




本期将分享近期全球知识图谱相关
行业动态、近期会议、论文推荐
知识图谱+实验室信息管理
2025年3月10日,Semaphore Solutions宣布扩展其Labbit实验室信息学平台,旨在通过AI就绪数据和知识图谱技术推动实验室创新。Labbit基于知识图谱数据库,能够捕捉数据间的复杂关系,支持高级分析和AI集成。平台提供无代码工作流配置和预置模板,帮助实验室快速适应科学和监管变化,减少对IT支持的依赖。这一扩展愿景使Labbit成为智能实验室的核心基础,助力实验室加速科学发现和运营效率,推动下一代智能实验室自动化发展。
https://sourl.cn/bfx3ce

ReasonGraph
来自剑桥大学和莫纳什大学的研究人员提出了 ReasonGraph,这是一个基于 Web 的平台,用于可视化和分析 LLM 推理过程。它支持顺序和基于树的推理方法,同时与主要的 LLM 提供商和 50 多个先进的模型无缝集成。ReasonGraph 将直观的 UI 与元推理方法选择、可配置的可视化参数和模块化框架相结合,促进高效扩展。通过提供统一的可视化框架,ReasonGraph 有效减轻了分析复杂推理路径时的认知负载,提高了逻辑过程中的错误检测能力,并能够更有效地开发基于 LLM 的应用程序。
https://sourl.cn/ADFLHx

第 18 届服务科学国际会议
CCF 服务科学国际会议 (CCF ICSS) 是由 IBM 发起,中国服务学咨询与指导委员会指导的年度学术活动,也是中国服务科学界的顶级活动之一。ICSS 具有学术、工业和跨学科主题的独特组合,并为研究成果和实践经验的展示和交流以及服务学的教育发展提供了一个平台。ICSS 还旨在弥合研究人员的观点和从业者的需求。

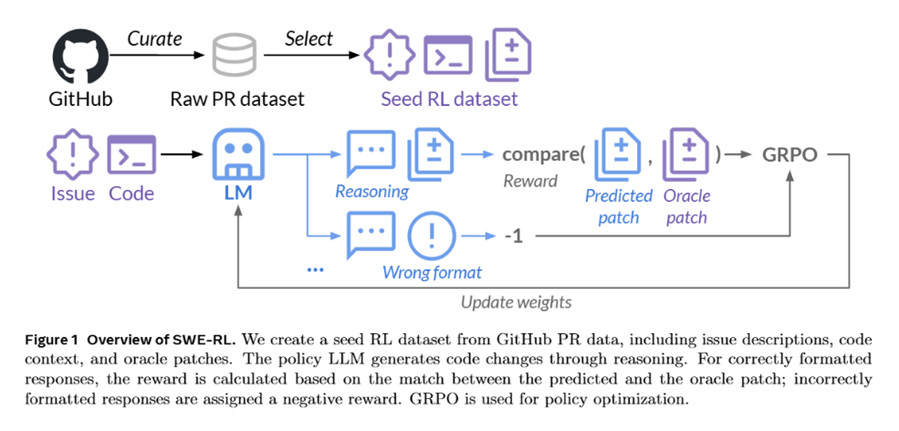
本周推荐的是arxiv 2025.2上的论文:SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution,该文提出了 SWE-RL,这是第一个将强化学习应用于大规模语言模型的软件工程推理方法。作者来自 Meta 的 FAIR 部门和GenAI 部门、伊利诺伊大学香槟分校和卡内基梅隆大学。

近期的DeepSeek-R1 发布展示了强化学习(RL)在增强大规模语言模型(LLMs)推理能力方面的巨大潜力。虽然 DeepSeek-R1 和其他后续工作主要集中在将 RL 应用于竞争编程和数学问题,但该文提出了 SWE-RL,这是第一个针对现实世界软件工程扩展基于 RL 的 LLM 推理的方法。SWE-RL通过利用轻量级基于规则的奖励(例如,真实解决方案与 LLM 生成的解决方案之间的相似度分数),使 LLM 能够通过学习广泛的开源软件演化数据——包括软件的整个生命周期记录、代码快照、代码变更以及问题和拉取请求等事件——来自主恢复开发者的推理过程和解决方案。基于 Llama 3 进行训练,最终得到的推理模型 Llama3-SWE-RL-70B 在 SWE-bench Verified 上达到了 41.0% 的解决率——这是一个经过人工验证的真实世界 GitHub 问题集。据作者所知,这是目前中型(<100B)LLM 取得的最佳性能,甚至与领先的专有 LLM(如 GPT-4o)相当。令人惊讶的是,尽管 Llama3-SWE-RL 仅在软件演化数据上进行 RL 训练,但它仍然展现出广泛的推理能力。例如,它在五个跨领域任务上取得了更好的结果,分别是函数编码、库使用、代码推理、数学和一般语言理解,而监督微调的基线模型在这些任务上平均表现有所下降。总体而言,SWE-RL 为通过强化学习提升 LLM 推理能力开辟了新的方向,尤其是在海量软件工程数据的基础上。
该文提出的SWE-RL如下图所示:
该文链接:
https://www.alphaxiv.org/abs/2502.18449
源代码:
https://github.com/facebookresearch
感兴趣的读者可以关注。
更多链接
内容:袁知秋、程湘婷、王图图

诚邀您加入我们的gStore社区,我们将在群内解决使用问题,分享最新成果~
请在微信公众号图谱学苑发送“社区”入群~

微信社区群:请回复“社区”获取




