





作者介绍
司马辽太杰,目前就职于一家国有企业,主要负责数据库连续性保障、性能优化、架构选型和设计。10余年数据库架构和管理经验,专注于数据库运维、架构和行业发展,擅长常见关系型、NoSQL、MPP 等类型数据库性能优化、架构设计和故障排查。杭州乡下桐庐人,业余热爱历史、足球,偶尔读点闲书。欢迎关注个人公众号“程序猿读历史”,有需要也可以在公众号上加好友。
数据库有三大"神器",分别是事务、SQL、存储引擎。事务确保数据库具有ACID能力;SQL提供了强大的数据管理和操作能力;而存储引擎负责数据的存储和检索,存储引擎中的数据不同存储组织方式决定了其读写效率,我们把数据不同的存储组织方式称为——数据结构(data structure)。
本文将重点介绍LSM-tree 数据结构实现原理、数据读写方式、合并等特性,以及部分以LSM-tree 为数据结构的数据库介绍。由于个人能力有限,有不当之处,请各位不吝赐教。

谈到数据库存储引擎的数据结构,B-tree(Balanced-tree,平衡树) 是绕不过去的话题,MySQL InnoDB、SQL Server、MongoDB WiredTiger 等数据库都能看到它的身影。
早在1970年,Rudolf Bayer 教授在“Organization and Maintenance of Large Ordered Indices”一文中提出了B-tree 数据结构,因其具备自平衡、有效地减少了磁盘I/O、可控的树高度、允许较好的并发控制等特点,提出后迅速流行,广泛应用于数据库和文件系统中,。此后,又演化出B+tree、B*tree、SB-tree 等多个变种。
B树是将数据按照一定的顺序存储在树节点中,每个节点包含一定数量的关键字(key)和指针(pointer)。key 按照从小到大的顺序排列,pointer 指向包含相应关键字的子节点,这保证树的高度较低,在查询时能够减少磁盘IO,快速定位到目标数据,如下图所示。
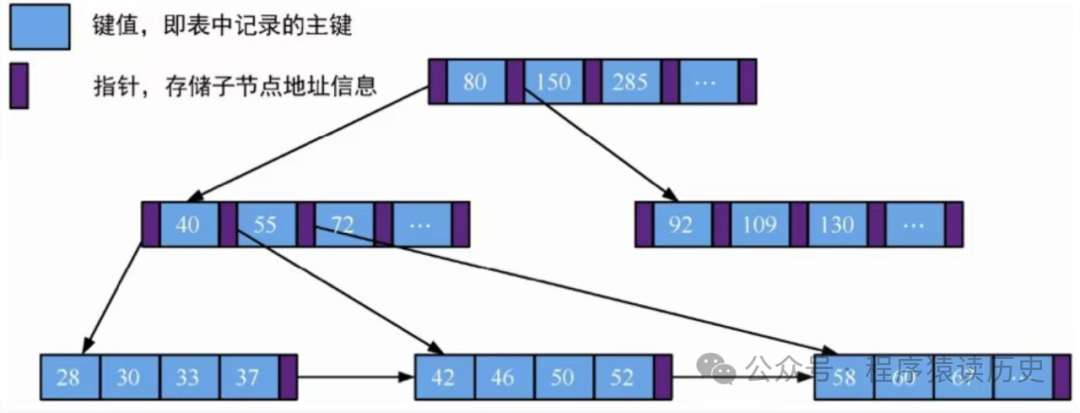
B+tree 架构图,来自《云原生数据库:原理与实战》
B树虽然有非常多的优点,但在一些场景也存在一些挑战。比如节点进行分裂操作时,内存中会拆成两个新的页表,存储到磁盘上很可能就是不连续的;在大量写入(增删改)时,除了会产生写放大外,还因其需要循环利用磁盘快,也会造成不连续问题;B树节点通常包含大量的键和指针,这可能导致存储空间的浪费,尤其是在键值较小的情况下。
针对上面这些问题,进入本文的主角LSM-tree 数据结构。希望读完这篇小文,上面这些问题各位读者大大都有答案了。
LSM全称 Log-Structured Merge Tree(日志结构合并树),由 Patrick O'Neil 教授在1996年 “The Log-Structured Merge-Tree ”一文中首次提出。LSM--tree 具备低延迟、高吞吐的特性,其核心理论基础是硬盘的顺序写要比随机写速度快很多。另外,LSM-tee 结构的数据写入磁盘是以仅追加的形式,这使得其有更高的数据密度,避免了额外的碎片产生。LSM-tree 为数据结构的数据库产品,国外有Hbase、LevelDB、RocksDB、Cassandra、Yugabyte(前两年的当红炸子鸡),国内有 TiDB、OceanBase、阿里云 RDS X-Engine等。
LSM-tree 主要由三部分组成,分别是:Memtable(Memory Mutable Table,内存可变表)、SSTable(Sorted String Table,有序字符串表)和WAL(Write-Ahead Log,预写日志,同下图中Commit Log)。当数据写入LSM中,会先写到Memtable,同时也会写入WAL中,用于确保数据的持久性(WAL也是顺序写入磁盘)。Memtable在达到一定大小后,会先转变为不可变内存表(Immemtable),同时将数据刷到磁盘,这个过程称为“刷新(flush)”。
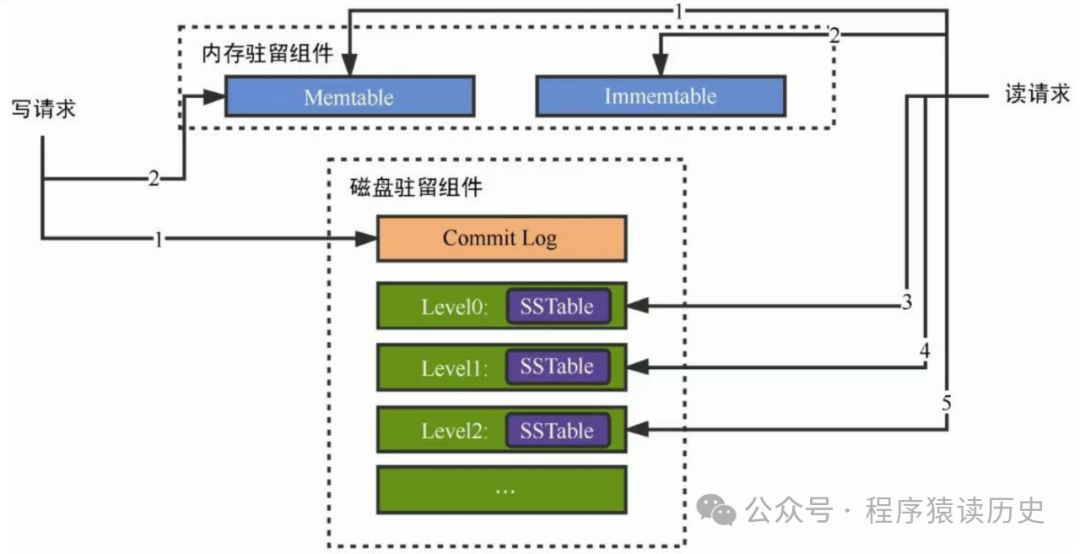
LSM-tree 架构图,来自《云原生数据库:原理与实战》
了解MySQL的同学,对这个刷新操作不会陌生,MySQL中也有类似的操作。MySQL InnoDB 引擎将内存中被修改的数据页(这类页称为脏页,dirty page)写入到磁盘上的过程,成为“刷脏(flushing dirty pages)”。当InnoDB的Redo Log 空间不足、内存不足、正常关闭等情况时,MySQL 都会触发刷脏,从而确保数据的持久性和一致性。
从Immemtable 刷到磁盘的数据会先进入 Level 0 层,并生成相应的SStable,当Level 0 层达到某个阈值后,Level 0 会合并到 Level 1,并以此方式逐层向下合并。SStable是有 Immemtable 刷到磁盘数据记录所构建,它是不可变的,仅用于读取合并和删除操作。
一般来说,数据更新写入有两种策略,即本地更新(in-place update)
、异地更新(out-of-place update)
。
B-Tree 是本地更新(in-place)
,即更新数据时直接修改原记录。比如把 <k1,v1> 改成 <k1,v4>,是在原来位置把v1直接改为v4,这样查询 k1 的值会直接返回 v4,这种方式具有很高的查询效率。由于更新没有开辟新的空间,因此具有很高的空间利用率,但代价是写放大,每一次写要先找到那个 k1的位置,再更新其v1的值,这会出现一次随机 I/O,就会导致写性能变慢。
LSM-Tree 是异地更新(out-of-place update)
,即更新数据时不直接修改原记录。比如把 <k1,v1> 改成 <k1,v4>,是用<k1,v4> 另外存储在新的空间,并给结合 version 标志为 k1 最新的值。这样写 k1 时,就不会产生随机 I/O 要事先找到 k1再更新,而是直接利用顺序 I/O 将新记录追加加上去。这相比于本地更新(in-place updates)
具有更好的读效率。同时,由于没有覆盖旧记录,也提高了回滚效率。但代价是具有读放大与空间放大。
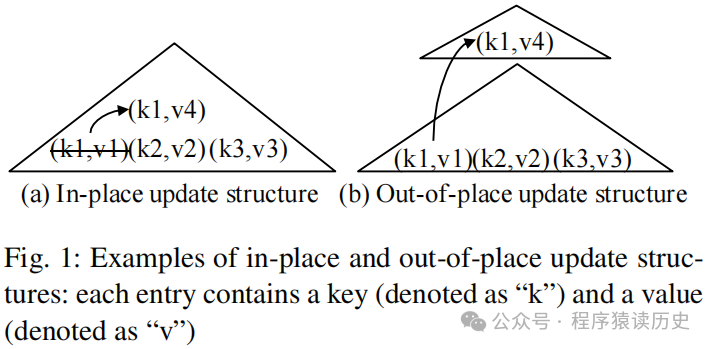
图来自《LSM-based Storage Techniques: A Survey》
LSM-tree 查找一条数据的访问顺序依次是:Memtable、Immemtable、SSTable Level 0 ---> Level N,这样保证了只要找到这条数据,它一定是最新的数据,就可以立即返回给应用。根据局部性原理,这样的查找方式在时间、空间上是比较高效的。当然,LSM-tree 存在一定的读放大是不可避免的。
2016 年Manos Athanassoulis 等人发表了“Designing Access Methods: The RUM Conjecture”一文(该文同时被 SIGMOD 和 EDBT 收录),提出了著名的RUM猜想。即对任何数据结构来说,只能同时优化 Read Overhead(读放大)、Update Overhead(写放大) 和 Memory or Storage Overhead(空间放大) 三项中的两项,同时需要牺牲另一项作为代价。
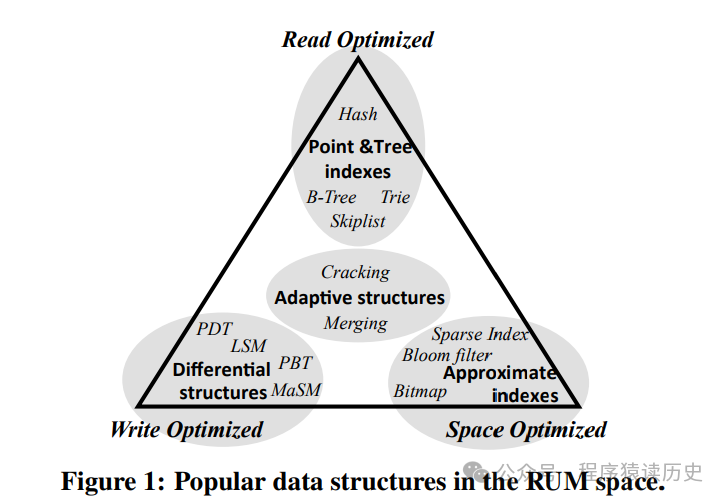
图来自《Designing Access Methods: The RUM Conjecture 》
针对这一现状,LSM-tree 对数据的查询也有一些优化,比如布隆过滤器(Bloom Filter)。对于布隆过滤器小编了解并不多,它是用于判断一个SStable中是否包含特定key,底层是一个位图结构,用于表示一个集合,以此来判断一个元素是否属于这个集合。这样通过布隆多滤器大大减少查询数据时的磁盘IO操作,从而提高查询数据效率。
随着时间的推移,写入规模的增长,磁盘上会积累大量的SSTable文件,这些文件可能会覆盖相同的键。为了优化存储空间和查询性能,LSM-tree 会定期执行合并操作,将多个SSTable文件合并(Compaction)成更少、更大的SSTable文件。合并过程会删除过时的数据(如已被删除的键)并合并重复的键。这类合并主要由以下图Tiered Compaction和Leveled Compaction两种方式。
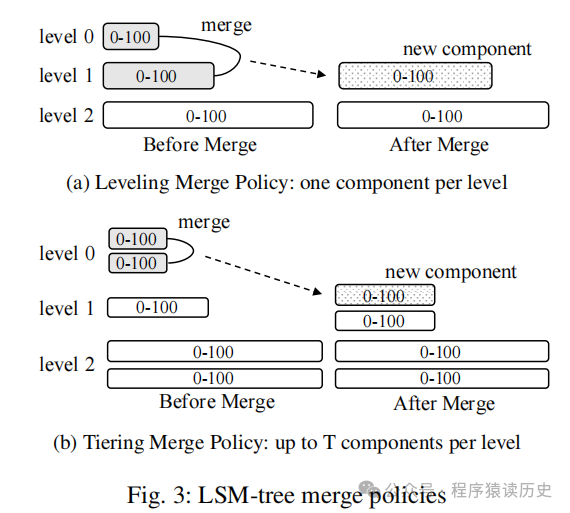
图来自《LSM-based Storage Techniques: A Survey》
Tiered Compaction
Tiered Compaction 方式允许每层的SStable文件最大数是一样的阈值,随着Immemtable 不断构建出SStable,当一层的SStable 梳理达到阈值时,就把该层的所有SStable 合并一个大的新SStable,并放到下一层。
这种方式的优缺点都很明显,有点是实现相对简单,缺点是空间放大问题更严重了,且层级越高SStable越大,读放大问题就越严重。
Leveled Compaction
Leveled Compaction 方式每层的SStable大小固定,且每层的SStable 最大数量为其第一层的N倍。如当Level 0层的SSTable文件大小超过限制时,会将这些文件与Level 1层的所有SSTable文件进行合并,合并后的文件会根据key的范围分配到相应的层级中。合并可能会触发下一层的合并操作,即Level 1层的数据规模超过阈值后,可能会触发Level 1到Level 2的合并,如此往复,直到数据被合并到更高层级
这种通过分层的组织数据,优化了读取性能,同时在空间放大和写放大之间取得了平衡,提供较好的读取性能和合理的存储空间利用率,特别适用于写入密集型的应用场景。
前面我们简单介绍了,LSM-tree的基本概念以及架构,并对数据写入、查询、合并的处理过程以及相关处理方案做了优劣分析。下面我们将简单介绍4款以LSM-tree 数据结构的数据库产品,分别是Meta的RocksDB、Google的Habse,以及国内的TiDB和OceanBase。
RocksDB
2012年,Meta(Facebook母公司)推出了一个高性能、可扩展的嵌入式键值存储数据库,也就是RocksDB。其存储引擎采用了LSM-tree 数据结构,大量的优化了写入密集型的应用场景。
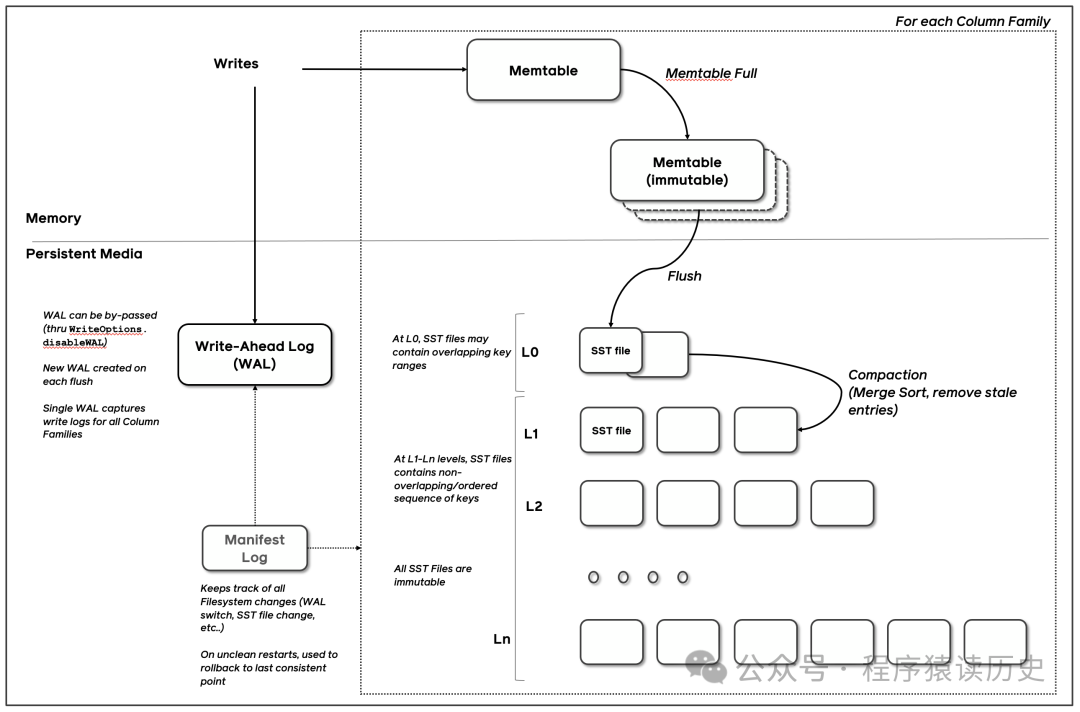 图来自RocksDB Document
图来自RocksDB Document
RocksDB支持多种存储介质,包括SSD和HDD,并提供了丰富的配置选项以适应不同的工作负载。它具备高吞吐量和低延迟的特点,适合于需要处理大规模数据的应用,如实时分析、运营智能和机器学习。RocksDB还支持列族(Column Family)、压缩、缓存和WAL(Write-Ahead Logging),以进一步提高性能和可靠性。
图来自 RocksDB Document
另外一个小插曲,RocksDB 虽然是Meta公司推出,但Meta毫不避讳的承认它是站在Google开源的Leveldb、Apache Hbase 巨人肩膀上演变来的。对比国内公司,大多害怕自家产品被说成是基于某某而来,总是强调自己是纯自研,甚至发明出“根自研”等词语。希望有朝一日,国产数据库们能自信的说出:我们的产品是基于/借鉴某某数据库而来。
Hbase
Hbase 是由 Apache 软件基金会推出的,用于需要处理大规模数据集的数据库产品,一开始是作为Apache Hadoop 项目的一部分而开发。
根据相关介绍,Hbase 最初设计思想来自于Google 的《Bigtable: A Distributed Storage System for Structured Data》一文,而LSM-tree 是其核心存储结构,很好的完成了Hadoop体系中写多读少的业务场景支撑,极大的优化了写入性能并提高了数据处理的效率。
OceanBase
OceanBase (以下简称OB)是由阿里巴巴和蚂蚁金服自主研发的金融级分布式关系数据库,具有数据强一致、高可用、高性能、在线扩展、高度兼容 SQL 标准和主流关系数据库、低成本等特点。根据相关报道,在阿里经济体内,OB除支持蚂蚁金服、网商银行等核心交易系统外,还支撑了淘宝收藏夹、阿里妈妈广告等业务。
OB 的存储引擎基于 LSM-Tree 架构,数据存储 SSTable 和 MemTable 中,其中 SSTable 是只读的,具有不可修改性,存储于磁盘;MemTable 支持读写,存储于内存。数据写入时,先写入 MemTable,等到 MemTable 达到一定大小时转储到磁盘成为 SSTable。数据查询时,需要分别对 SSTable 和 MemTable 进行查询,并将查询结果进行归并,返回给 SQL 层归并后的查询结果。
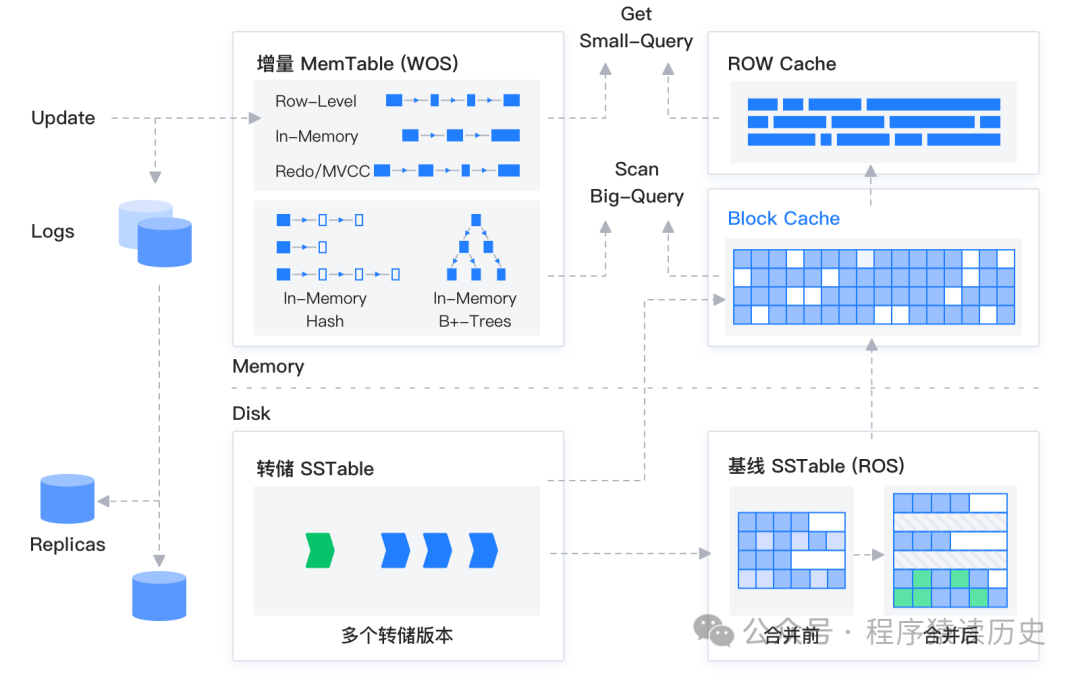 图片来自OB 文档
图片来自OB 文档
TiDB
TiDB 是 PingCAP 公司研发的分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生、兼容 MySQL 协议和 MySQL 生态等重要特性。下图是其架构图。
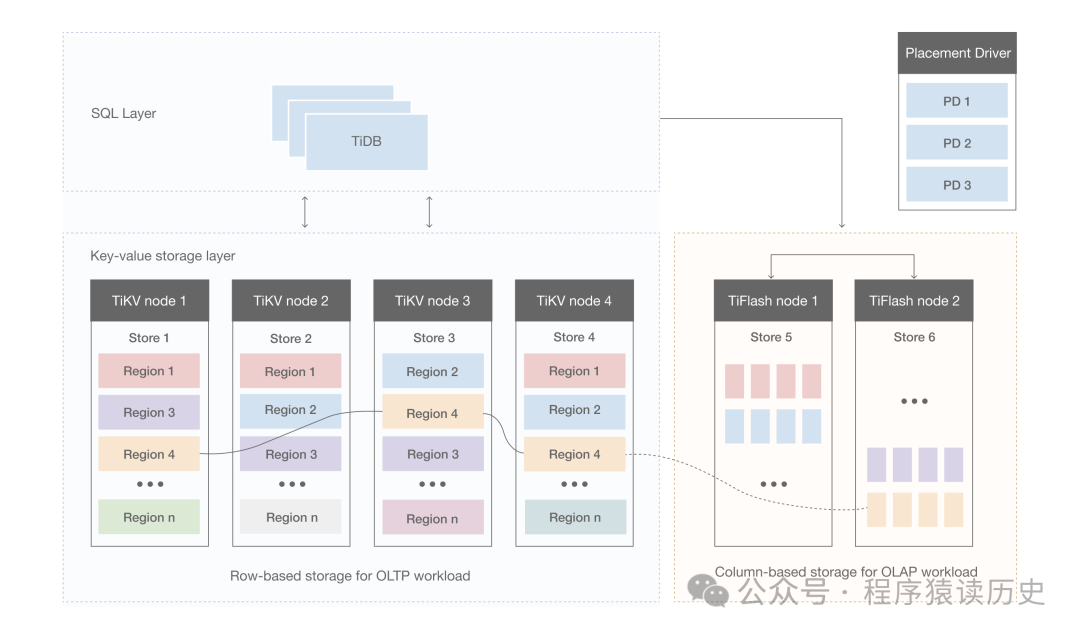
图片来自TiDB Document
根据架构图所知,其主要有TiDB Server、PD (Placement Driver) Server、TiKV Server、TiFlash 四部分组成。
TiDB Server 对外提供 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,生成分布式执行计划,本身是无状态的,也不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV。
PD Server,负责存储、管理集群的元数据信息,包括为每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,为分布式事务分配事务 ID。
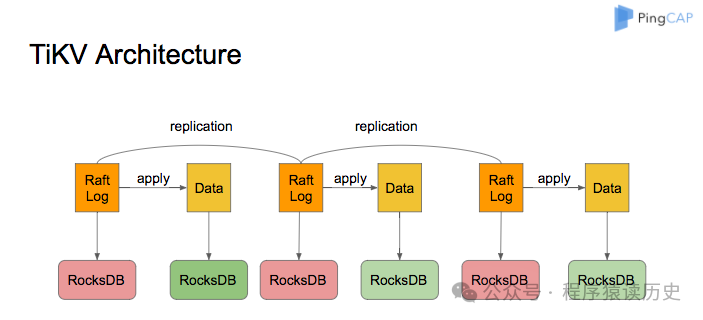 图片来自TiDB Document
图片来自TiDB Document
TiKV Server 负责存储数据,它 是一个分布式的提供事务的 Key-Value 存储引擎。根据TiDB文件介绍,TiKV 没有选择直接向磁盘上写数据,而是把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责。前面介绍了RocksDB是Meta推出的一款以LSM-tree 结构的开源数据库。
TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
LSM-tree 数据结构在处理海量规模、高并发写入的业务场景有着优异表现,为现代数据库管理系统提供了强大的支持。在此理论基础上诞生了一批优秀的数据库产品,例如Hbase、LevelDB、RocksDB、Cassandra、OceanBase等,这些产品有效的支撑了过去20多年全球互联网蓬勃发展。
随着新型硬件、架构的发展和变化,LSM-tree 数据结构的研究也在不断推进。例如多核CPU、NVMe SSD等高性能计算、存储介质,以及云原生、分布式文件系统等架构,均可以显著提高 LSM-tree的读写性能。
知其然,更知其所以然
,深入了解其工作原理,有助于我们更好的理解和使用数据库,更有效的支撑企业业务发展。另外,LSM-tree 数据结构的相关思想,也可以在实际的工作中借鉴和学习。
参考
《Organization and Maintenance of Large Ordered Indices》 Rudolf Bayer, et al.
《云原生数据库:原理与实战》 李飞飞等
《The Log-Structured Merge-Tree》 Patrick O'Neil, et al.
《LSM-based Storage Techniques: A Survey》 Chen Luo, et al.
《Designing Access Methods: The RUM Conjecture》 Manos Athanassoulis, et al.
《Bigtable: A Distributed Storage System for Structured Data》 Fay Chang, et al.
OceanBase Documents
Hbase Documents
RocksDB Documents
TiDB Documents

01
企业数据库工作1:数据库选型,除了TPS、QPS还要关注什么
02
企业数据库工作2:团队培养,如何高效阅读数据库文档
03
企业数据库工作3:数据库连续性,我们该知道什么
04
企业数据库工作4:连续性,我们该怎么做

END
