




前言

Hudi诞生背景

Copy-On-Write(COW)

Merge-On-Read (MOR)

COW和MOR对比
非常适合查询延迟低的场景表更新效率不如MORUber就使用COW表存储追加写的数据,比如记录用户交互的时间日志(用户点击按钮等)。复制
非常适合频繁更新的场景合并之前的查询性能低于COW表,但是合并之后的性能与COW表相同。MOR表避免了对数据文件不必要的重写,从而降低写入开销、降低了写入延迟。复制

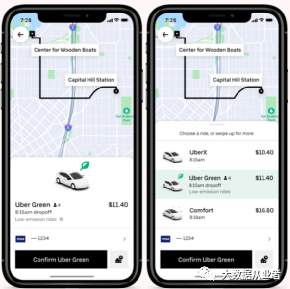
现实业务场景

文章转载自大数据从业者,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
相关阅读
金仓数据库26套!宁波市司法局信息系统适配改造(一期)采购项目
天下观查
325次阅读
2025-03-21 10:33:59
国产化+性能王炸!这套国产方案让 3.5T 数据 5 小时“无感搬家”
YMatrix
288次阅读
2025-03-13 09:51:26
大连农商40万,采购Greenplum数据库原厂订阅服务
天下观查
282次阅读
2025-03-13 09:52:29
国产数据库高光时刻!天翼云TeleDB荣登TPC-DS全球测评总榜第二
天翼云开发者社区
187次阅读
2025-03-13 17:24:48
DBAIOPS社区将在知衍平台上推出数据库运维智能体
白鳝的洞穴
178次阅读
2025-03-07 10:29:18
史诗级革新 | Apache Flink 2.0 正式发布
严少安
162次阅读
2025-03-25 00:55:05
为什么总是很难客观评价某个国产数据库产品
白鳝的洞穴
162次阅读
2025-03-19 11:21:09
晨章数据三款分布式数据库产品全面开源,以开放向AI时代进发
晨章数据
148次阅读
2025-03-10 17:10:07
天翼云:Apache Doris + Iceberg 超大规模湖仓一体实践
SelectDB
140次阅读
2025-03-18 15:02:51
众行者远 |《键值数据库性能测试方法》首次标准研讨会成功举行!
大数据技术标准推进委员会
136次阅读
2025-03-07 10:01:12




