




https://www.percona.com/blog/2020/01/22/innodb-flushing-in-action-for-percona-server-for-mysql/
前言
作为MySQL InnoDB IO 调优系列的第二篇, 第一篇文章 参见Give Love to Your SSDs – Reduce innodb_io_capacity_max
!
yangyidba: 嘿嘿,妹想到吧,我是倒着翻译的,后面发布第一篇。
我们想集中介绍 Percona MySQL (8.0.x prior to 8.0.19, or 5.7.x). 的 刷盘机制。理解这些技术要点对于InnoDB 调优非常重要。本文会深入里介绍InnoDB 的工作机制。
InnoDB 后台线程 从buffer pool 刷新脏页到磁盘。脏页就是在内存中经过修改而且还没刷新到磁盘的页块儿。在buffer pool中修改而非直接刷新到磁盘会降低 磁盘的IO 负载能力 和 事务的响应时间。下面我们来了解InnoDB 的内部刷新类型。
Idle Flushing
在上一篇文章中我们已经介绍 Idle Flushing。当数据库系统没有写入操作,此时 LSN 的值不动 , InnoDB 根据 innodb_io_capacity
定义的值来刷脏页。
Dirty Pages Percentage Flushing
基于脏页百分比的刷新算法是基于 老的InnoDB 刷新算法的改进版。如果你和MySQL 打交道很久了,估计你并不会喜欢这种算法。该算法受到如下参数的限制:
innodb_io_capacity (default value of 200)
innodb_max_dirty_pages_pct (default value of 75)
innodb_max_dirty_pages_pct_lwm (default value of 0 in 5.7 and 10 above 8.0.3)复制
如果 buffer pool中的脏页比例大于 ** low water mark (lwm)** , 则 InnoDB 以与脏页的实际百分比成正比的速率刷新页面flush page ,超过Innodb_max_dirty_pages_pct
乘以 innodb_io_capacity
的值。如果实际脏页百分比高于Innodb_max_dirty_pages_pct
,则刷新率上限为innodb_io_capacity
。图
这个算法的主要问题是没有抓中重点。可能出现的情况是:由于达到最大 checkpoint age ,事务处理可能经常因刷新风暴而停滞。这是 Vadmin Tkachenko 在 2011 年写的一篇文章中的一个示例:InnoDB Flushing: a lot of memory and slow disk。
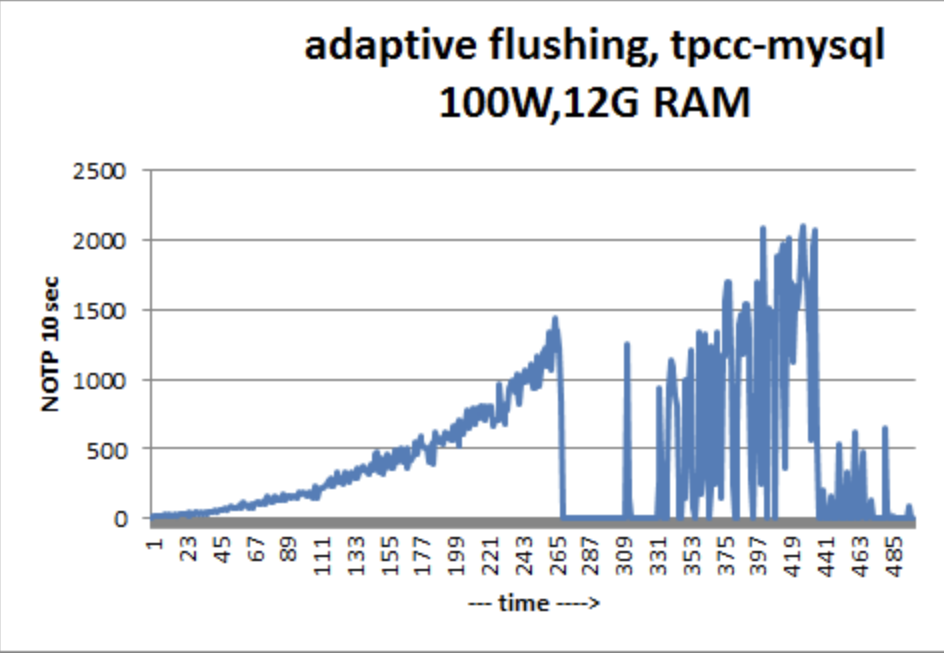
https://www.percona.com/blog/2011/03/31/innodb-flushing-a-lot-of-memory-and-slow-disk/
我们可以看到在 time = 265 时 NOTP(每秒新订单事务)急剧下降,这是因为 InnoDB 达到了最大检查点年龄并且不得不疯狂地刷新页面。这通常被称为 flush storm 。flush storm 阻塞了写操作,对数据库操作极为不利。有关flush storm的更多详细信息,请参阅InnoDB 刷新:理论和解决方案。
https://www.percona.com/blog/2011/04/04/innodb-flushing-theory-and-solutions/
Free List Flushing
为了加速读操作以及内存页初始化,InnoDB 尝试在每个缓冲池实例中始终拥有一定数量的空闲页面。如果没有足够的空闲页面,InnoDB 可能需要在加载新页面之前将脏页面刷新到磁盘。
这种行为是由另一个鲜为人知的参数控制:innodb_lru_scan_depth
。对于该参具体的含义以及名字,这是一个非常糟糕的名称。尽管如果您查看代码,该名称是有意义的,但对于普通的 DBA,名称应该是 innodb_free_pages_per_pool_target
。定期扫描每个缓冲池实例的 LRU 列表中最旧的页面(因此得名),并将页面释放到变量值。如果这些页面之一是脏的,它将在被释放之前被刷新到磁盘。
Adaptive Flushing
自适应刷新算法是对 InnoDB 的重大改进,它允许 MySQL 以更加顺滑的方式处理更重的写入负载。自适应刷新不像旧算法那样查看脏页的数量,而是着眼于重要的事情: checkpoint age。我们知道的第一个自适应算法来自于 2008 年在 Percona 工作的 Yasufumi Kinoshita。InnoDB 插件 1.0.4 集成了类似的概念,最终 Percona 删除了它的刷新算法,因为上游的做得很好。
**以下描述适用于 Percona Server for MySQL 8.0.18-**。当我们忙着写这篇文章时,Oracle 发布了 8.0.19,它对自适应刷新代码进行了重大更改。这似乎是在不久的将来发布后续帖子的好机会 ……
背景知识
让我们先回过头来学习一些基本概念。InnoDB 通常将行存储在 16KB 的页面中(innodb_block_size
的默认值)。这些页面要么在磁盘上,要么在数据文件中,要么在 InnoDB 缓冲池的内存中。InnoDB 只修改缓冲池中的页面。
缓冲池中的页面可能会被 SQL语句修改,变成脏页。在事务提交时,修改页面内容被写入重做日志--InnoDB 日志文件。写入后,增加 LSN(最后一个序列号)。脏页并不会被立即刷新到磁盘,而是会保持一段时间。延迟页面刷新是一种常见的性能提升手段。
InnoDB 刷新脏页的方式是本文的重点。
现在让我们看看 InnoDB Redo Log 的结构。
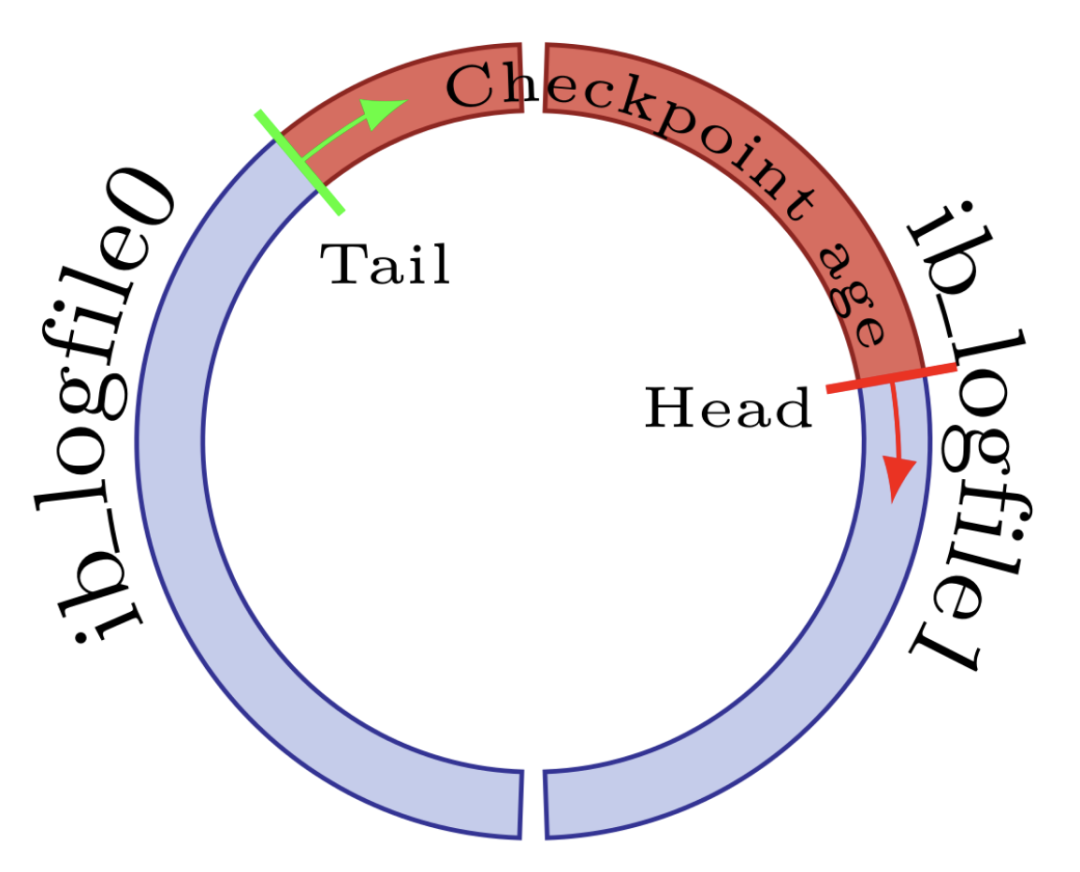
InnoDB 重做日志文件形成一个环形缓冲区
InnoDB 日志文件形成一个包含未刷新修改的环形缓冲区。上图显示了环形缓冲区的粗略表示。Head 指向 InnoDB 当前正在写入事务数据的位置。Tail 指向最旧的未刷新数据修改。Head 和 Tail 之间的距离就是 checkpoint age。checkpoint age以字节表示。日志文件的大小和数量决定了最大checkpoint age,最大checkpoint age约为日志文件总大小的 80%。
写事务正在向前移动Head,而页面刷新正在移动Tail。如果Head移动得太快并且在Tail 之前的可用空间少于 12.5% ,则事务无法再提交,直到日志文件中的一些空间被释放。InnoDB 通过高速刷新来做出反应,这个事件称为 Flush Storm。不用说,应该避免此类情况。
自适应刷新算法的工作原理
自适应冲洗算法由以下变量控制:
innodb_adaptive_flushing (default ON)
innodb_adaptive_flushing_lwm (default 10)
innodb_flush_sync (default ON)
innodb_flushing_avg_loops (default 30)
innodb_io_capacity (default value of 200)
innodb_io_capacity_max (default value of at least 2000)
innodb_cleaner_lsn_age_factor (Percona server only, default high_checkpoint)复制
该算法的目标是使刷新率(Tail 的速度)适应checkpoint age的更新(Head的速度) . 当 checkpoint age 大于 自适应刷新低水位时(默认是10%),则系统启动自适应刷新。Percona Server for MySQL 提供两种算法 Legacy 和 High Checkpoint
Legacy 算法 计算公式如下, 注意 age 因子的3/2 次方,分母为 7.5 。
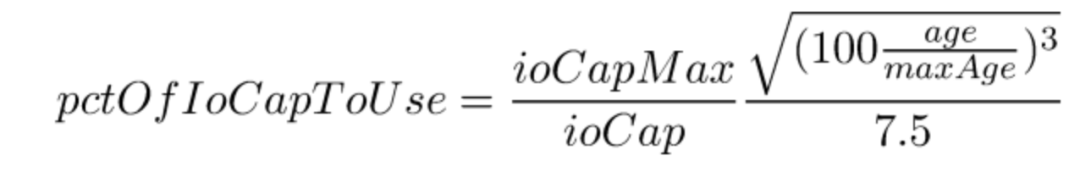
Legacy age factor
High Checkpoint 算法计算公式如下: 注意 age 因子的5/2 次方,分母为 700.5
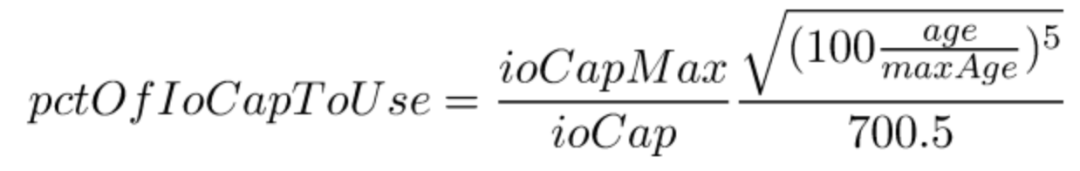
Percona High-checkpoint age factor
需要注意的是,在这两个等式中,innodb_io_capacity_max
(ioCapMax) 为分子,innodb_io_capacity
(ioCap)为分母与比率。如果我们将两个方程绘制在一起,我们有:
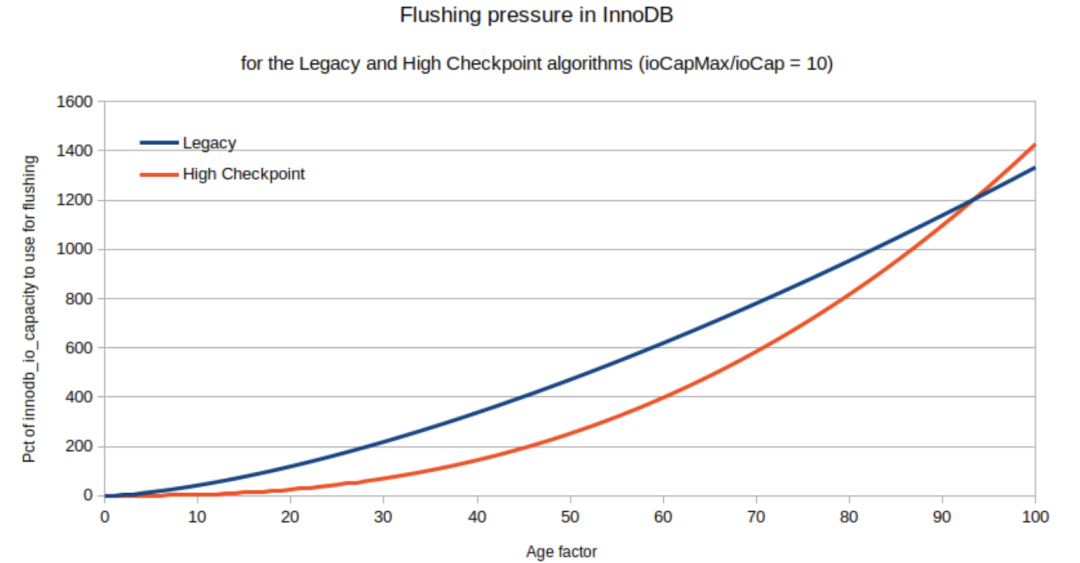
Flushing pressure for the legacy and high-checkpoint algorithm
已生成 ioCapMax/ioCap 比率为 10 的图表。Percona High Checkpoint 算法开始缓慢,但随后迅速增加。这允许更多脏页(参见我们之前的帖子讨论过),这样对性能有好处。返回的百分比值可能远高于100,(刷新机制的利用率比较高)
Average Over Time
到目前为止,我们只讨论了 checkpoint age 。刷新算法的目标以刷新位点移动的速率和 checkpoint age 更新的速率持平。大约每隔 innodb_flushing_avg_loops
秒,就会测量刷新页面的速率和重做日志 head 的进度,并将新值与前一个值取平均值。这里的目标是给自适应刷新算法一些惯性以抑制刷新速率上变化。innodb_flushing_avg_loops
的值越大,算法反应越慢,而值越小,反应越慢。我们将这些量称为 avgPagesFlushed
和 avgLsnRate
。
Pages to Flush for the avgLsnRate
根据 avgLsnRate 值,InnoDB 扫描缓冲池中最旧的脏页并计算小于尾部 avgLsnRate 的页数。由于这是每秒计算一次,因此需要刷新返回的页面数以保持正确的速率。我们称这个数字为 pagesForLsnRate。
最后…
我们现在拥有我们刷新需要的所有信息,将被刷新的实际页数由下式给出:
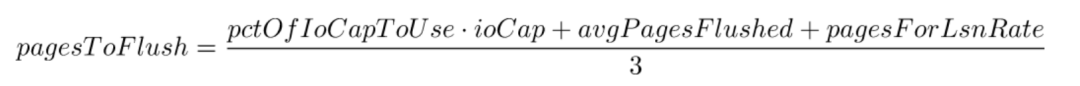
然后将此数量限制为 ioCapMax 。如您所见,pctOfIoCapToUse乘以ioCap。如果您回顾给出 pctOfIoCapToUse 的方程式,它们的分母为ioCap,结果ioCap 分子分母抵消,因此自适应刷新算法独立于innodb_io_capacity
,因为只有 innodb_io_capacity_max
很重要。如果设置了 innodb_flush_neighbors
,也可能会刷新更多页面。(对于SSD ,一般会关闭 innodb_flush_neighbors
)
是否可以通过调大 innodb_io_capacity_max
来提高刷新速率?
当然,如果 innodb_flush_sync
为 ON , 如果已达到或即将达到最大 checkpoint age ,InnoDB 有权超越该期限,可以大于 innodb_io_capacity_max
的数量刷新pages 。如果 innodb_flush_sync
为 OFF, InnoDB 刷新的时候 则不能超过 innodb_io_capacity_max
。如果系统的读请求的延迟非常严重,则可以通过关闭 innodb_flush_sync
来缓解或者避免 IO 风暴,但是此举也会加重写负载。
InnoDB page_cleaner 提示信息
MySQL error.log 里面经常会遇到如下信息:
[Note] InnoDB: page_cleaner: 1000ms intended loop took 4013ms. The settings might not be optimal. (flushed=1438 and evicted=0, during the time.)
如果信息出现的比较频繁,意味着 磁盘无法每秒刷新 innodb_io_capacity_max
页。在上面的信息提示中,InnoDB 尝试刷新 1438 页,但旋转磁盘每秒只能执行 360 次。因此,本应花费 1 秒的 flush 操作最终花费了 4 秒。如果您真的认为存储能够提供 innodb_io_capacity_max
规定的写入 IOPS 数量,那么它可能是遇到以下几种情况:
innodb_io_capacity_max
表示要刷新的页数,刷新一页可能需要多个IO,尤其是表空间数很大的时候。
读取 IOPS 的峰值与写IO的竞争。
设备出现写入延迟峰值。SSD 上的垃圾收集可能会导致这种情况,尤其是在 SSD空间已满时。
双写缓冲区存在争用。试试 Percona Server for MySQL 的并行双写缓冲区功能。
您是否有足够的page cleaners 来充分利用您的CPU和 IO ?
InnoDB 调优
行文至此,我们已经了解 InnoDB 是如何刷脏页到磁盘的,下一步就是如何针对刷脏进行调优。InnoDB 调优的相关参数将在 后面的文章中揭晓。
https://www.percona.com/blog/2011/03/31/innodb-flushing-a-lot-of-memory-and-slow-disk/
https://www.percona.com/blog/2011/04/04/innodb-flushing-theory-and-solutions/
https://baijiahao.baidu.com/s?id=1710205809874468728
