




数据分片是分布式数据库横向扩展的基础,本文主要整理了GoldenDB的数据库分片技术以及数据重分布实现的过程,加深对分片和重分布技术的理解。
1、数据分片规则
垂直切分是按照不同的表切分到不同的数据库中,适用于业务系统之间耦合度低、业务逻辑清晰的系统
水平切分是根据表中数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库上,对应用来说更为复杂
无限扩展:数据分片水平切分扩展到多个物理节点,理论上支持无限扩展
性能提升:数据分片以后单个数据节点上上的数据集变小,数据库查询的压力变小、查询更快,性能更好;同时水平切分以后查询可以并发执行,提升了系统的吞吐量
高可用:部分分片节点宕机只会影响该部分分片的服务,不会影响整个系统的可用性
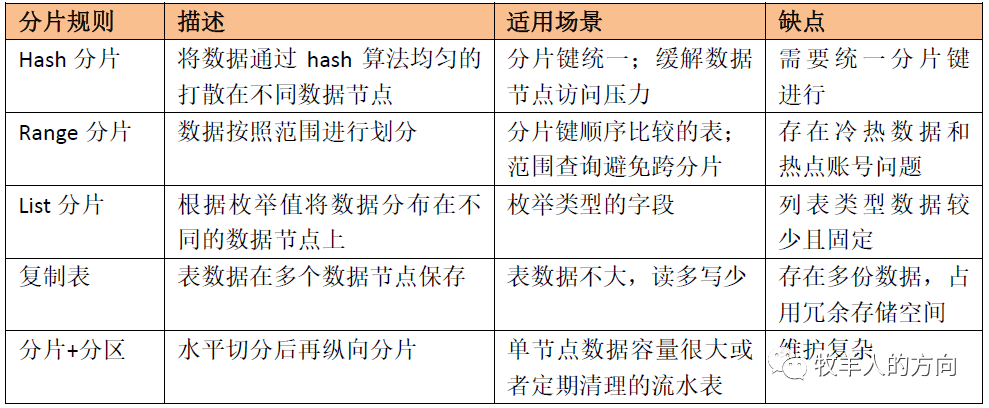

1.1 Hash分片
1.1.1 普通hash算法
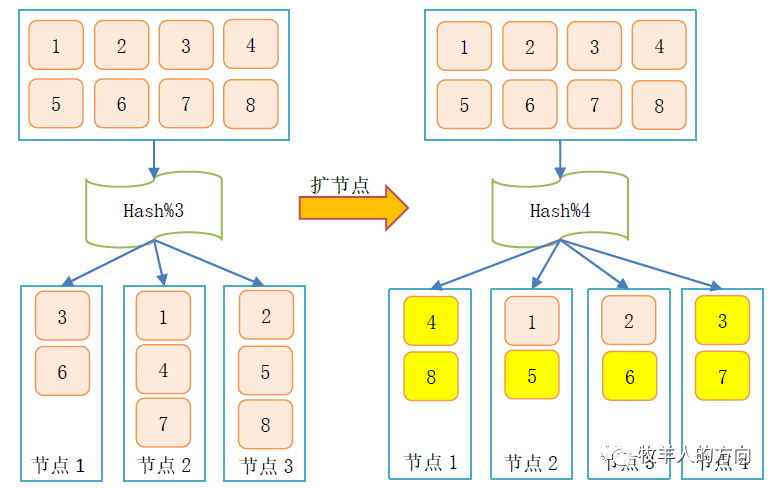
1.1.2 一致性hash算法
一致性Hash算法最早是解决分布式cache提出的,它将整个hash值空间组织成一个虚拟的圆环,根据节点名称的Hash值将服务器节点放置在这个Hash环上,然后根据数据的Key值计算得到其Hash值,接着在Hash环上顺时针查找距离这个Key值的Hash值最近的服务器节点,完成Key到服务器的映射查找。
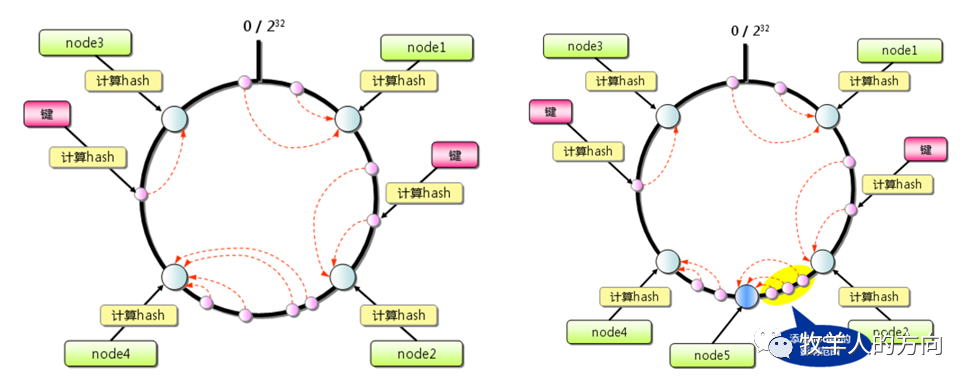
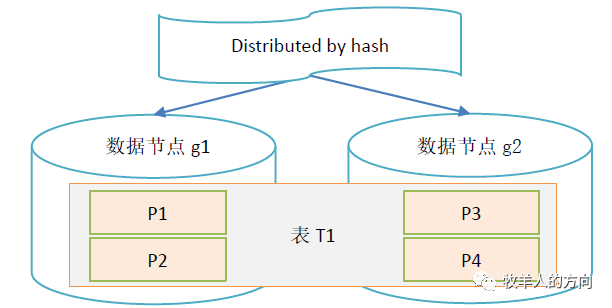
GoldenDB中的hash算法
对分片键计算hash值,该hash值会落到0~N的封闭圆环中
按照分片数量M将hash值均分为M段(M<<N),确定每个分段的值范围
将落入同一个分段的hash值划分在同一个分片上
当增加数据节点时候,会使用到hash流式重分布策略,将其它分片的hash值搬动到新增的节点,使得数据均匀分布
Hash分片的语法如下:
Create table t1(a int,b int) distributed by hash(a)(g1,g2,g3);
1.2 Range分片
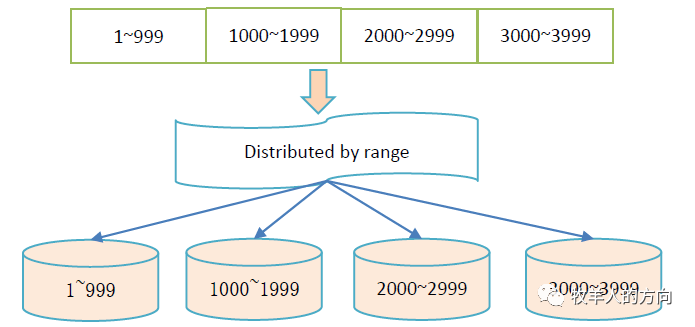
GoldenDB中range分区示例:
Create table t1(a bigint,b char(6)) distributed by range(a)(g1 values less than (1000),g2 values less than (2000),g3 values less than maxvalues);
1.3 List分片
List分片是根据不同的枚举值将数据分布在不同的分片上,比如分片键为银行法人,将不同的法人部署在单独的分片上。List分片适合分片键数据较少且固定的场景,但是不同枚举值的数据分布可能出现不均衡的问题。
GoldenDB中List分片示例:
Create table t1(a varchar(4),b char(6)) distributed by list(a)(g1 values in(‘CN’),g2 values in (‘HK’));
1.4 复制表
复制表是在数据节点保留全量的数据副本,有多节点复制表和单节点复制表,通常用于表的数据读多写少变化不大的场景,比如参数表。复制表的好处是将公共访问表存放在本地数据节点,可以减少跨节点的表数据访问和分布式事务开销,提升SQL的性能。
GoldenDB中复制表示例:
Create table t1(a varchar(4),b char(6)) distributed by duplicate(g1,g2,g3);
1.5 多级分片
多级分片是通过多维属性对数据分片进行精确控制,通常是通过多个字段进行多层次分片,比如通过法人字段进行一级分片,再按照客户类型字段进行二级分片。
GoldenDB中多级分片示例:
Create table t1(a int,b int,c int) distributed by case c when 1 then case when b<100 then subdistributed by hash(a) (g1); else subdistributed by hash(a) (g2); end case; when 2 then subdistributed by hash(a) (g3); else subdistributed by hash(a) (g4);end case;
1.6 GoldenDB中分区
GoldenDB中分片+分区示例:
Create table t1(a int,b int,c int) partition by range (c) (partition p1 values less than (20210101), partition p2 values less than (20210201),partition p3 values less than (20210301), partition p4 values less than (20210401)) distributed by hash (a) (g1,g2);
2、分片路由

2.1 表分片DDL过程
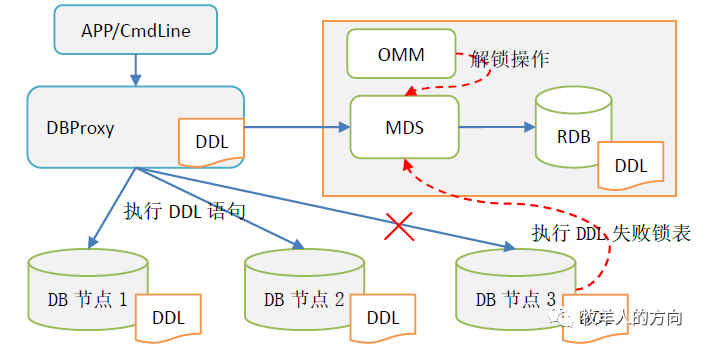
DBProxy接收到DDL信息后,会通知MDS更新元数据信息,并持久化保存到RDB中
DBProxy将DDL语句下推到每个数据节点分别执行
DBProxy本地内存和数据节点中会保存一份全量的表结构信息
DDL执行过程中如果出错,会通知MDS将表状态禁用,需要手动解锁;表禁用后业务访问会出错
RDB中的DDL信息会定期同步到DBProxy计算节点和DB数据节点
应用访问时会优先从本地读取DDL信息
2.2 表分片的插入过程
DBProxy接收到SQL信息后,从MDS获取表的分片信息并解析SQL
DBProxy根据分片规则将SQL语句下发到不同的DB分片节点
DB分片节点执行insert语句,并返回执行结果给计算节点DBProxy
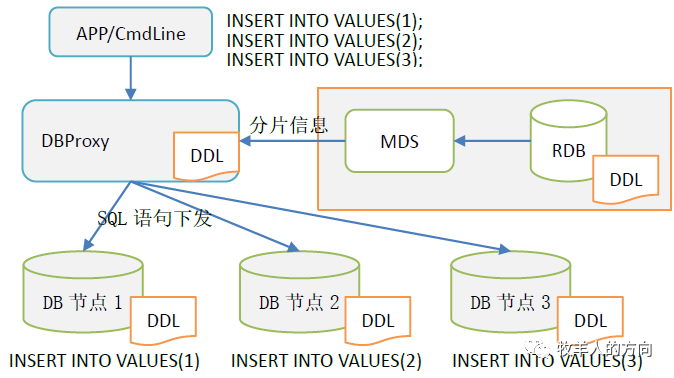
根据路由规则可以看到,相同的表名在不同的DB数据节点执行的是不同的SQL语句。
2.3 表分片的查询过程
DBProxy接收到SQL信息后,从MDS获取表的分片信息并解析SQL
DBProxy根据分片规则将查询语句下发到不同的DB分片节点
DB分片节点执行SQL查询语句,并返回结果集给计算节点DBProxy进行汇总,再返回给客户端
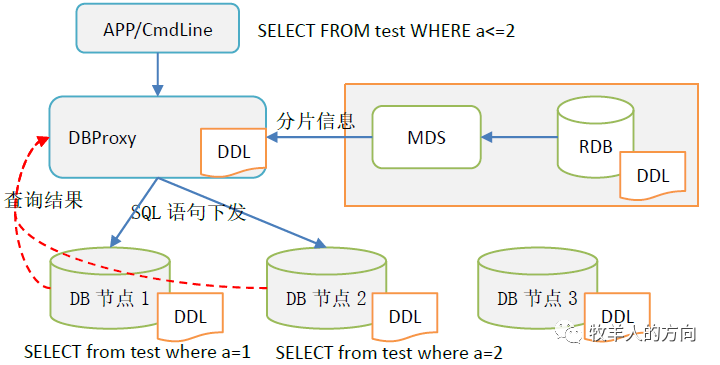
注:对于不带分片键的查询,会将DB数据节点的查询结果汇总到计算节点,当数据量很大时会出现计算节点OOM情况。
3、在线重分布
3.1 数据重分布策略
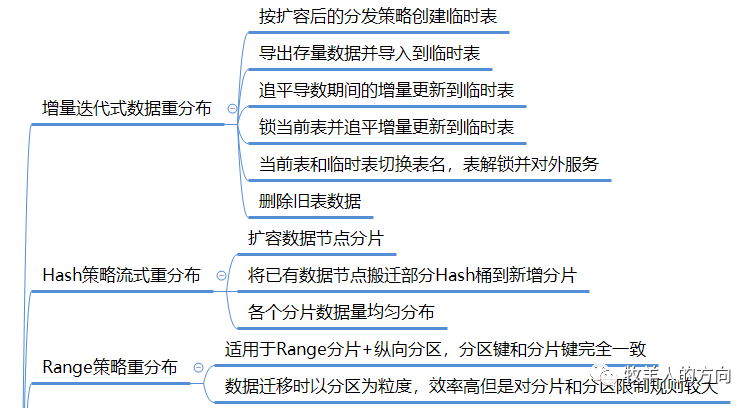
3.1.1 增量迭代式数据重分布
分片策略的变更,由hash变为range,复制表变为分片表等
表分片键的变更,由A列调整为B列
分片策略不变,数据节点横向扩容的场景
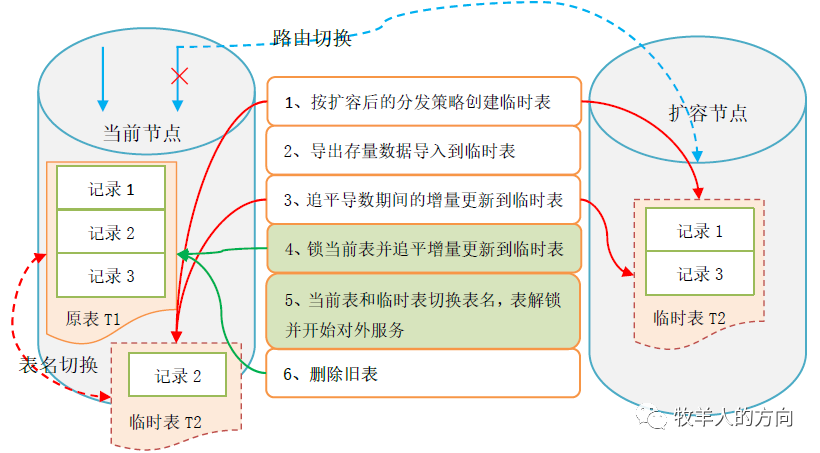
按照扩容后的分发策略创建临时表
导出需要重分布的数据节点的数据,并导入到临时表
通过binlog数据追平导数期间增量更新的数据到临时表
将当前表锁住(此时应用不能更新表),并通过binlog追平增量更新数据
数据校验完毕后,将临时表和新表切换表名,解锁并对外提供服务
删除旧表的数据
锁表和切换表名的过程中,影响应用的写操作
重分布过程中临时表需要额外的存储空间,重分布操作前需要保证存储空间充足
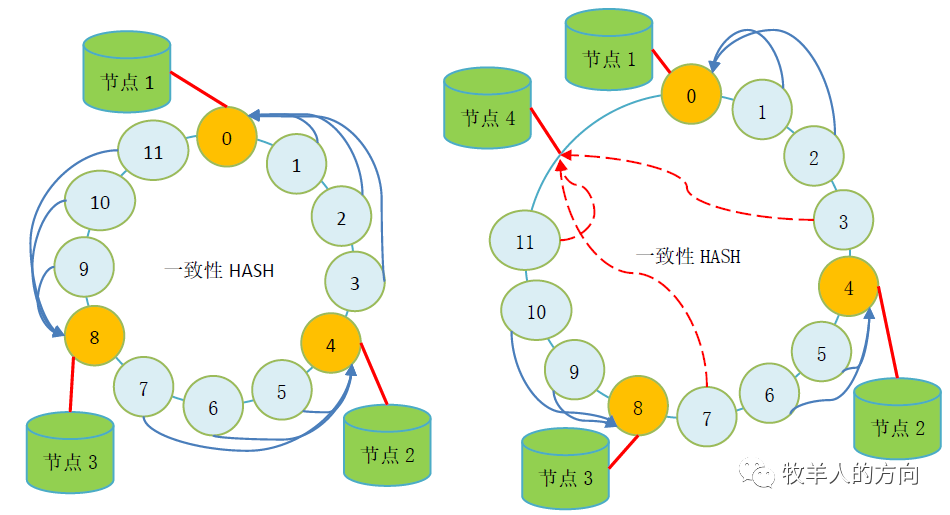
3.1.2 Hash策略流式重分布
系统中默认包含2048*128个HASH桶,新增数据节点的过程中会并行的从现有的每个分片节点迁移部分数据到新增分片上,确保所有分片数据平均
整个数据迁移的过程是在现有分片数据上动态操作,对磁盘空间没有额外的要求
同步更新MDS和DB节点中表的分片信息
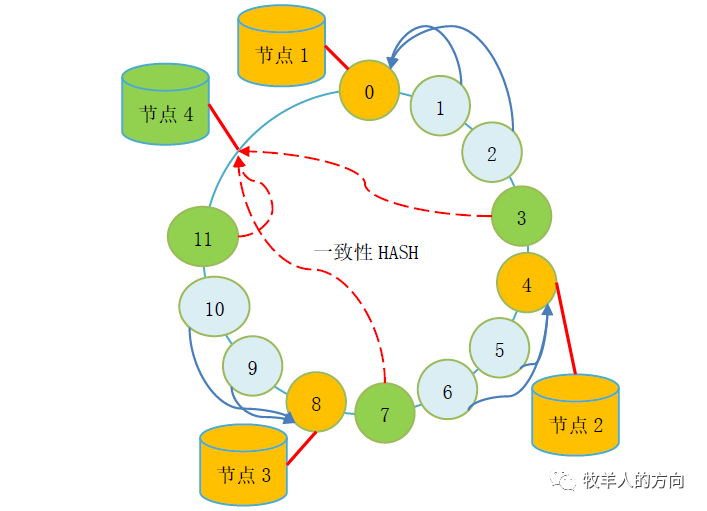
分片数据从现有分片移动到新增分片的方法,直接导出再load进去?
数据移动的过程中,应用访问到的数据的节点信息和移动后的数据信息不一致该如何处理?
现有分片数据移动到新增分片的算法,即哪些数据会搬到新的分片节点
Hash桶数量是有限的,是否会出现Hash值重复的情况?
3.2 重分布任务

3.2.1 创建重分布任务
解析重分布任务:MDS对重分布任务进行检查,解析出新的重分布策略,并根据表的老旧分发规则解析出本次重分布涉及哪些分片
分解重分布步骤并保存重分布任务:MDS会把重分布任务分解为执行步骤,并保存到元数据RDB中
创建临时表:MDS向各DB分片发起创建临时表的请求,临时表的命名规则为原表名_时间戳
重分布上述三个步骤其中一个失败,整个重分布任务即为失败。同时需要注意的是一张表同时只能有两个重分布任务并行执行,并且重分布的表必须有主键,因为在增量同步过程中读取binlog解析增量更新的数据,再根据主键更新到临时表中。
3.2.2 线下阶段(全量部分)
全量备份:使用mysqldump进行全量数据备份
全量恢复:全量恢复是将备份文件根据新的分发策略切分为多个文件传输到其它DB数据节点,并恢复到临时表中
全量校验:进行全量数据校验,如果数据出现不一致,需重头发起重分布任务
创建索引:数据校验完成后会通过DBProxy为临时表创建索引
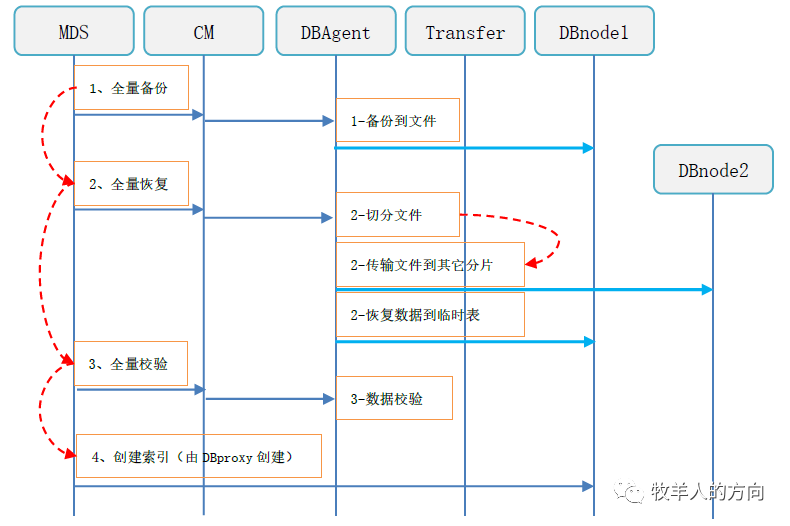
3.2.3 线下阶段(增量部分)
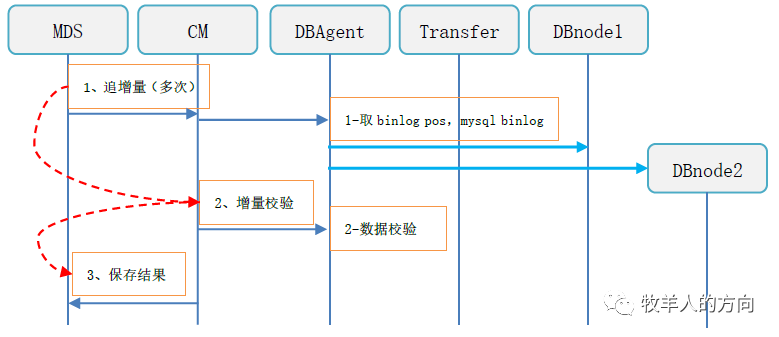
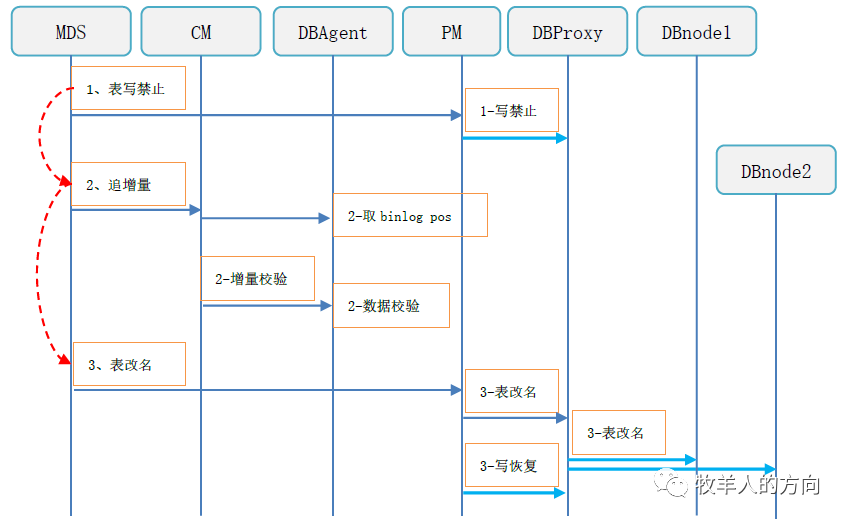
3.2.4 线上阶段
表写禁止,此时业务只能查询,不能增删改操作
追加全部的binlog数据
增量校验数据的一致性,如果不一致则需要重新开始重分布任务
数据校验完成后切换表名
恢复表的写访问,对外提供服务
清理旧表的数据
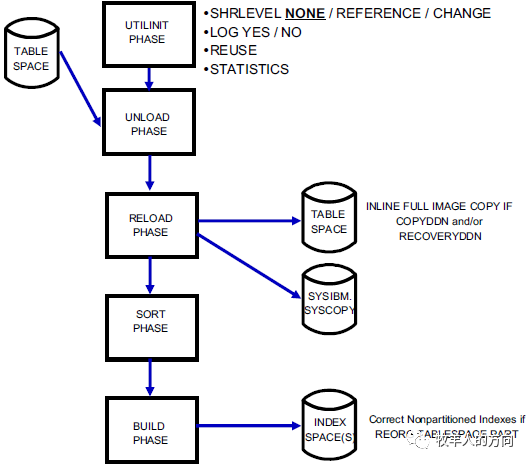
至此,GoldenDB分片和数据重分布过程到此结束,其实在线数据重分布的过程和DB2的在线重组过程在实现机制上非常相似。
参考资料
https://www.cnblogs.com/lpfuture/p/5796398.html
https://cloud.tencent.com/developer/article/1763380
GoldenDB数据库分片和重分布技术介绍
