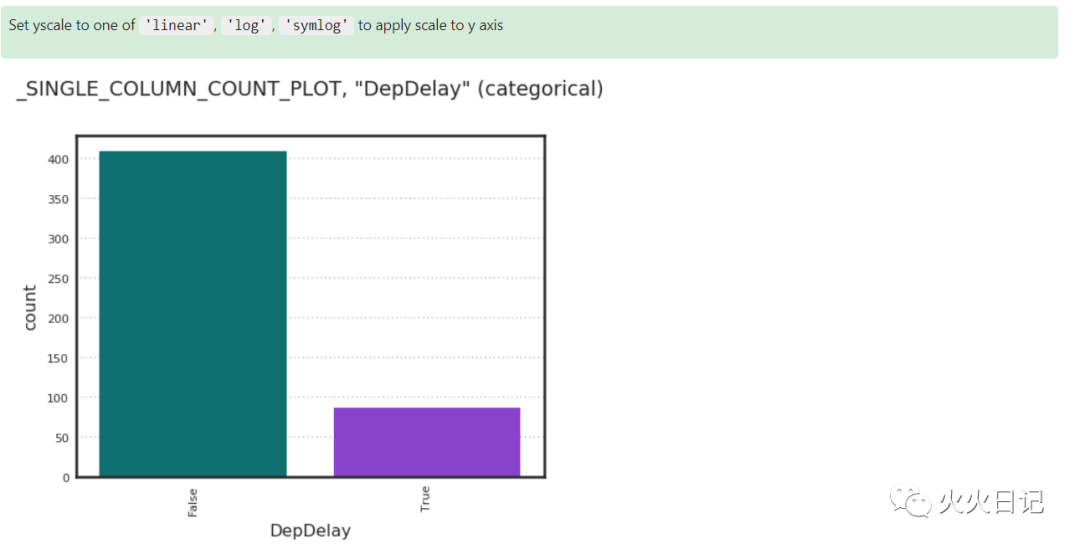
flights_binary = flights_nocheat.assign_column("DepDelay", lambda x: x is None or x>15)type(flights_binary)# BinaryClassificationDataset复制
# 数据转换后, show_in_notebook() 默认显示为Count Plot Graphflights_binary.target.show_in_notebook()复制
删除常数和主键字段 缺失值自动填补 删除线性相关的自变量 非均衡数据自动处理
flights_binary.get_recommendations()复制
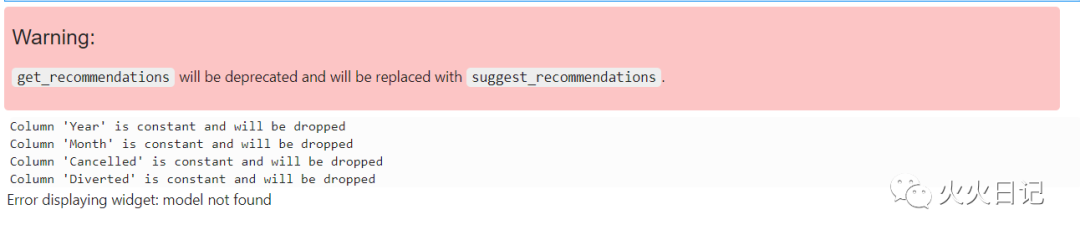
flights_clean = flights_binary.auto_transform(fix_imbalance=False)复制
flights_clean.show_in_notebook()复制
[len(flights_binary.columns), len(flights_clean.columns)]复制

# 相关性Top12变量选择modeling_dataset = flights_clean.select_best_features(k=12)print(modeling_dataset.columns.values)复制

import h2oimport osfrom h2o.automl import H2OAutoML复制
# H2O Proxy 初始化http_proxy = os.environ.get("http_proxy", "")HTTP_PROXY = os.environ.get("HTTP_PROXY", "")os.environ["HTTP_PROXY"] = ""os.environ["http_proxy"] = ""h2o.init()复制
h2o_df = modeling_dataset.to_h2o_dataframe()h2o_df.head(5)复制

train, valid, test = h2o_df.split_frame(ratios=list([.7, .15]), seed = 1)[train.shape, valid.shape, test.shape]复制

x = train.columnsy = "DepDelay"x.remove(y)复制
%%timeh2o_aml = H2OAutoML(max_models=20, seed=1, max_runtime_secs=100)h2o_aml.train(x=x, y=y, training_frame=train, validation_frame=valid)h2o_model = h2o_aml.leader复制

print("\nH2O Accuracy: ", (h2o_model.predict(test)[0] == test["DepDelay"]).sum() / test.shape[0])复制

os.environ["http_proxy"] = http_proxyos.environ["HTTP_PROXY"] = HTTP_PROXY复制
from ads.automl.provider import OracleAutoMLProvider复制
train, valid, test = modeling_dataset.train_validation_test_split(test_size=0.1, validation_size=0.2, random_state=42)[train.X.shape, valid.X.shape, test.X.shape]复制

回归预测中,ZeroR基准模型会预测训练数据集中的平均值 分类预测中,ZeroR基准模型会预测训练数据集中最频繁出现的值
选择最佳的变量 最少的Sampling 选择最佳的算法 选择最佳的参数
olabs_automl = OracleAutoMLProvider()复制
import lightgbm复制
%%timefrom ads.automl.driver import AutoMLautoml = AutoML(train, validation_data=valid,provider=olabs_automl)olabs_model, baseline = automl.train(min_features=["CRSDepTime", "TaxiOut"], model_list=["LogisticRegression", "LGBMClassifier", "XGBClassifier", "RandomForestClassifier"], random_state = 42, score_metric = 'roc_auc')复制
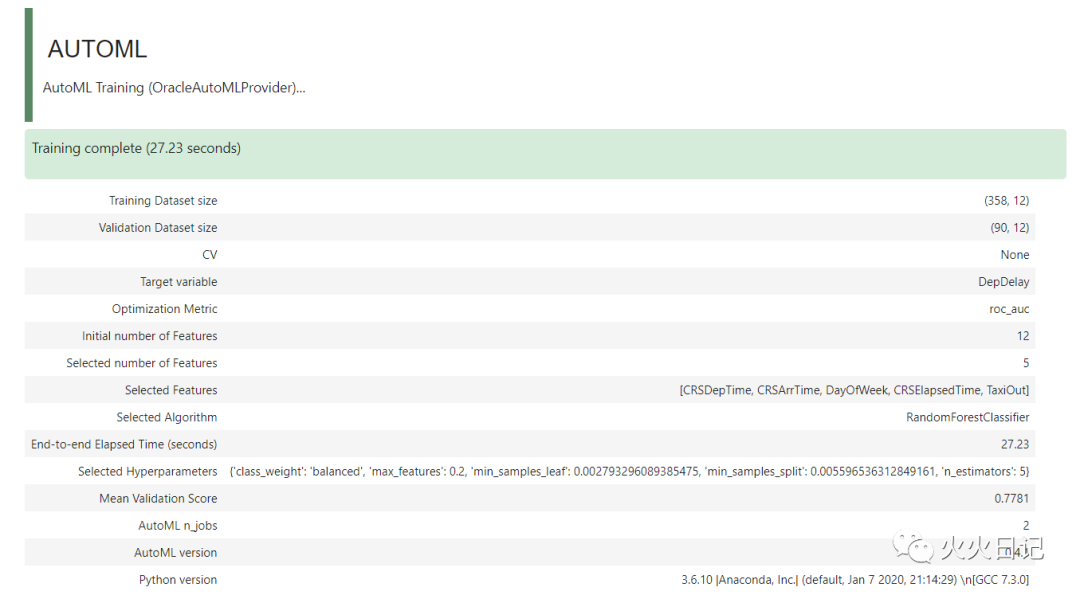
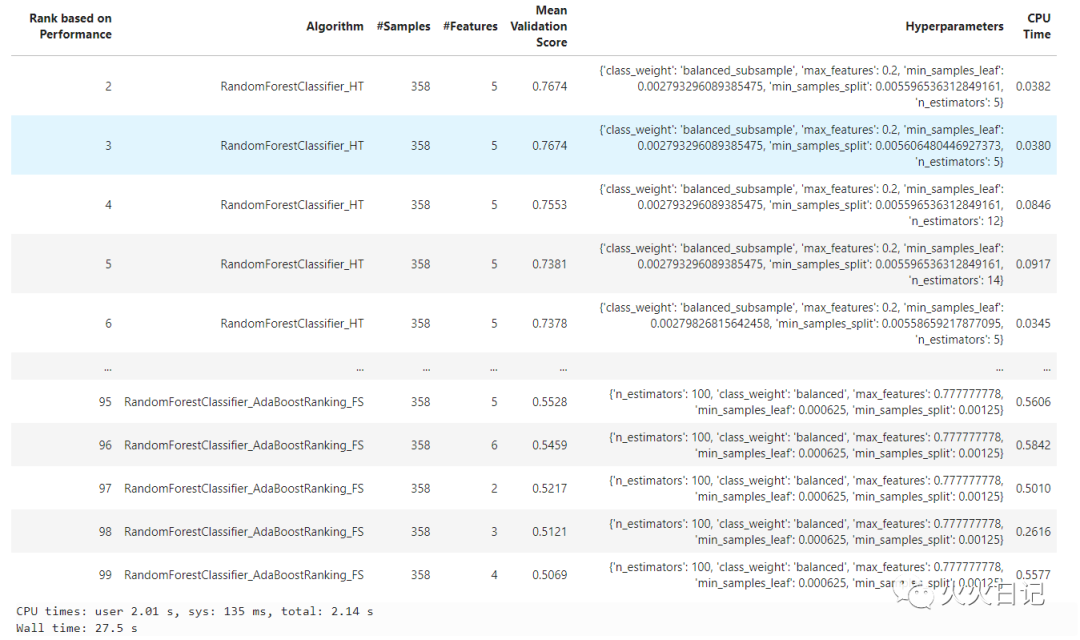
print("\nOLabs Score: ", olabs_model.score(test.X, test.y))复制

olabs_model.selected_model_params_复制

olabs_model.num_total_trials_复制

olabs_model.summary()复制

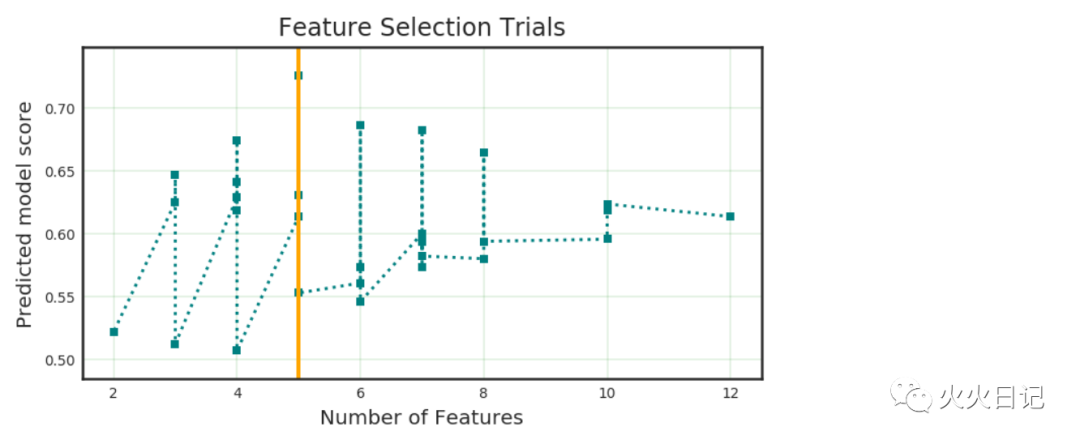
automl.visualize_feature_selection_trials()复制
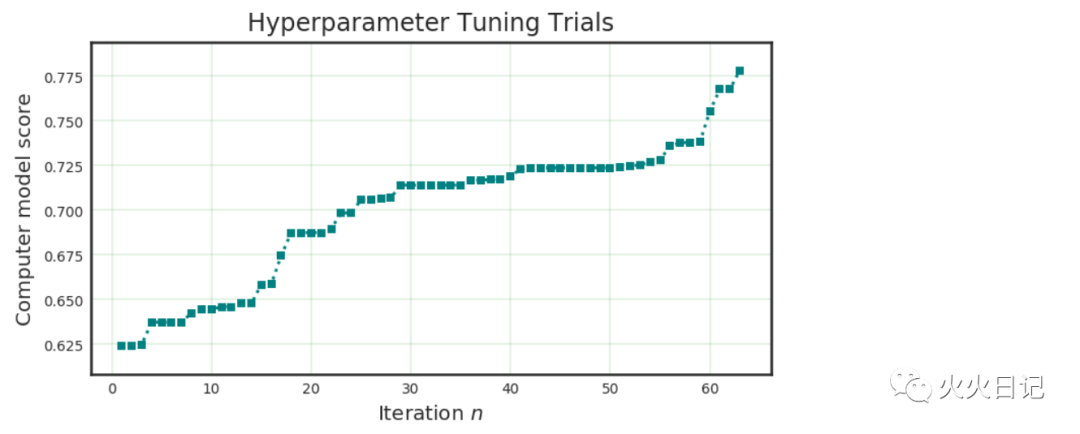
automl.visualize_tuning_trials()复制
olabs_model.visualize_transforms()复制


from ads.evaluations.evaluator import ADSEvaluatorfrom ads.common.data import MLDataevaluator = ADSEvaluator(test, models=[baseline, olabs_model])evaluator.show_in_notebook()复制


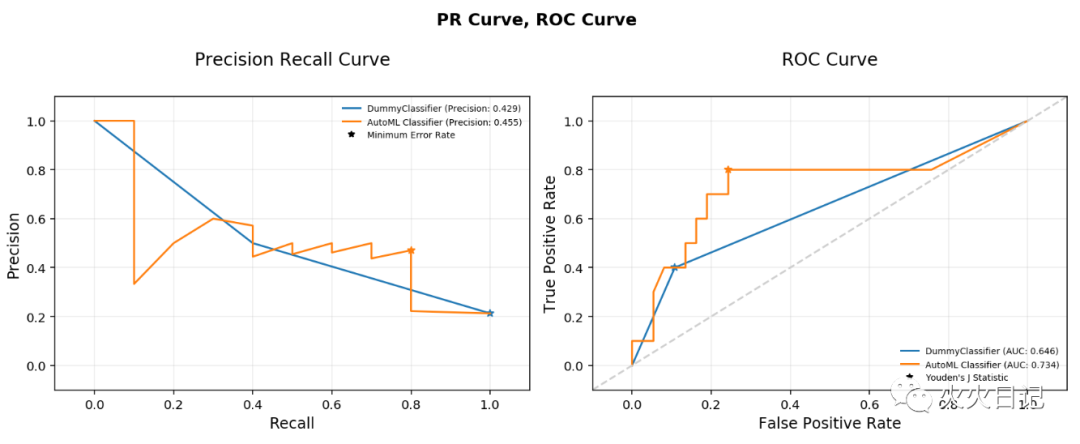
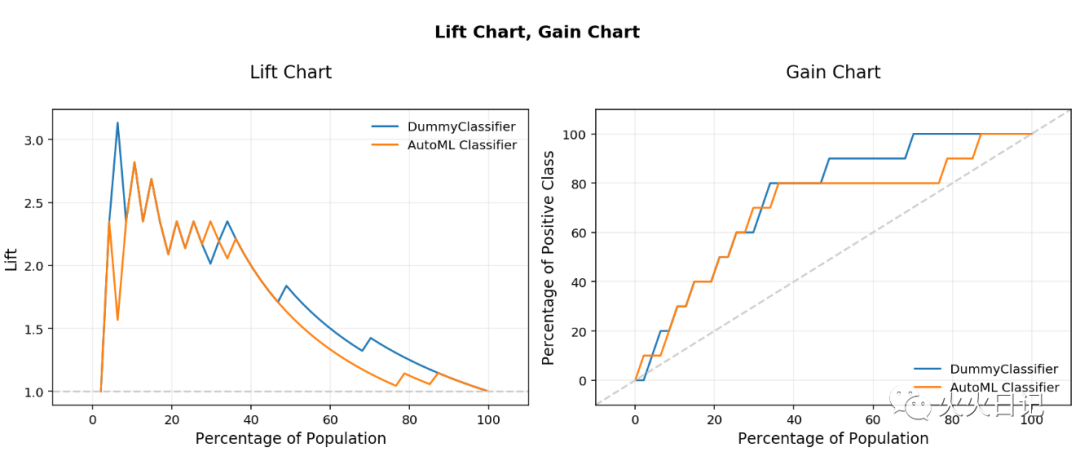
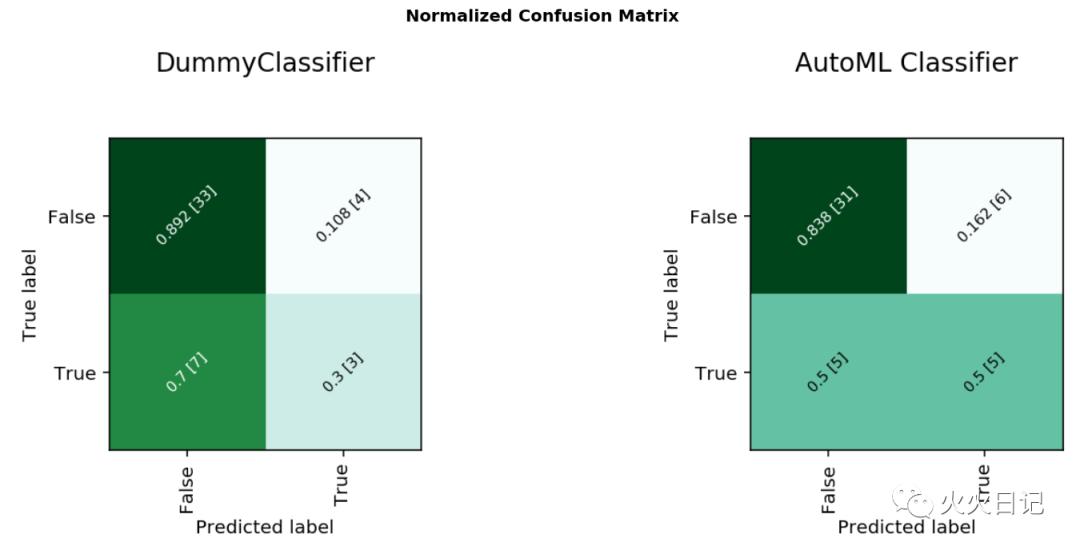
Explainability: 对模型预测的依据的解释和理解 Interpretability: 能够理解模型解释结果的人的水准 Global Explanations: 对模型本身的理解 local Explanations: 对特定数据集预测结果的解释 Model-Agnostic Explanations: 对模型训练过程以及变量的选择过程理解为黑盒子,不进行解释
from ads.explanations.explainer import ADSExplainerfrom ads.explanations.mlx_global_explainer import MLXGlobalExplainer复制
olabs_explainer = ADSExplainer(test, olabs_model)global_explainer = olabs_explainer.global_explanation(provider=MLXGlobalExplainer())复制
global_explainer.feature_importance_summary()复制



feature_importance = global_explainer.compute_feature_importance()复制
feature_importance.get_global_explanation()复制

文章转载自火火日记,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
2025年4月中国数据库流行度排行榜:OB高分复登顶,崖山稳驭撼十强
墨天轮编辑部
1856次阅读
2025-04-09 15:33:27
2025年3月国产数据库大事记
墨天轮编辑部
866次阅读
2025-04-03 15:21:16
2025年3月国产数据库中标情况一览:TDSQL大单622万、GaussDB大单581万……
通讯员
601次阅读
2025-04-10 15:35:48
征文大赛 |「码」上数据库—— KWDB 2025 创作者计划启动
KaiwuDB
494次阅读
2025-04-01 20:42:12
数据库,没有关税却有壁垒
多明戈教你玩狼人杀
485次阅读
2025-04-11 09:38:42
国产数据库需要扩大场景覆盖面才能在竞争中更有优势
白鳝的洞穴
462次阅读
2025-04-14 09:40:20
最近我为什么不写评论国产数据库的文章了
白鳝的洞穴
403次阅读
2025-04-07 09:44:54
天津市政府数据库框采结果公布!
通讯员
359次阅读
2025-04-10 12:32:35
【活动】分享你的压箱底干货文档,三篇解锁进阶奖励!
墨天轮编辑部
352次阅读
2025-04-17 17:02:24
优炫数据库成功入围新疆维吾尔自治区行政事业单位数据库2025年框架协议采购!
优炫软件
335次阅读
2025-04-18 10:01:22
