




1、前言
在气象数据的预处理阶段,经常用到工具cdo,它给我们的工作带来了很多的便利。笔者在前期学习python气象绘图的时候,每次需要处理的nc比较少,因此cdo命令行格式的操作方式也能满足业务需求,但是当需要处理的nc数据就逐步增多了,比如当有十个nc文件需要处理成《年,季节或者月度》的数据,在cdo命令行的模式下,可能要半天甚至更多时间去处理,而且还不能保证正确性,一旦有问题,排查非常不方便,需要回头把执行的命令一条一条对照,效率非常低。想到既然Python平台上都已经安装了cdo模块了,那为什么不可以直接在python平台上直接调用cdo的命令呢?思路很好,但是当我们尝试这么做的时候,我们就会发现,python提示cdo模块不存在:“No Module named ‘cdo’”
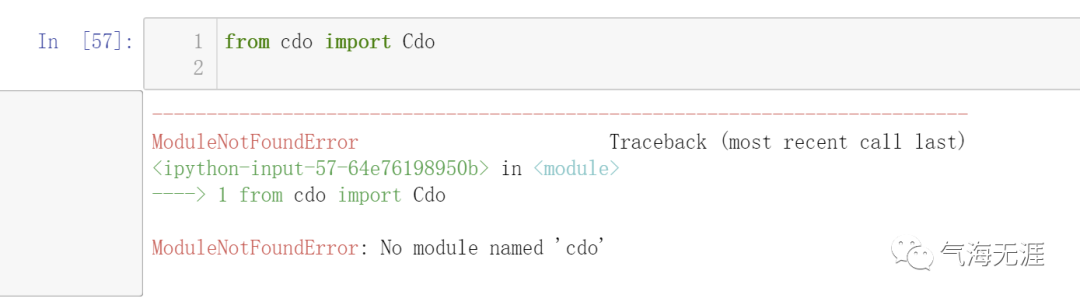
明明我们已经安装了cdo模块,为什么还提示模块不存在呢?网上查了很多资料,有说环境变量有问题的,也有说一些其他问题的,貌似都解决不了笔者遇到的问题。最后,在stack网站上找到了原因,原来在cdo和python之间,还需要一个中间件:python-cdo。我们之前在命令行中执行的cdo和python-cdo是两码事,cdo是一个软件,而python-cdo是Python中的一个库,两者的使用环境不一样。这里要重点介绍一下stack网站,这里基本上能搜索到你遇到的大部分问题,答案请大家认真阅读回帖,基本上打勾的就是了, 另外还建议多尝试。
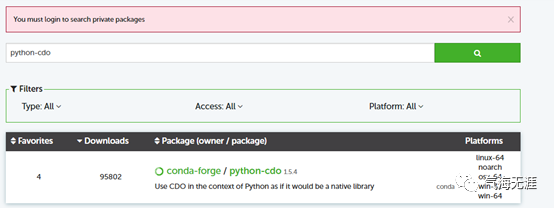
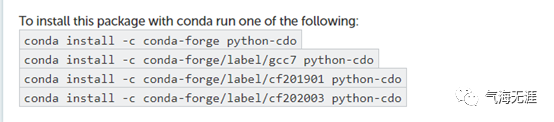
python-cdo的安装也是通过conda指定安装的, 与cdo是一样的, 但是其用途不一样。按照笔者的理解, cdo是一个第三软件, 但跟其他的python库不太一样, python无法直接使用cdo, 还需要一个桥接的python-cdo库,才能使用cdo库。其作用就是把python中的命令格式翻译成cdo能识别的命令。如果你想获得一点python-cdo的帮助文档,请回复python-cdo,我们将推送给大家。
2、数据处理案例
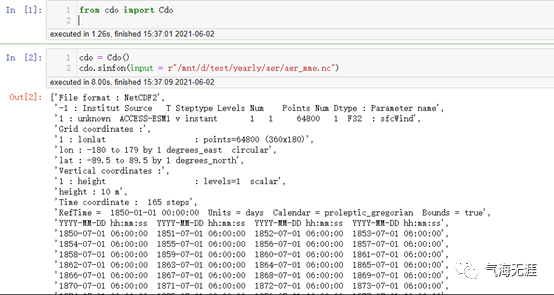
1from cdo import Cdo
2cdo = Cdo()
3cdo.sinfon(input = r"/mnt/d/test/yearly/aer/aer_mme.nc")复制
第一条:cdo.selyear(params,input = inputfileName,output = outfileName)
该命令是提取指定年份的数据,因为很多nc文件的时间跨度范围可能不一致,因此,在数据预处理阶段,需要把共同年限的数据提取处理,以便于后续处理,input后面的inputfileName是待处理的nc文件,output后面的outputfileName是处理后输出的nc文件。 比如:cdo.selyear(r“ 1990/2000”, input = inputfile, output = outputfile)。第二条:cdo.selseas(params, input = outputfile, output = outputfile)
该命令可以提取指定的季节,params可以是DJF/MAM/JJA/SON中的一个,例如:cdo.selseas('DJF', input = outputfile, output = djf_outputfile),就表示提取冬季数据。第三条:cdo.selmonth(params, input = outputfile, output = month_outputfile)
该命令可以提取指定nc文件的某个月份数据,param用月份数字表示,比如:
cdo.selmonth(‘1’, input = outputfile, output = month_outputfile),可以提取1月份的数,保存在month_outputfile文件中。
cdo.yearmean(inputfileName,outputfileName),这个命令只有两个参数。
1#cdo对所有nc数据进行处理,分别提取出年平均,和季节平均,还有月平均
2def cdo_data_process(dirpath, fromyear, toyear):
3 cdo = Cdo()
4 g = os.walk(dirpath)
5 for path,dir_list,file_list in g:
6 for file_name in file_list:
7
8 #1.取指定年度范围内的数据
9 inputfile = os.path.join(path, file_name)
10 fileName = "YEAR_" + file_name
11 outputfile = os.path.join(path, fileName)
12 cdo.selyear(fromyear + r"/" + toyear, input = inputfile, output = outputfile)
13
14 #2.对上述数据提取年平均
15 yearmean_outputfile =os.path.join(path, "MEAN_" + fileName)
16 cdo.yearmean(input = outputfile, output = yearmean_outputfile)
17
18 if debug == 1:
19 print(yearmean_outputfile)
20
21 #3.对第一步得到的数据,按季节和月份分别提取
22 djf_outputfile = os.path.join(path, "DJF_" + fileName)
23 mam_outputfile = os.path.join(path, "MAM_" + fileName)
24 jja_outputfile = os.path.join(path, "JJA_" + fileName)
25 son_outputfile = os.path.join(path, "SON_" + fileName)
26
27 cdo.selseas('DJF', input = outputfile, output = djf_outputfile)
28 cdo.selseas('MAM', input = outputfile, output = mam_outputfile)
29 cdo.selseas('JJA', input = outputfile, output = jja_outputfile)
30 cdo.selseas('SON', input = outputfile, output = son_outputfile)
31
32 if debug == 1:
33 print(djf_outputfile,mam_outputfile,jja_outputfile,son_outputfile)
34
35 for i in np.arange(1,13):
36 month_outputfile =os.path.join(path, "[" + str(i) + "]MONTH_" + fileName)
37 cdo.selmonth(str(i), input = outputfile, output = month_outputfile)
38 if debug == 1:
39 print(month_outputfile)
40
41 #4.对第三步中得到的季节数据再次求平均
42 mean_djf_outputfile = os.path.join(path, "MEAN_" + "DJF_" + fileName)
43 mean_mam_outputfile = os.path.join(path, "MEAN_" + "MAM_" + fileName)
44 mean_jja_outputfile = os.path.join(path, "MEAN_" + "JJA_" + fileName)
45 mean_son_outputfile = os.path.join(path, "MEAN_" + "SON_" + fileName)
46
47 cdo.seasmean(input = djf_outputfile, output = mean_djf_outputfile)
48 cdo.seasmean(input = mam_outputfile, output = mean_mam_outputfile)
49 cdo.seasmean(input = jja_outputfile, output = mean_jja_outputfile)
50 cdo.seasmean(input = son_outputfile, output = mean_son_outputfile)复制
1dirpath = r"/mnt/d/python-project/data_process/nc"
2cdo_data_process(dirpath, str(1975), str(2017))复制

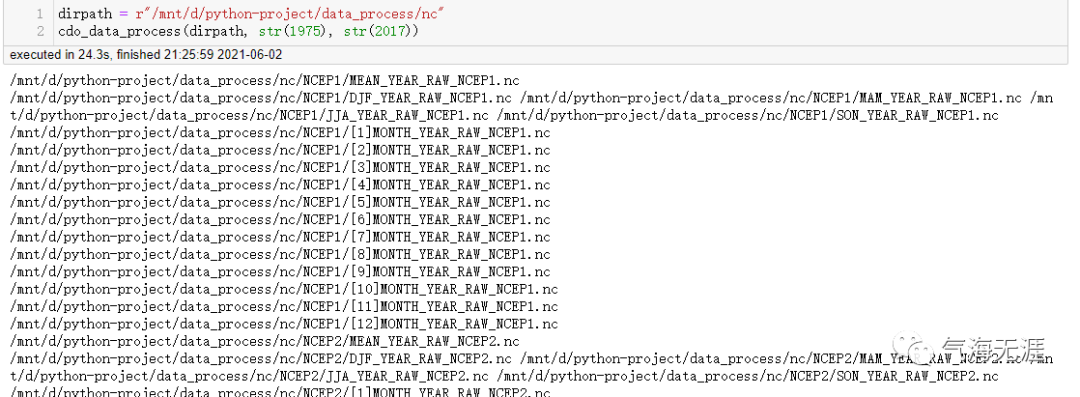
执行完上述代码以后,我们看下处理了那些文件(没有完整截图),可以看到整个流程处理完才花了不到25s,效率是不是很高?
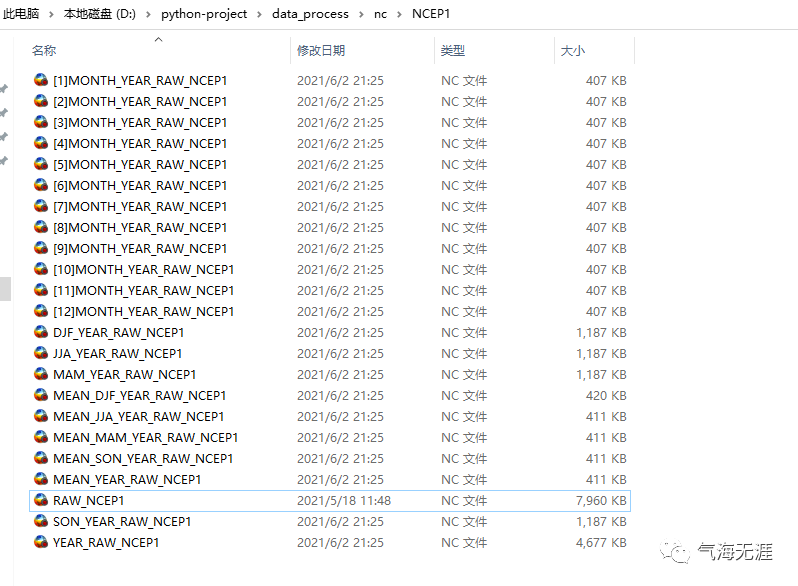
再看看NCEP1目录下的情况(NCEP2类似):
接下来解释一下代码块





3、总结

评论

 0 点赞 0 点赞 0 点赞 0 点赞
0 点赞 0 点赞 0 点赞 0 点赞