




昨天看到达摩院一个PR,前缀很长的首款
基于DRAM
的3D键合堆叠
存算一体芯片. 性能提升了10倍以上, 非常不错的工作。作为一个兼职互联网PR翻译官,和优秀的技术扶贫工程师,下面我们来谈谈存内计算的问题, 然后加入通信的问题,因为这也是NetDAM项目的初衷:可编程存内计算及通算一体化.
一些已有的工作
之所以加前缀,当然是有一些前人已有的工作咯.首先我们来看3D键合堆叠
(Hybrid Bonding),在今年前些时候的HotChip33上台积电发布了SoIC的3D封装工艺,相对于HBM的封装的确在功耗上和带宽上有巨大的进步
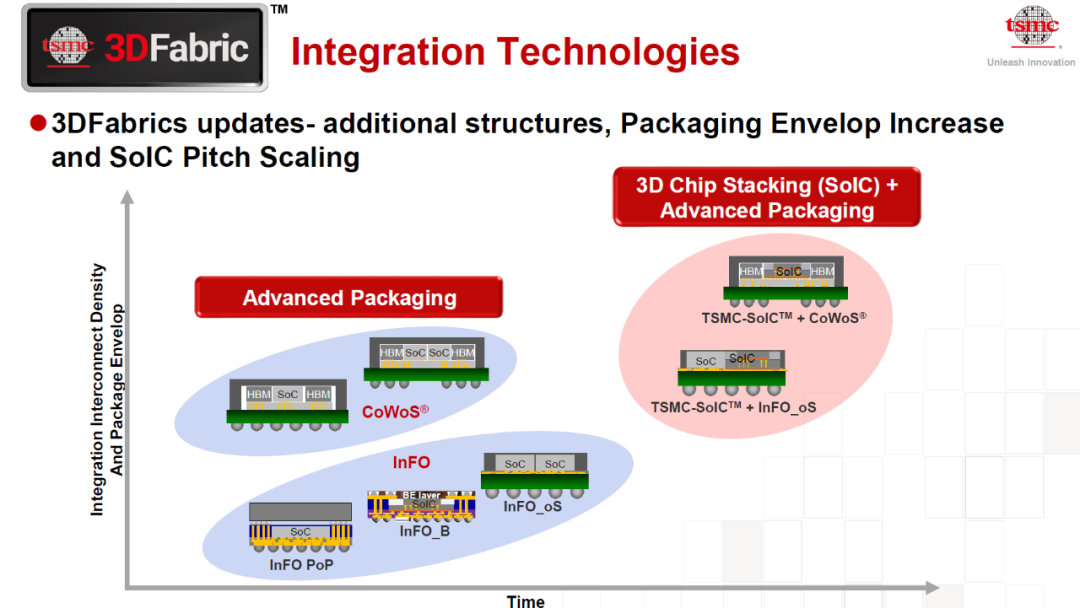
下面这张图更能看清楚Hybrid Bonding:

另一个是关于存算一体芯片,也是在ISSCC21上公布的Samsung FIM(Function In Memory),后来改名叫Processing in Memory技术,它是把一些计算核做成HBM封装的格式,然后和HBM内存堆叠,然后再接到基板上.

当然性能也提升了很多倍,最好的也有11倍

这也是渣在设计NetDAM的时候会直接在HBM旁挂载ALU的原因,存算一体的思路是一样的.只不过是我们还考虑到和芯片间通信的问题.
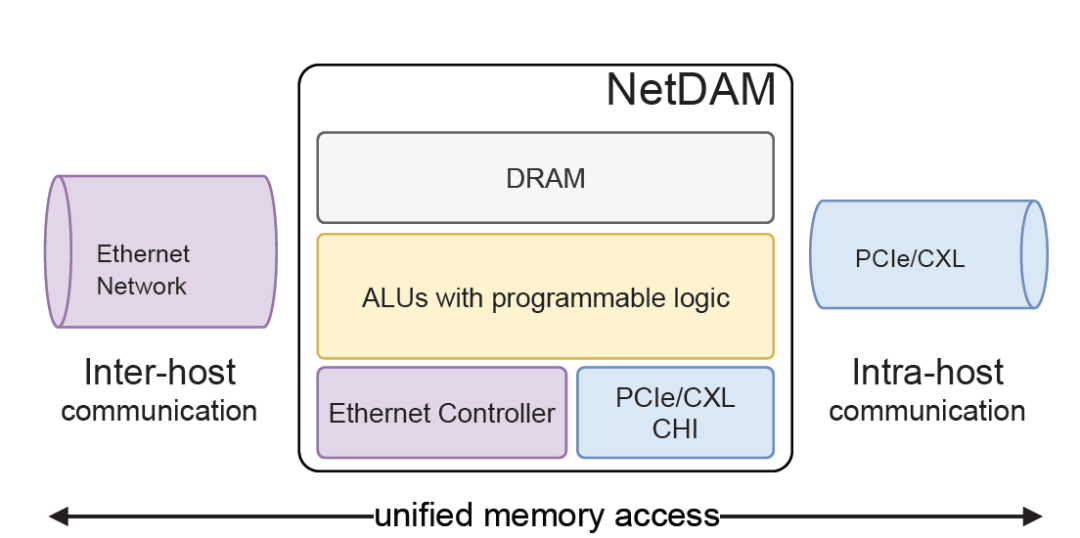
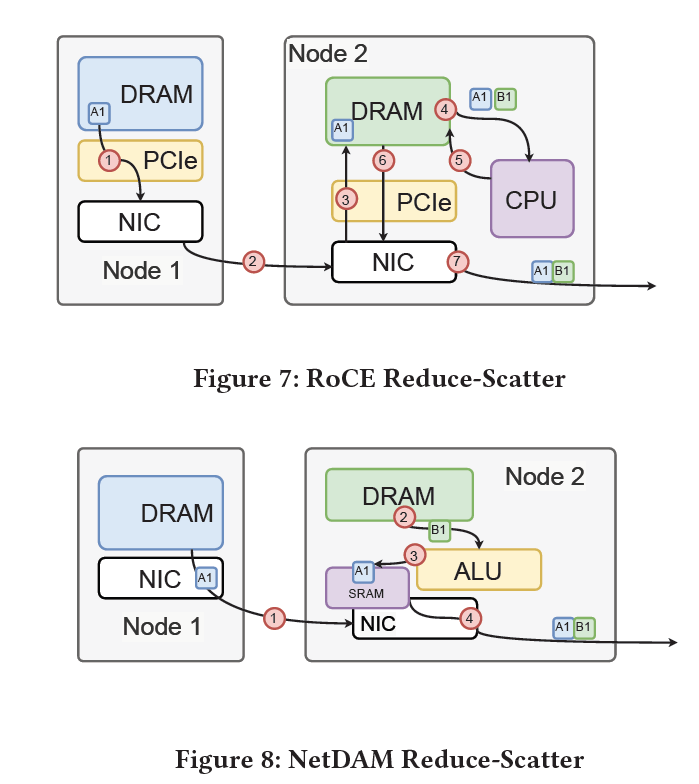
例如我们在现有的MPI-AllReduce测试中比RoCEv2、RDMA的技术快了数倍.
当然渣这种穷屌丝看到阿里这么玩也只能眼馋啊,毕竟经济实力不允许呀,技术扶贫资金不够啊,没法像达摩院这样花钱去流片咯....所以只能FPGA上搞点ALU+HBM研究。
但是达摩院很有可能忽视了一个问题,当你有了这样的存算一体芯片后,如何和其它芯片通信和交互?下图才是更关键的降低整个数据中心搬运的技术.
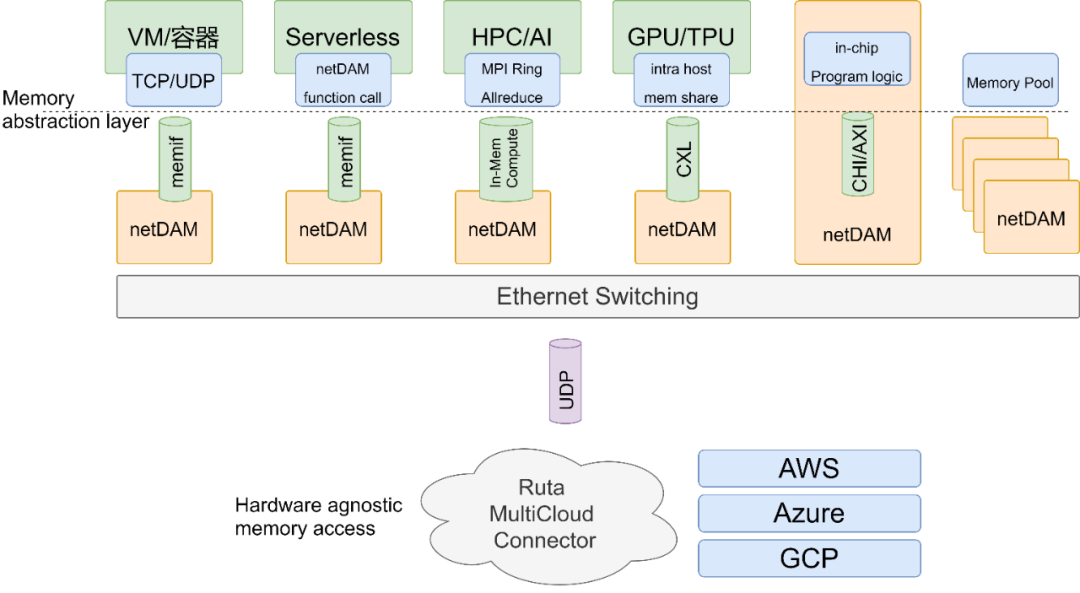
这才是突破冯诺依曼架构的关键,神龙或许看到了,但是我们NetDAM已经做出来了,这才是DPU未来的主战场.
存算一体
突破冯·诺依曼架构的性能瓶颈,本质上需要从一开始看到冯·诺依曼架构的由来,存算的分离来自于图灵机的设计,更简单的来说来自于对自然界的纸和笔的抽象,正如我前段时间写的一篇文章:
存算一体解决了部分的冯诺依曼架构的问题,但是还不能泛化到通用计算场景中,因为你会发现缺少了网络给多个芯片搭桥.因此前文提炼出来一个很朴素的概念:
网络的本质是承载数据流,内存是数据流在某个时刻的快照,而计算是基于快照信息而产生新的数据流。
如果这样的存算一体芯片交互的总线是简单的内存读写那么又构造了一个更大的冯诺依曼架构. 当然这也是一个暂时缓解之计, 数据的搬运量在芯片组内是少了很多,芯片组之间还是同样的Input-Output,
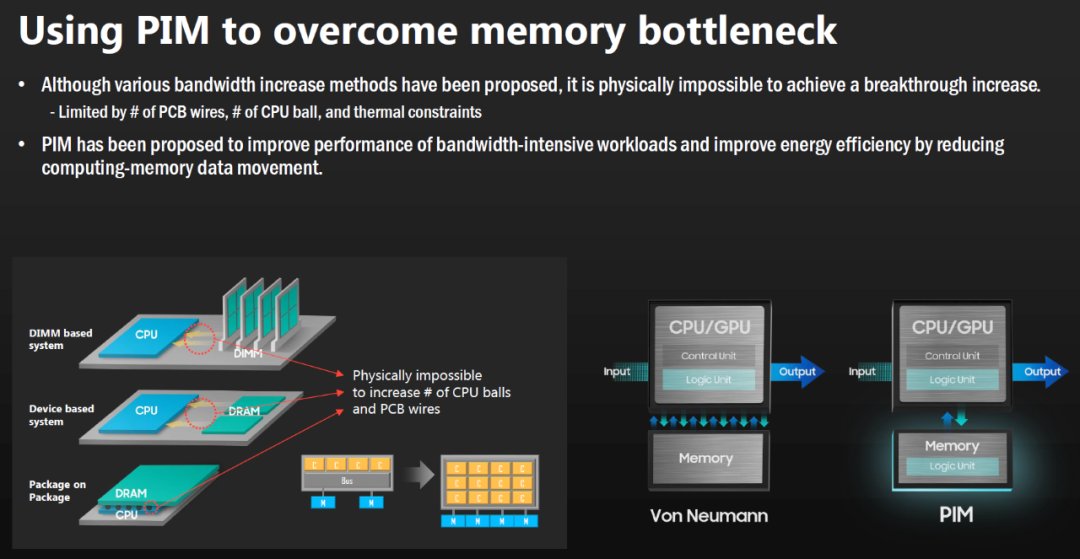
从整个数据中心而言, 照样是以处理节点为中心的。而真正的降低能耗是需要以数据为中心(Data-Centric),数据搬运的可靠传输的功耗浪费等一系列因素都需要考虑其中。所以最本质的地方是要将指令集和数据紧耦合,把指令射向数据池,而不是搬运数据到处理器.所以明白为什么NetDAM通信的是指令集和部分数据,而不是搬运数据了吧?
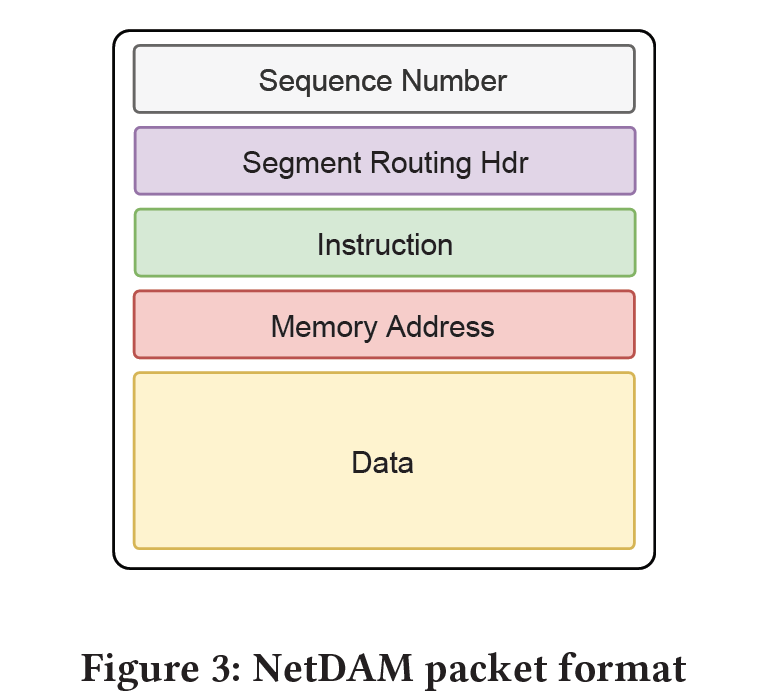
所以工业界你会看到除了In-memory Computing 还有In-Network Computing的技术,但是大多数人都是Offload的思想,例如上面的PIM就是把一些技术Offload到邻近内存或者内存内计算,而忘记了从整个体系架构上考虑。所以我说除了我们NetDAM团队现在唯一想清楚的就是Tenstorrent的Jim Keller和Xilinx的CEO Victor Peng.
说金坷垃懂是因为,他的Tenstorrent提出了Dynamic Execution的处理方法:
Networking + compute on each chip Computation directly on packets Packet routing controlled by graph compiler 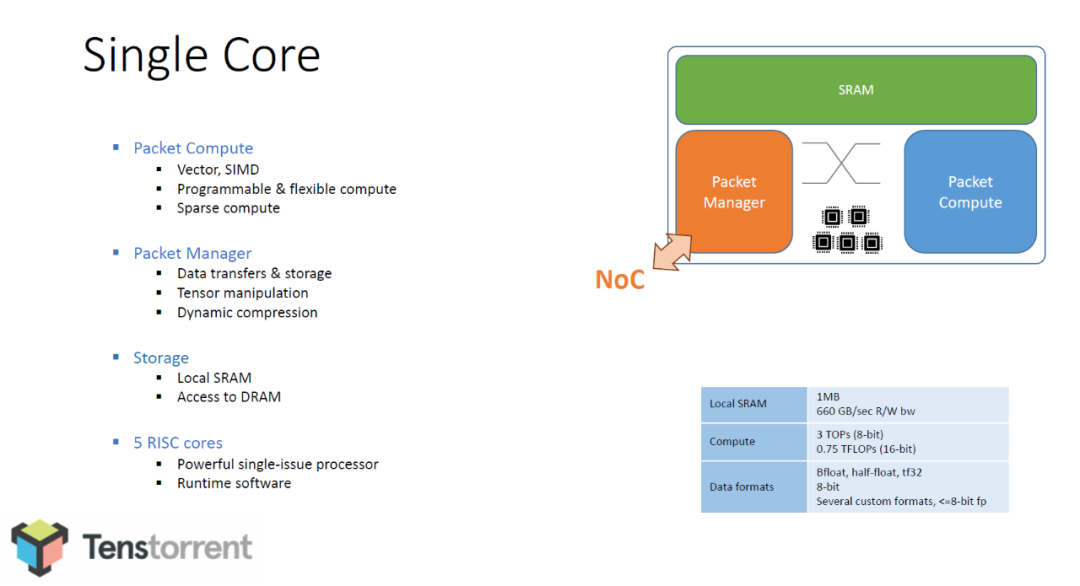
这也是NetDAM设计的思路, 既完成了存算一体(上图是存算分离,下图是存算一体,看见没有,CPU没咯~),又和通信结合,还可以根据算法压缩通信量,例如稀疏矩阵VarInt编码传输,又可以和Ruta结合做报文路由等.
而另一个看懂的是Victor peng,Offload徒增cost,而本质的做法是Dis-aggregated Computing,并使用Adaptive Network连接.

