




在日常的数据处理中,我们见到的类人员汇报线等具有层级结构的数据组成是平铺展开的:
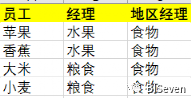
但是,有时候层级机构的数据组织方式是由两列数据构成的:上级和下级,如下:
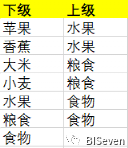
那么,如何处理图2中的数据,使其还原成图1的结果?
我们可以利用Path函数来由图2转换成图1,Path函数就是今天的主角。
我们利用一下Dax生成一个计算列:
path_ = PATH('Path'[下级], 'Path'[上级])复制
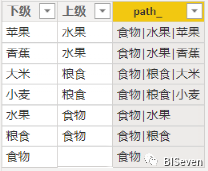
我们可以观察新列path_, 对于列"下级", path_找到了其所有的上级,并用"|"进行分割。
接下来,我们可以在通过SelecteColumns 和Pathitems 函数生成一张新表:
EVALUATET= SELECTCOLUMNS ('Path',"员工",PATHITEM ('Path'[path_],3),"经理",PATHITEM ('Path'[path_],2),"地区经理",PATHITEM ('Path'[path_],1))复制
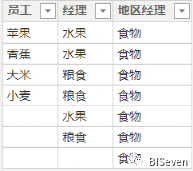
小结一下
1. Path函数比较简单,主要使用的场景是在具有层级结构的两列数据中,返回下级的所有上级,并以"|"进行分割,并按从高到低的数序进行排列。
2. 上级的内容必须全部出现在下级中,比如上述图3中的食物,虽然他是最高级,但是还是要必须出现在下级中。
其他更详细的内容,可参考以下资料:
https://www.powerbigeek.com/dax-functions-path/?f=1
https://docs.microsoft.com/en-us/dax/path-function-dax
文章转载自BISeven,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
【专家观点】罗敏:从理论到真实SQL,感受DeepSeek如何做性能优化
墨天轮编辑部
1203次阅读
2025-03-06 16:45:38
【专家有话说第五期】在不同年龄段,DBA应该怎样规划自己的职业发展?
墨天轮编辑部
1179次阅读
2025-03-13 11:40:53
2025年2月国产数据库大事记
墨天轮编辑部
904次阅读
2025-03-05 12:27:34
2025年2月国产数据库中标情况一览:GoldenDB 3500+万!达梦近千万!
通讯员
817次阅读
2025-03-06 11:40:20
2月“墨力原创作者计划”获奖名单公布
墨天轮编辑部
419次阅读
2025-03-13 14:38:19
AI的优化能力,取决于你问问题的能力!
潇湘秦
394次阅读
2025-03-11 11:18:22
优炫数据库成功应用于国家电投集团青海海南州新能源电厂!
优炫软件
332次阅读
2025-03-21 10:34:08
达梦数据与法本信息签署战略合作协议
达梦数据
272次阅读
2025-03-06 09:26:57
国产化+性能王炸!这套国产方案让 3.5T 数据 5 小时“无感搬家”
YMatrix
258次阅读
2025-03-13 09:51:26
IBM收购数据库厂商DataStax:瞄准向量和AI搜索
深度数据云
250次阅读
2025-02-28 12:04:04
