




Domain Adaptation for Deep Entity Resolution.pdf
免费下载
Domain Adaptation for Deep Entity Resolution
Jianhong Tu
Renmin University, China
tujh@ruc.edu.cn
Ju Fan
∗
Renmin University, China
fanj@ruc.edu.cn
Nan Tang
QCRI, Qatar
ntang@hbku.edu.qa
Peng Wang
Renmin University, China
lisa_wang@ruc.edu.cn
Chengliang Chai
Tsinghua University, China
ccl@mail.tsinghua.edu.cn
Guoliang Li
Tsinghua University, China
liguoliang@tsinghua.edu.cn
Ruixue Fan
Renmin University, China
fanruixue@ruc.edu.cn
Xiaoyong Du
Renmin University, China
duyong@ruc.edu.cn
ABSTRACT
Entity resolution (ER) is a core problem of data integration. The
state-of-the-art (SOTA) results on ER are achieved by deep learning
(DL) based methods, trained with a lot of labeled matching/non-
matching entity pairs. This may not be a problem when using well-
prepared benchmark datasets. Nevertheless, for many real-world
ER applications, the situation changes dramatically, with a painful
issue to collect large-scale labeled datasets. In this paper, we seek
to answer: If we have a well-labeled source ER dataset, can we train
a DL-based ER model for a target dataset, without any labels or with
a few labels? This is known as domain adaptation (DA), which has
achieved great successes in computer vision and natural language
processing, but is not systematically studied for ER. Our goal is to
systematically explore the benets and limitations of a wide range
of DA methods for ER. To this purpose, we develop a
DADER
(
D
omain
A
daptation for
D
eep
E
ntity
R
esolution) framework that signicantly
advances ER in applying DA. We dene a space of design solutions
for the three modules of
DADER
, namely Feature Extractor, Matcher,
and Feature Aligner. We conduct so far the most comprehensive
experimental study to explore the design space and compare dif-
ferent choices of DA for ER. We provide guidance for selecting
appropriate design solutions based on extensive experiments.
CCS CONCEPTS
• Information systems → Entity resolution.
KEYWORDS
Domain adaptation; Data integration; Deep learning
ACM Reference Format:
Jianhong Tu, Ju Fan, Nan Tang, Peng Wang, Chengliang Chai, Guoliang Li,
Ruixue Fan, and Xiaoyong Du. 2022. Domain Adaptation for Deep Entity
Resolution. In Proceedings of the 2022 International Conference on Manage-
ment of Data (SIGMOD ’22), June 12–17, 2022, Philadelphia, PA, USA. ACM,
New York, NY, USA, 15 pages. https://doi.org/10.1145/3514221.3517870
∗
Ju Fan is the corresponding author.
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for prot or commercial advantage and that copies bear this notice and the full citation
on the rst page. Copyrights for components of this work owned by others than ACM
must be honored. Abstracting with credit is permitted. To copy otherwise, or republish,
to post on servers or to redistribute to lists, requires prior specic permission and/or a
fee. Request permissions from permissions@acm.org.
SIGMOD ’22, June 12–17, 2022, Philadelphia, PA, USA.
© 2022 Association for Computing Machinery.
ACM ISBN 978-1-4503-9249-5/22/06.. . $15.00
https://doi.org/10.1145/3514221.3517870
Reducing
Domain Shift
Minimizing
Matching Errors
Source
Target
Source
Target
(a)
(b)
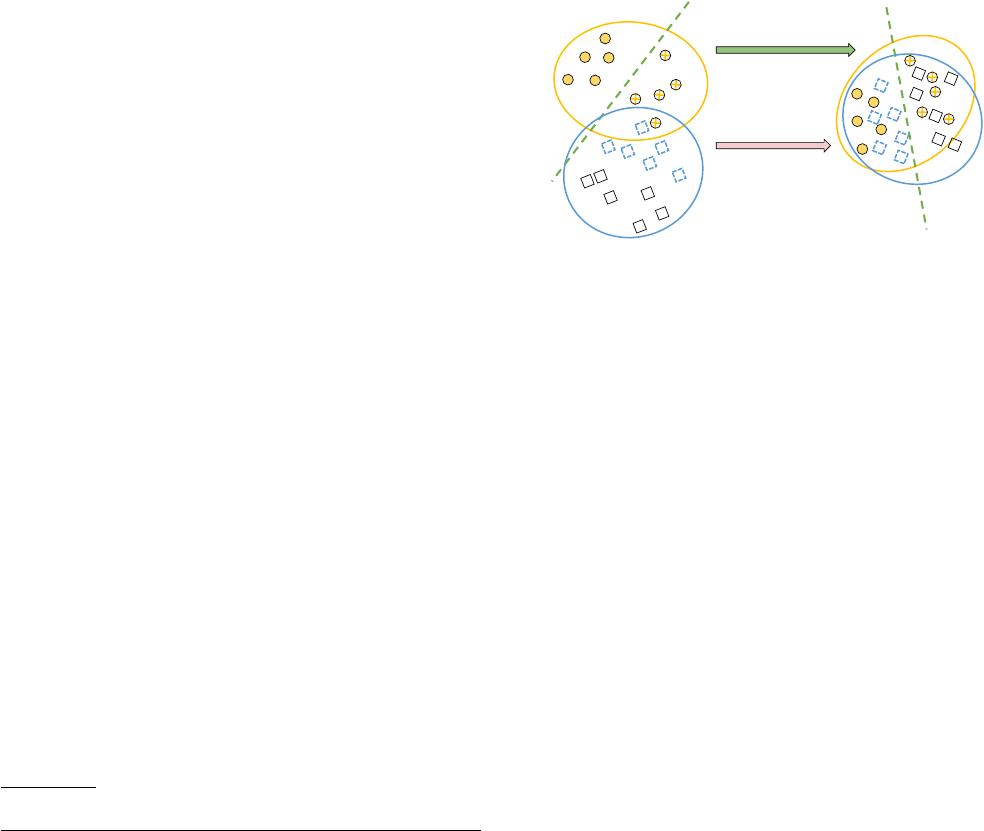
Figure 1: DA for ER. (a) A Matcher learned from labeled
source cannot perform well on unlabeled target due to do-
main shift. (b) Domain adaptation learns better representa-
tions to reduce domain shift and minimize matching errors.
1 INTRODUCTION
Entity resolution (ER) determines whether two data instances refer
to the same real-world entity. With the many decades of eorts of
approaching ER from the model-centric point of view, there has
been a considerable amount of literature, ranging from rule-based
methods (e.g., disjunctive normal form [
59
] and general boolean
formula [
59
]), ML-based methods (such as SVM [
5
] and random
forests [
20
]), to DL-based methods (such as DeepMatcher [
49
],
DeepER [
21
], and Ditto [
42
]). The state-of-the-art (SOTA) results
are, not surprisingly, achieved by DL-based solutions.
However, DL-based ER methods typically need a large amount
of labeled training data. For example, even by piggybacking pre-
trained language models such as Ditto [
42
], thousands of labels are
still needed to achieve a satisfactory accuracy. In fact, the main
pain point for ER practitioners is that they would need substantial
labeling eorts for creating enough training data.
Fortunately, the big data era makes a lot of labeled ER datasets
available in the same or relevant domains, either from public bench-
marks (e.g., WDC [
52
] and DBLP-Scholar [
49
]) or within enterprises.
Hence, a natural question is: can we reuse these labeled source ER
datasets for a new target ER dataset? An armative answer to
the above question has the potential to dramatically reduce the
expensive human eort for data labeling.
Domain adaptation.
The key challenge of reusing labeled source
data is that there may be distribution change or domain shift be-
tween the source and the target, which would degrade the perfor-
mance. Figure 1 (a) shows an example of a labeled source dataset
(circles) and an unlabeled target dataset (squares). As the source
and target datasets may not be from the same domain, they do not
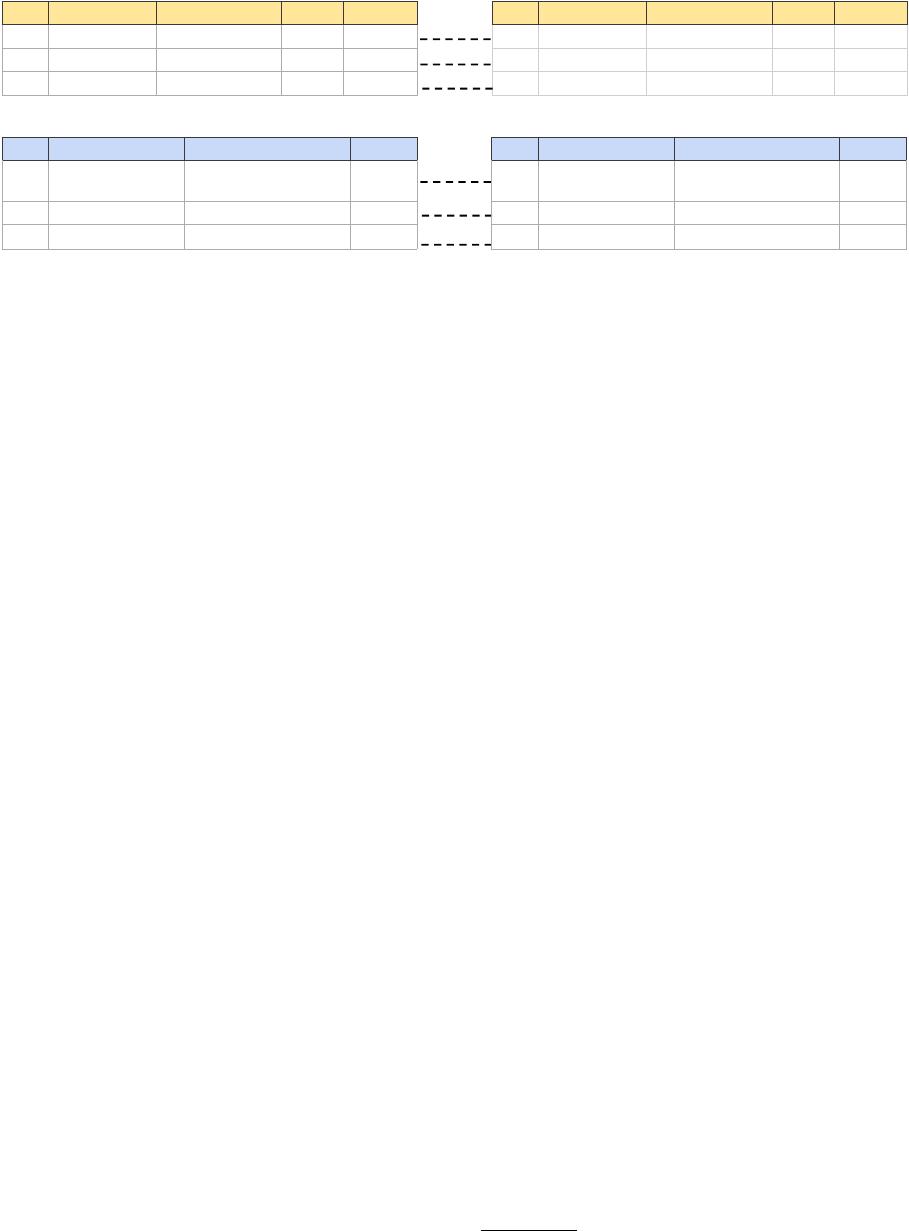
id title category brand price
𝑎
&
'
balt wheasel ... stationery ... balt 239.88
𝑎
(
'
kodak esp ... printers NULL 58.0
𝑎
)
'
hp q3675a ... printers hp 194.84
id title category brand price
𝑏
&
'
balt inc. ... laminating ...
mayline
134.45
𝑏
(
'
kodak esp 7 ... kodak NULL 149.29
𝑏
)
'
hewlett ... cleaning repair hp NULL
(𝑎
&
'
, 𝑏
&
'
, 1)
id name description price
𝑎
&
*
samsung 52 ' series 7
black flat ...
samsung 52 ' series 7
black flat panel lcd ...
NULL
𝑎
(
*
sony 46 ' bravia ... bravia z series ... NULL
𝑎
)
*
linksys wirelessn ... security router ... NULL
id name description price
𝑏
&
*
samsung ln52a750 ...
dynamic contrast ratio
120hz 6ms respons ...
2148.99
𝑏
(
*
sony bravia ... ntsc 16:9 1366 x 768 ... 597.72
𝑏
)
*
linksys wirelessg ... 54mbps NULL
(a) Labeled Source Dataset
(b) Unlabeled Target Dataset
(𝑎
(
'
, 𝑏
(
'
, 0)
(𝑎
)
'
, 𝑏
)
'
, 1)
(𝑎
&
*
, 𝑏
&
*
, ?)
(𝑎
(
*
, 𝑏
(
*
, ?)
(𝑎
)
*
, 𝑏
)
*
, ?)
Figure 2: A running example of DA for ER with a labeled source dataset D
S
and an unlabeled target dataset D
T
.
follow the same distribution. As a result, an ER model (the green
line) trained from the source cannot correctly predict the target. To
address the challenge, domain adaptation (DA) is extensively stud-
ied to utilize labeled data in one or more relevant source domains
for a new dataset in a target domain [
25
,
45
,
64
,
69
]. Intuitively, DA
is to learn from data instances what is the best way of aligning
distributions of the source and the target data, such that the models
trained on the labeled source can be used (or adapted) to the unla-
beled target. As illustrate in Figure 1 (b), the advantage of DA is its
ability to learn more domain-invariant representations that reduce
the domain shift between source and target, and to improve perfor-
mance of the ER model, e.g., the green line can correctly classify
data instances in both source and target datasets.
However, despite some very recent attempts [
35
], as far as we
know, the adoption of DA in ER is not systematically studied un-
der the same framework, and thus it is hard for practitioners to
understand DA’s benets and limitations for ER. To bridge this gap,
this paper introduces a general framework, called
DADER
(
D
omain
A
daptation for
D
eep
E
ntity
R
esolution) that unies a wide range of
choices of DA solutions [
73
,
74
]. Specically, the framework con-
sists of three main modules. (1) Feature Extractor converts entity
pairs to high-dimensional vectors (a.k.a. features). (2) Matcher is
a binary classier that takes the features of entity pairs as input,
and predicts whether they match or not. (3) Feature Aligner is the
key module for domain adaptation, which is designed to alleviate
the eect of domain shift. To achieve this, Feature Aligner adjusts
Feature Extractor to align distributions of source and target ER
datasets, which then reduces domain shift between source and
target. Moreover, it updates Matcher accordingly to minimize the
matching errors in the adjusted feature space.
Design space exploration.
Based on our framework, we system-
atically categorize and study the most representative methods in
DA for ER, and focus on investigating two key questions.
First, DA is a broad topic in machine learning (e.g., computer
vision and natural language processing), and there is a large set
of design choices for domain adaptation. Thus, it is necessary to
ask a question that which DA design choices would help ER. To
answer the question, we have extensively reviewed existing DA
studies, and then focus on the most popular and fruitful directions
that learn domain-invariant and discriminative features. Based on
this, we provide a categorization for each module in
DADER
and
dene a design space, by summarizing representative DA techniques.
Specically, Feature Extractor is typically implemented by recurrent
neural networks [
38
] and pre-trained language models [
19
,
44
,
55
].
Matcher often adopts a deep neural networks as a binary classier.
Feature Aligner is implemented by three categories of solutions:
(1) discrepancy-based, (2) adversarial-based, and (3) reconstruction-
based. As the concrete choices of Feature Extractor and Matcher
have been well studied, our focus is to identify methods for Feature
Aligner, for which we develop six representative methods that cover
a wide range of SOTA DA techniques.
The second question is whether DA is useful for ER to utilize la-
beled data in relevant domains. To answer this, this paper considers
two settings: (1) the unsupervised DA setting without any target
labels, and (2) the semi-supervised DA setting with a few target
labels. Moreover, we also compare
DADER
with SOTA DL solutions
for ER, such as DeepMatcher [
49
] and Ditto [
42
]. Based on the
comparison, we provide comprehensive analysis on the benets
and limitations of DA for ER.
Contributions:
(1) As far as we know, we are the rst to formally
dene the problem of
DA for deep ER
(Section 3) and conduct so
far the most comprehensive study for applying DA to ER.
(2) We introduce a
DADER
framework that supports DA for ER,
which consists of three modules, namely Feature Extractor, Matcher
and Feature Aligner. We systematically explore the design space of
DA for ER by categorizing each individual module in the framework
(Section 4). In particular, we develop
six representative methods
for Feature Aligner (Section 5).
(3) We conduct a thorough evaluation to explore the design space
and compare the developed methods (Section 6). The source code
and data have been made available at Github
1
. We nd that DA is
very promising for ER, as it reduces domain shift between source
and target. We point out some open problems of DA for ER and
identify research directions (Section 8).
2 DEEP ENTITY RESOLUTION
We formally dene entity resolution and present a framework of
using deep learning for entity resolution (or Deep ER for short).
Entity resolution.
Let
𝐴
and
𝐵
be two relational tables with multi-
ple attributes. Each tuple
𝑎 ∈ 𝐴
(or
𝑏 ∈ 𝐵
) is also referred to as an en-
tity consisting of a set of attribute-value pairs
{(attr
𝑖
, val
𝑖
)}
1≤𝑖 ≤𝑘
,
where
attr
𝑖
and
val
𝑖
denote the
𝑖
-th attribute name and value re-
spectively. The problem of entity resolution (ER) is to nd all the
1
https://github.com/ruc-datalab/DADER
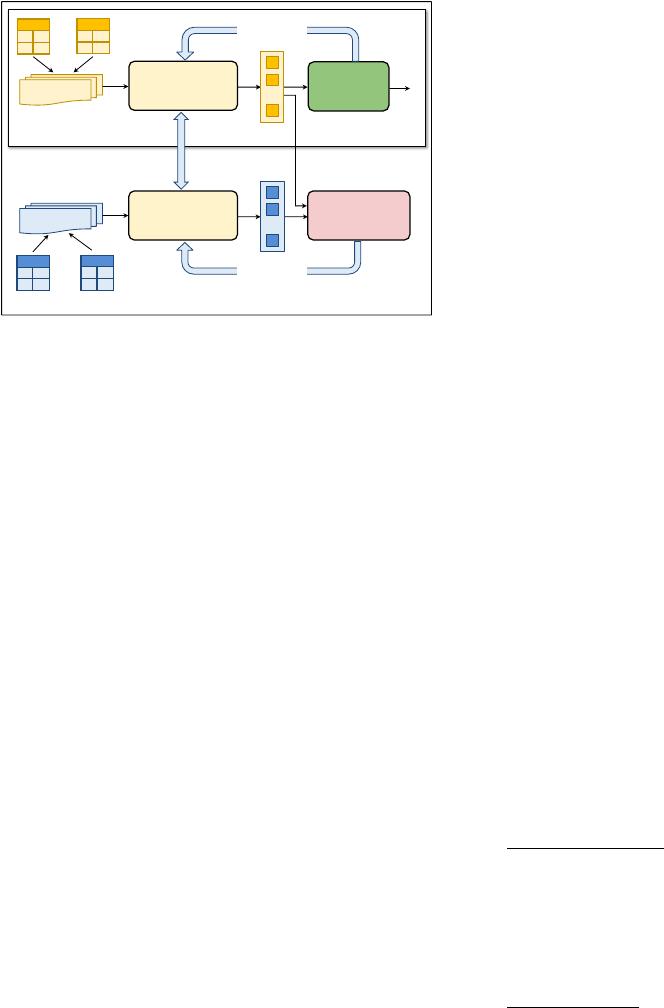
Feature Extractor
ℱ
Matcher
ℳ
Gradients
…
𝐴
S
(𝑎
S
, 𝑏
S
, 1)
Labeled
Source Data
𝒙
𝐒
Feature Extractor
ℱ
Feature Aligner
𝒜
…
𝒙
𝑻
Gradients
(𝑎
T
, 𝑏
T
, ? )
Unlabeled
Target Data
1/0
𝐵
S
𝐴
T
𝐵
T
Shared
Weights
(a) Deep ER
(b) DA for Deep ER
Figure 3: Domain adaptation for deep entity resolution. (a) A
general framework for deep entity resolution. (b) Our DADER
framework of domain adaption for deep entity resolution.
entity pairs
(𝑎, 𝑏) ∈ 𝐴 × 𝐵
that refer to the same real-world objects.
An entity pair is said to be matching (resp. non-matching) if they
refer to the same (resp. dierent) real-world objects.
A typical ER pipeline consists of two steps, blocking and match-
ing. The blocking step generates a set of candidate pairs with high
recall, i.e., pruning the entity pairs which are unlikely to match
(see [
67
] about DL for ER blocking). The matching step takes the
candidate set generated from the blocking step as input and deter-
mines which candidate pairs are matchings or non-matchings. Our
focus is on the domain adaption for the ER matching step.
Training data for ER.
We denote a labeled training set as
(D, Y)
,
where D ⊂ 𝐴 × 𝐵 is a set of entity pairs and Y is a label set. Each
entity pair
(𝑎, 𝑏) ∈ D
is associated with a label
𝑦 ∈ Y
that denotes
whether the pair of entities
𝑎
and
𝑏
is matching (i.e.,
𝑦 =
1) or non-
matching (i.e.,
𝑦 =
0). Figure 2 (a) shows an example training set.
Each pair consists of two entities from dierent tables, e.g.,
(𝑎
S
1
, 𝑏
S
1
)
,
and is associated with a 1/0 label.
Deep entity resolution.
Existing Deep ER solutions [
21
,
42
,
49
]
typically utilize a framework that consists of a Feature Extractor and
a Matcher, as shown in Figure 3 (a). Specically, given an entity pair
(𝑎, 𝑏)
, a Feature Extractor
F (𝑎, 𝑏)
:
𝐴 × 𝐵 → R
𝑑
, converts this pair
into
𝑑
-dimensional vector-based representation (a.k.a. features),
denoted by
x
, i.e.,
x = F (𝑎,𝑏)
. Then, features
x
will be fed into an
ER Matcher
M
, which is a DL-based binary classication model. The
ER Matcher
M
takes features
x
as input, and predicts a probability
ˆ
𝑦 of matching,
ˆ
𝑦 = M (x) = M(F (𝑎, 𝑏)). (1)
Given a training set (
D
,
Y)
, by iteratively applying minibatch
stochastic gradient descent, parameters of both
F
and
M
are opti-
mized, and thus they are improved to distinguish matching entity
pairs from the non-matchings.
Example 1. Consider the ER dataset in Figure 2 (a). Suppose that
we use the pre-trained language model Bert [
19
] to implement Feature
Extractor
F
, like Ditto [
42
]. Given an entity
𝑎
,
F
rst serializes all
attribute-value pairs
{(attr
𝑖
, val
𝑖
)}
1≤𝑖 ≤𝑘
of
𝑎
into a token sequence
(i.e., text) by applying the following function,
S(𝑎) = [ATT] attr
1
[VAL] val
1
. . . [ATT] attr
𝑘
[VAL] val
𝑘
,
where
[ATT]
and
[VAL]
are two special tokens for start-
ing attributes and values respectively. For example, we
serialize entity
𝑎
S
1
into a token sequence, i.e.,
S(𝑎
S
1
) =
[ATT] title [VAL] balt . . . [ATT] price [VAL] 239.88 .
Then,
F
converts
(𝑎
S
, 𝑏
S
)
into token sequence
S(𝑎
S
, 𝑏
S
) =
[CLS] S(𝑎
S
) [SEP] S(𝑏
S
) [SEP]
, where
[SEP]
is a special token sep-
arating the two entities and
[CLS]
is a special token in Bert to encode
the entire sequence. Finally, we feed
S(𝑎
S
, 𝑏
S
)
into Bert and obtain
a vector-based representation
x
(e.g., the emb edding of
[CLS]
). After
that, we can use a fully connected layer to implement Matcher
M
,
which then produces matching probability
ˆ
𝑦
from
x
. Thus, given all
the labeled pairs
{(𝑎
S
, 𝑏
S
, 𝑦
S
)}
in Figure 2 (a), we can train both
F
and M by minimizing a loss function over {(𝑦
S
,
ˆ
𝑦)}.
3 DOMAIN ADAPTATION FOR DEEP ER
Next we describe domain adaptation for deep ER. We consider a
labeled source ER dataset
(D
S
, Y
S
) = {(𝑎
S
, 𝑏
S
, 𝑦
S
)}
and an unla-
beled target dataset
D
T
= {(𝑎
T
, 𝑏
T
)}
, and aim to nd the best Fea-
ture Extractor and Matcher for producing accurate matching/non-
matching results on target
D
T
. A crude method is to directly use
Feature Extractor
F
and Matcher
M
trained using
D
S
to predict
D
T
. However, because source and target data may not come from
the same domain, the features extracted by
F
for the source and the
target may not follow the same data distribution, leading to a do-
main shift problem. Consequently,
M
trained using the source data
cannot correctly predict the target data. To address this obstacle,
we study the problem of domain adaptation for ER, and introduce a
framework DADER that unies the representative methods.
High-level idea of DA for ER.
Figure 3 (b) shows the
DADER
framework. The high-level idea is to learn from data instances what
is the best way of generating and aligning the features for the source
and the target entity pairs, such that the Matcher trained on the
labeled source can be used (or adapted) to the unlabeled target. To
this end,
DADER
introduces a Feature Aligner
A
, which guides Fea-
ture Extractor
F
to generate domain-invariant and discriminative
features and updates Matcher
M
accordingly. Formally, we dene
the alignment loss and the matching loss as follows.
(1) Domain-invariant.
Intuitively, we would like the distributions of
source features
x
S
and target features
x
T
to be as close as possible.
To this end, the Feature Aligner
A(x
S
, x
T
)
:
R
𝑑
× R
𝑑
→ R
, is
utilized to produce an alignment loss
L
𝐴
. For example, a simple
method for
L
𝐴
is to dene a distance between the means of source
and target distributions. A more comprehensive design exploration
for fullling L
𝐴
will be discussed in Section 4.
(2) Discriminative.
We also consider a matching loss
L
𝑀
that mea-
sures the dierence between predicted and ground-truth results on
the source. Recall that, given an entity pair
(𝑎
S
, 𝑏
S
)
in the source
dataset, our Matcher
M
makes a prediction as
ˆ
𝑦 = M (F (𝑎
S
, 𝑏
S
))
.
Thus, matching loss
L
𝑀
is dened as
L
𝑀
= loss({(
ˆ
𝑦, 𝑦
S
)})
, where
loss is a function, such as cross entropy.
Now, we are ready to present the goal of DA for ER as nding
the best Feature Extractor
F
∗
and Matcher
M
∗
that minimize both
alignment loss L
𝐴
and matching loss L
𝑀
, i.e.,
F
∗
, M
∗
= arg min
F,M
aggregate(L
𝐴
, L
𝑀
). (2)
of 15
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
最新上传
下载排行榜
1
2
9-数据库人的进阶之路:从PG分区、SQL优化到拥抱AI未来(罗敏).pptx
3
1-PG版本兼容性案例(彭冲).pptx
4
2-TDSQL PG在复杂查询场景中的挑战与实践-opensource.pdf
5
6-PostgreSQL 哈希索引原理浅析(文一).pdf
6
3-AI时代的变革者-面向机器的接口语言(MOQL)_吕海波.pptx
7
8-基于PG向量和RAG技术的开源知识库问答系统MaxKB.pptx
8
4-IvorySQL V4:双解析器架构下的兼容性创新实践.pptx
9
7-拉起PG好伙伴DifySupaOdoo.pdf
10
《云原生安全攻防启示录》李帅臻.pdf

相关文档
评论