




好吧,每年的这个时候,我们再一次来看看PostgreSQL的最新版本。
按照传统,在Percona这里,团队会得到一份要写的特性列表。我的碰巧是关于一个非常基本的,我可能会添加重要的功能,即SELECT DISTINCT。
在进入细节之前,我想提一些关于这个博客的结果是如何得出的注意事项:
- 这些表非常小,结构也很简单。
- 因为这个演示是在一个相对低功耗的系统上执行的,所以真正的指标有可能比演示的要大得多。
对于那些不熟悉postgres和ANSI SQL标准的人来说,SELECT DISTINCT语句通过匹配指定的表达式从结果中消除重复的行。
例如,给定下表:
table t_ex; c1 | c2 ----+---- 2 | B 4 | C 6 | A 2 | C 4 | B 6 | B 2 | A 4 | B 6 | C 2 | C复制
此 SQL 语句以 SORTED 顺序返回那些过滤掉“c1”列中的 UNIQUE 值的记录:
select distinct on(c1) * from t_ex;复制
请注意,如“c2”列所示,c1 唯一性返回表中找到的第一个值:
c1 | c2 ----+---- 2 | B 4 | B 6 | B复制
此 SQL 语句返回那些过滤掉在“c2”列中找到的唯一值的记录
select distinct on(c2) * from t_ex;复制
c1 | c2 ----+---- 6 | A 2 | B 4 | C复制
最后,当然,返回整行的唯一性:
select distinct * from t_ex;复制
c1 | c2 ----+---- 2 | A 6 | B 4 | C 2 | B 6 | A 2 | C 4 | B 6 | C复制
那么,你会问,这个独特的新增强是什么?答案是并行化了!
在过去,只使用单个CPU/进程来计算不同记录的数量。然而,在postgres版本15中,现在可以通过并行运行多个worker来分解计数任务,每个worker分配给一个单独的CPU进程。有许多运行时参数控制这种行为,但我们将重点关注的是max_parallel_workers_per_gather。
让我们生成一些指标!
为了演示这种改进的性能,创建了三个表,没有索引,并填充了大约5,000,000条记录。注意每个表的列数,即分别为1、5和10列:
Table "public.t1" Column | Type | Collation | Nullable | Default --------+---------+-----------+----------+--------- c1 | integer | | |复制
Table "public.t5" Column | Type | Collation | Nullable | Default --------+-----------------------+-----------+----------+--------- c1 | integer | | | c2 | integer | | | c3 | integer | | | c4 | integer | | | c5 | character varying(40) | | |复制
Table "public.t10" Column | Type | Collation | Nullable | Default --------+-----------------------+-----------+----------+--------- c1 | integer | | | c2 | integer | | | c3 | integer | | | c4 | integer | | | c5 | character varying(40) | | | c6 | integer | | | c7 | integer | | | c8 | integer | | | c9 | integer | | | c10 | integer | | |复制
insert into t1 select generate_series(1,500);复制
insert into t5 select generate_series(1,500) ,generate_series(500,1000) ,generate_series(1000,1500) ,(random()*100)::int ,'aofjaofjwaoeev$#^ÐE#@#Fasrhk!!@%Q@';复制
insert into t10 select generate_series(1,500) ,generate_series(500,1000) ,generate_series(1000,1500) ,(random()*100)::int ,'aofjaofjwaoeev$#^ÐE#@#Fasrhk!!@%Q@' ,generate_series(1500,2000) ,generate_series(2500,3000) ,generate_series(3000,3500) ,generate_series(3500,4000) ,generate_series(4000,4500);复制
List of relations Schema | Name | Type | Owner | Persistence | Access method | Size | --------+------+-------+----------+-------------+---------------+--------+ public | t1 | table | postgres | permanent | heap | 173 MB | public | t10 | table | postgres | permanent | heap | 522 MB | public | t5 | table | postgres | permanent | heap | 404 MB |复制
下一步是将上述数据转储复制到以下版本的 postgres 中:
PG VERSION pg96 pg10 pg11 pg12 pg13 pg14 pg15复制
postgres 二进制文件是从源代码编译的,数据集群是在相同的低功耗硬件上使用默认且未调整的运行时配置值创建的。
填充后,将执行以下 bash 脚本以生成结果:
#!/bin/bash for v in 96 10 11 12 13 14 15 do # run the explain analzye 5X in order to derive consistent numbers for u in $(seq 1 5) do echo "--- explain analyze: pg${v}, ${u}X ---" psql -p 100$v db01 -c "explain analyze select distinct on (c1) * from t1" > t1.pg$v.explain.txt psql -p 100$v db01 -c "explain analyze select distinct * from t5" > t5.pg$v.explain.txt psql -p 100$v db01 -c "explain analyze select distinct * from t10" > t10.pg$v.explain.txt done done复制
结果如下:可以看到,表格越大,可以实现的性能提升就越大。
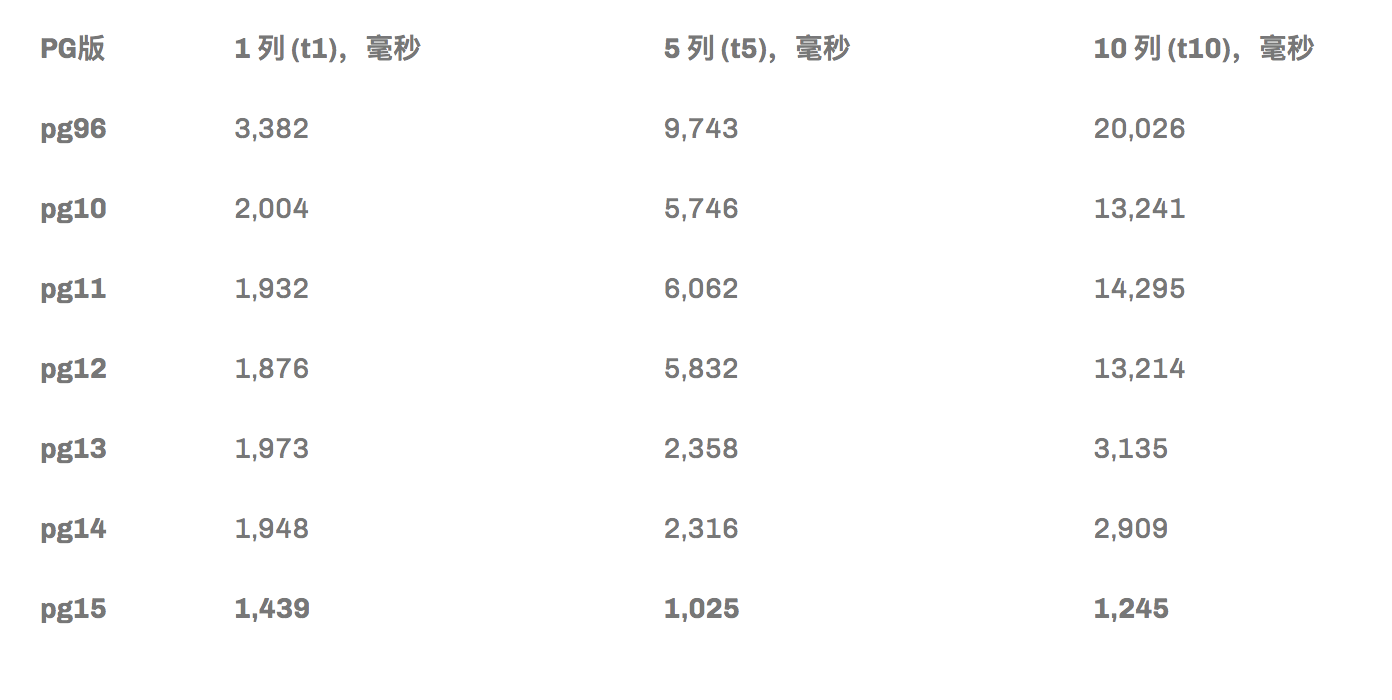
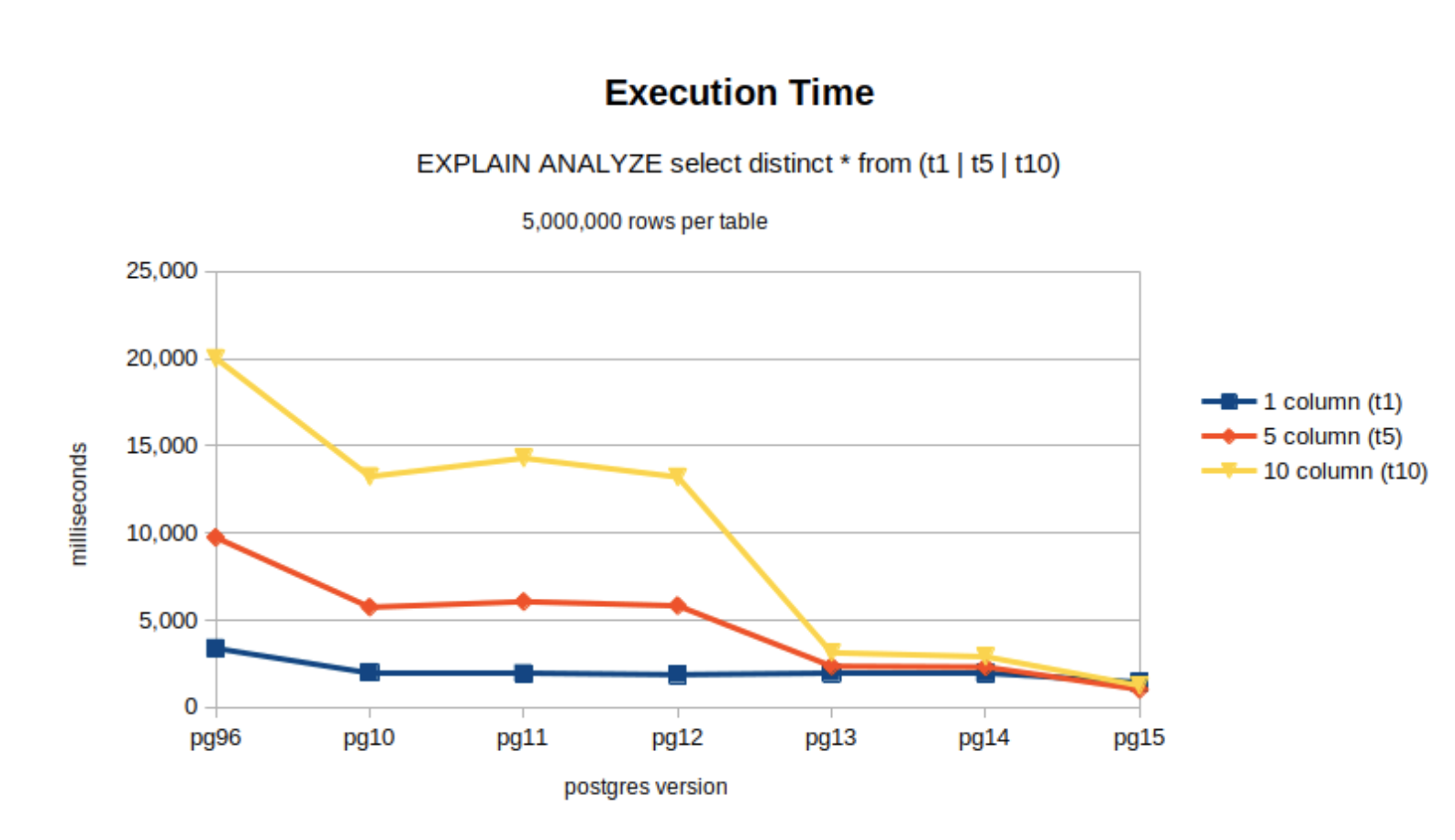
查询计划
调查中更有趣的方面之一是审查不同版本的 postgres 之间的查询计划。例如,单列 DISTINCT 的查询计划实际上非常相似,当然忽略了优越的执行时间,分别在 postgres 9.6 和 15 计划之间。
PG96 QUERY PLAN, TABLE T1 ------------------------------------------------------------------------------- Unique (cost=765185.42..790185.42 rows=500 width=4) (actual time=2456.805..3381.230 rows=500 loops=1) -> Sort (cost=765185.42..777685.42 rows=5000000 width=4) (actual time=2456.804..3163.600 rows=5000000 loops=1) Sort Key: c1 Sort Method: external merge Disk: 68432kB -> Seq Scan on t1 (cost=0.00..72124.00 rows=5000000 width=4) (actual time=0.055..291.523 rows=5000000 loops=1) Planning time: 0.161 ms Execution time: 3381.662 ms复制
PG15 QUERY PLAN, TABLE T1 --------------------------------------------------------------------------- Unique (cost=557992.61..582992.61 rows=500 width=4) (actual time=946.556..1411.421 rows=500 loops=1) -> Sort (cost=557992.61..570492.61 rows=5000000 width=4) (actual time=946.554..1223.289 rows=5000000 loops=1) Sort Key: c1 Sort Method: external merge Disk: 58720kB -> Seq Scan on t1 (cost=0.00..72124.00 rows=5000000 width=4) (actual time=0.038..259.329 rows=5000000 loops=1) Planning Time: 0.229 ms JIT: Functions: 1 Options: Inlining true, Optimization true, Expressions true, Deforming true Timing: Generation 0.150 ms, Inlining 31.332 ms, Optimization 6.746 ms, Emission 6.847 ms, Total 45.074 ms Execution Time: 1438.683 ms复制
当 DISTINCT 列的数量增加时,真正的差异出现了,如查询表 t10 所示。可以看到并行化在起作用!
Shell PG96 QUERY PLAN, TABLE T10 ------------------------------------------------------------------------------------------- Unique (cost=1119650.30..1257425.30 rows=501000 width=73) (actual time=14257.801..20024.271 rows=50601 loops=1) -> Sort (cost=1119650.30..1132175.30 rows=5010000 width=73) (actual time=14257.800..19118.145 rows=5010000 loops=1) Sort Key: c1, c2, c3, c4, c5, c6, c7, c8, c9, c10 Sort Method: external merge Disk: 421232kB -> Seq Scan on t10 (cost=0.00..116900.00 rows=5010000 width=73) (actual time=0.073..419.701 rows=5010000 loops=1) Planning time: 0.352 ms Execution time: 20025.956 ms复制
PG15 QUERY PLAN, TABLE T10 ------------------------------------------------------------------------------------------- HashAggregate (cost=699692.77..730144.18 rows=501000 width=73) (actual time=1212.779..1232.667 rows=50601 loops=1) Group Key: c1, c2, c3, c4, c5, c6, c7, c8, c9, c10 Planned Partitions: 16 Batches: 17 Memory Usage: 8373kB Disk Usage: 2976kB -> Gather (cost=394624.22..552837.15 rows=1002000 width=73) (actual time=1071.280..1141.814 rows=151803 loops=1) Workers Planned: 2 Workers Launched: 2 -> HashAggregate (cost=393624.22..451637.15 rows=501000 width=73) (actual time=1064.261..1122.628 rows=50601 loops=3) Group Key: c1, c2, c3, c4, c5, c6, c7, c8, c9, c10 Planned Partitions: 16 Batches: 17 Memory Usage: 8373kB Disk Usage: 15176kB Worker 0: Batches: 17 Memory Usage: 8373kB Disk Usage: 18464kB Worker 1: Batches: 17 Memory Usage: 8373kB Disk Usage: 19464kB -> Parallel Seq Scan on t10 (cost=0.00..87675.00 rows=2087500 width=73) (actual time=0.072..159.083 rows=1670000 loops=3) Planning Time: 0.286 ms JIT: Functions: 31 Options: Inlining true, Optimization true, Expressions true, Deforming true Timing: Generation 3.510 ms, Inlining 123.698 ms, Optimization 200.805 ms, Emission 149.608 ms, Total 477.621 ms Execution Time: 1244.556 ms复制
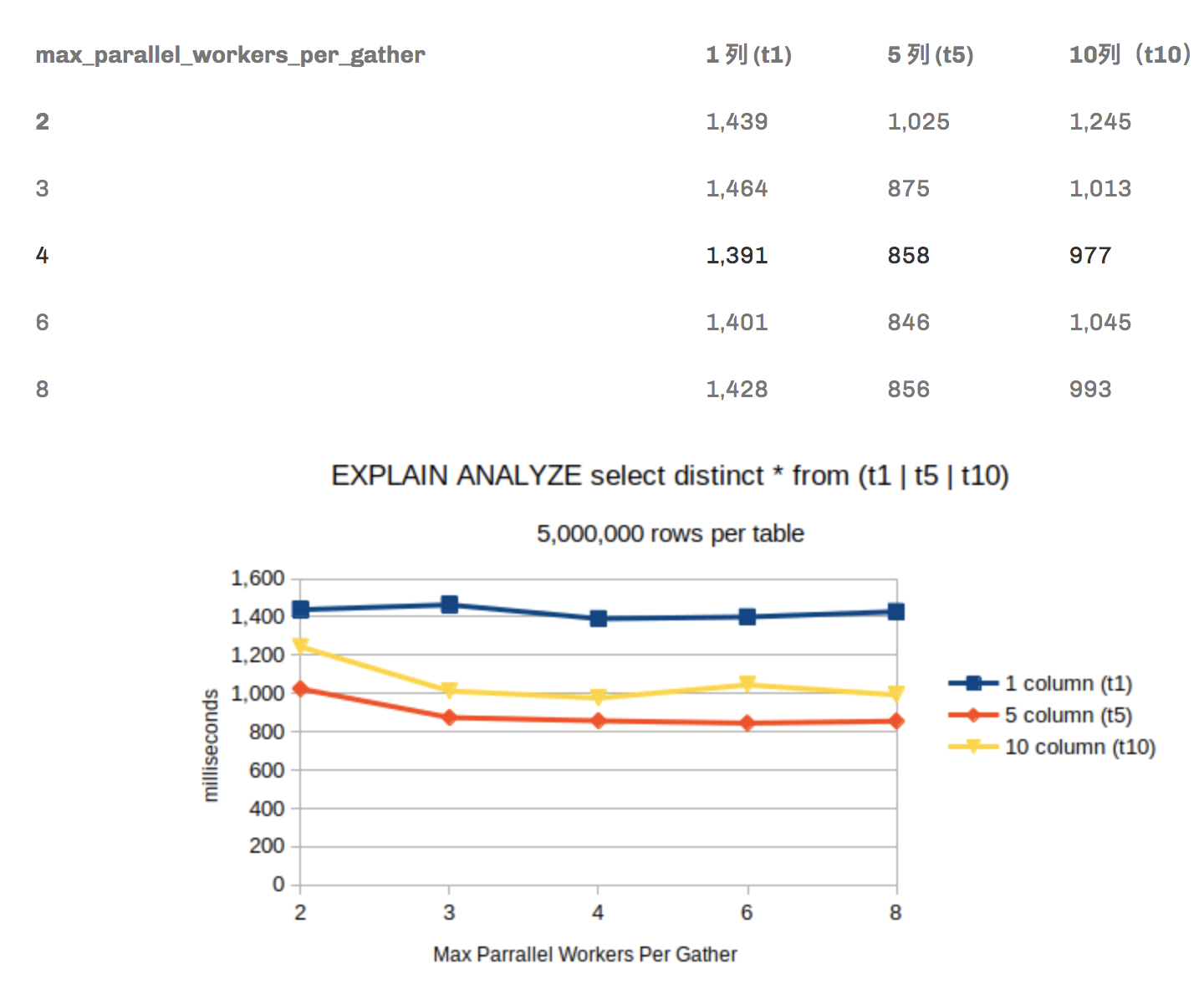
提高性能:通过更新 postgres 运行时参数max_parallel_workers_per_gather来提高性能。新初始化的集群中的默认值为 2。如下表所示,由于测试硬件本身的能力有限,它很快成为收益递减的问题。
POSTGRES 15 版本
关于索引:如本查询计划中所示应用索引时,性能改进并未实现。
PG15、TABLE T10(10 个 DISTINCT 列)和max_parallel_workers_per_gather=4 :
QUERY PLAN ----------------------------------------------------------------------------------- Unique (cost=0.43..251344.40 rows=501000 width=73) (actual time=0.060..1240.729 rows=50601 loops=1) -> Index Only Scan using t10_c1_c2_c3_c4_c5_c6_c7_c8_c9_c10_idx on t10 (cost=0.43..126094.40 rows=5010000 width=73) (actual time=0.058..710.780 rows=5010000 loops=1) Heap Fetches: 582675 Planning Time: 0.596 ms JIT: Functions: 1 Options: Inlining false, Optimization false, Expressions true, Deforming true Timing: Generation 0.262 ms, Inlining 0.000 ms, Optimization 0.122 ms, Emission 2.295 ms, Total 2.679 ms Execution Time: <strong>1249.391 ms</strong>复制
结论
跨多个 CPU 运行 DISTINCT 是性能能力的一大进步。但请记住,当您增加max_parallel_workers_per_gather的数量并接近硬件的限制时,性能下降的风险。正如调查显示的那样,在正常情况下,查询规划器可能会决定使用索引而不是运行并行工作程序。解决此问题的一种方法是考虑禁用运行时参数,例如enable_indexonlyscan和enable_indexscan 。最后,不要忘记运行 EXPLAIN ANALYZE 以了解发生了什么。
原文标题:Introducing PostgreSQL 15: Working with DISTINCT
原文作者:Robert Bernier
原文地址:https://www.percona.com/blog/introducing-postgresql-15-working-with-distinct/



