




SIGMOD2024_ESTELLE:An Efficient and Cost-effective Cloud Log Engine_华为云.pdf
免费下载

ESTELLE: An Eicient and Cost-eective Cloud Log Engine
Yupu Zhang
∗
University of Electronic Science and
Technology of China
Chengdu, China
zhangyupu@std.uestc.edu.cn
Guanglin Cong
∗
Cloud Database Innovation Lab of
Cloud BU, Huawei Technologies Co.
Chengdu, China
congguanglin@huawei.com
Jihan Qu
University of Electronic Science and
Technology of China
Chengdu, China
qujihan@std.uestc.edu.cn
Ran Xu
Cloud Database Innovation Lab of
Cloud BU, Huawei Technologies Co.
Chengdu, China
xuran215@huawei.com
Yuan Fu
University of Electronic Science and
Technology of China
Chengdu, China
fuyuan@std.uestc.edu.cn
Weiqi Li
Cloud Database Innovation Lab of
Cloud BU, Huawei Technologies Co.
Chengdu, China
liweiqi4@huawei.com
Feiran Hu
Cloud Database Innovation Lab of
Cloud BU, Huawei Technologies Co.
Chengdu, China
hufeiran@huawei.com
Jing Liu
Cloud Database Innovation Lab of
Cloud BU, Huawei Technologies Co.
Chengdu, China
liujing160@huawei.com
Wenliang Zhang
†
Cloud Database Innovation Lab of
Cloud BU, Huawei Technologies Co.
Chengdu, China
zhangwenliang14@huawei.com
Kai Zheng
†
University of Electronic Science and
Technology of China
Chengdu, China
zhengkai@uestc.edu.cn
ABSTRACT
With the advancement of cloud computing, more and more enter-
prises are adopting cloud services to build a variety of applications.
Monitoring and observability are integral to the complex and fragile
cloud-native architecture. As an extremely important data source
for both, logs play an indispensable role in applications such as code
debugging, root cause analysis, troubleshooting, and trend analysis.
However, the inherent characteristic of cloud logs, with TB-level
daily data production per user and continuous growth over time and
with business, poses core challenges for log engines. Traditional log
management systems are inadequate for handling the requirements
of massive log data high-frequency writing and storage, along with
low-frequency retrieval and analysis in cloud environments. Explor-
ing a low-cost, high-performance cloud-native log engine solution
is an extremely extraordinary challenging task. To tackle these chal-
lenges, we propose a cost-eective cloud-native log engine, called
∗
Equal contribution.
†
Corresponding authors. The corresponding author, Kai Zheng, is with Shenzhen
Institute for Advanced Study, University of Electronic Science and Technology of
China, Shenzhen, China.
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for prot or commercial advantage and that copies bear this notice and the full citation
on the rst page. Copyrights for components of this work owned by others than the
author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or
republish, to post on servers or to redistribute to lists, requires prior specic permission
and/or a fee. Request permissions from permissions@acm.org.
SIGMOD-Companion ’24, June 9–15, 2024, Santiago, Chile.
© 2024 Copyright held by the owner/author(s). Publication rights licensed to ACM.
ACM ISBN 979-8-4007-0421-5/24/06.. . $15.00
https://doi.org/10.1145/3626246.3653387
ESTELLE, equipped with a low-cost pluggable log index framework.
This engine features a compute-storage separation and read-write
separation architecture, enabling linear scalability. We designed a
near-lock-free writing process for handling high-frequency writing
demands of massive logs. Object storage is used to signicantly
reduce storage costs. We also tailored ESTELLE Log Bloom lter
and approximate inverted index for this cloud-native engine, apply-
ing them exibly to enhance query eciency and optimize various
queries. Extensive experiments on real open-source log datasets
have demonstrated that the ESTELLE Log Engine achieves ultra-
high single-core CPU write speeds and pretty low storage costs.
Furthermore, when equipped with the complete index framework, it
also maintains fairly low query latency across various log scenarios.
CCS CONCEPTS
• Information systems
→
DBMS engine architectures; Struc-
tured text search.
KEYWORDS
cost-eectiveness;Bloom lter;cloud-native;log engine;index frame-
work
ACM Reference Format:
Yupu Zhang, Guanglin Cong, Jihan Qu, Ran Xu, Yuan Fu, Weiqi Li, Feiran
Hu, Jing Liu, Wenliang Zhang, and Kai Zheng. 2024. ESTELLE: An Ecient
and Cost-eective Cloud Log Engine. In Companion of the 2024 International
Conference on Management of Data (SIGMOD-Companion ’24), June 9–15,
2024, Santiago, Chile. ACM, New York, NY, USA, 13 pages. https://doi.org/
10.1145/3626246.3653387
201
SIGMOD-Companion ’24, June 9–15, 2024, Santiago, Chile. Yupu Zhang et al.
1 INTRODUCTION
Across the last several years, more and more enterprises have
rapidly migrated cloud-native applications to cloud-native infras-
tructures [
7
], in the form of microservices [
5
], serverless and con-
tainer [
25
,
32
] technologies. With a vast number of applications
running on hundreds to thousands of machines, this distributed
architecture is highly complex yet extremely fragile [
41
], prone
to interruptions due to failures [
19
], and can even lead to partial
paralysis of the Internet [
29
]. Therefore, monitoring is crucial for
checking the operational status of applications. It not only requires
issuing alerts when failures occur but also demands early detec-
tion of bugs and issues hidden in the development environment
that may be exposed in the production environment, aiming to
prevent system interruptions [
29
]. However, compared to previ-
ous architectures, the unique characteristics of cloud-native archi-
tecture (e.g., Intrusiveness, Resilience, Reliability, etc. [
1
]) make
traditional monitoring solutions and strategies inadequate for mon-
itoring tasks [16, 35].
In recent years, observability, as an extension of monitoring,
has become an indispensable feature of the environment of cloud-
native architectures [
27
]. Logs, metrics, and traces, known as the
three pillars of observability, are the raw data needed to obtain an
internal view of the health and behavior of applications and mi-
croservices [
26
]. Logs, as a crucial data source for monitoring and
observability, capture the details of each request and can be used for
debugging [
37
], root cause analysis [
41
], exploratory troubleshoot-
ing [
14
], and other applications, making them indispensable for
any production-grade system [29].
In any production-grade system, the volume of logs increases sig-
nicantly over time and with business growth. Building a low-cost
log engine for an observability platform is an extraordinary mission.
We summarize the challenges we encountered in our production
environment as follows:
Challenge 1: Heavy and Skewed Log Writes. The hundreds
or thousands of various microservices and programs running on
the cloud-native infrastructures generate a large amount of logs
every day, with log generation times concentrated and frequently
encountering bursts of write demands. For example, in our produc-
tion environment, many users generate several hundred terabytes
of logs daily, and the total volume of logs produced each day contin-
ues to increase with business growth. Within a day, log writes are
mainly concentrated within a few hours. Therefore, the ability to
store and rapid write such massive log data at a low cost is crucial.
Challenge 2: Low Frequency and Heavy Log Queries. Com-
pared to write operations, the frequency of log queries is much
lower, and the majority of logs will be never queried. However,
executing precise queries within such a vast volume of data and
within an acceptable latency (ranging from hundreds of millisec-
onds to a few seconds) is undeniably challenging. Moreover, many
queries involve a wide time span, often ranging from a day to a
week, and sometimes even longer, up to a month or more. Therefore,
establishing reasonable data partitioning and designing ecient
and practical indexes and caches are essential.
Challenge 3: Various Log Queries and Important Log Ag-
gregations. In addition to the basic full-text queries, a log engine
needs to support several other crucial types of queries to meet
the requirements of monitoring and observability. Utilizing AND
queries is essential for ltering relevant events or operations that
meet multiple conditions, providing a more comprehensive context.
Additionally, prex fuzzy queries can be employed to quickly locate
or lter logs related to services or components with specic prexes,
facilitating further analysis and issue resolution. Log aggregation
is crucial for identifying trends and helping users recognize bot-
tlenecks, performance issues, or even network threats based on
data collected over a period. However, histogram queries for high-
frequency words suer from signicant time and resource consump-
tion, limiting their capability for rapid trend analysis. Therefore,
designing a system that can optimize various queries and eciently
index data is paramount.
Challenge 4: Low-Cost Log Engine System. The trait of logs
growing with time and business makes low cost a necessary require-
ment for a log engine. It is also an indispensable part of a low-cost
observability platform. Here, low cost refers to the ecient writes,
storage, and queries of massive log data with fewer resources within
an acceptable time frame. Resources here primarily include CPU,
memory, I/O, etc. Therefore, utilizing low-cost storage for massive
logs and designing a dedicated cost-controllable index framework
for this specic scenario is both necessary and practical.
However, there is no existing log engine that meets all of the
above requirements. Among these log engines, some choose to
have no index at all [
9
,
18
,
23
], some choose to build inverted
indexes in real-time when writing logs [
2
,
3
,
7
,
9
,
40
]. Specically,
SLS [
9
] oers two modes: one with no index and another utilizing
inverted indexes. Additionally, ClickHouse [
39
] oers an index-free
architecture and uses the standard Bloom lter [
6
] as the index.
Having no index at all allows the log engine to write logs quickly
but sacrices support for ecient queries. Constructing an inverted
index of a size comparable to the data size during log writing can
lead to slow writing speeds and high storage costs. The use of
an index-free architecture with Bloom lters as the log indexes
provides ecient log indexing for log queries with minimal impact
on log writing speed. However, the standard Bloom lter is not
suitable for a low-cost log engine. When using the standard Bloom
lter for word ltering, fetching all the Bloom lters into memory
at once would incur signicant I/O overhead. On the other hand, if
only the word related bits from all the Bloom lters are retrieved
into memory, the storage medium needs to have ecient random
access capability. Both of these approaches do not align with our
denition of low cost. Furthermore, none of the aforementioned log
engines optimize for various critical queries, especially histogram
queries for high-frequency words.
In this paper, we propose a cost-eective cloud-native log engine,
called ESTELLE, equipped with a low-cost pluggable log index
framework to address the challenges mentioned above. To address
heavy and skewed log writes, we introduce object storage to enable
low-cost storage of logs and their indexes. We apply a cloud-native
architecture with storage-compute separation to support linear
scaling of write capacity, and we carefully design an approximately
lock-free log writing process. To handle low-frequency and heavy
log queries, we adopt a dual time ltering strategy, implement
multiple caches, and introduce an ecient indexing framework. To
address various log queries and important log aggregations, we
congure an index set with multiple pluggable components for
202
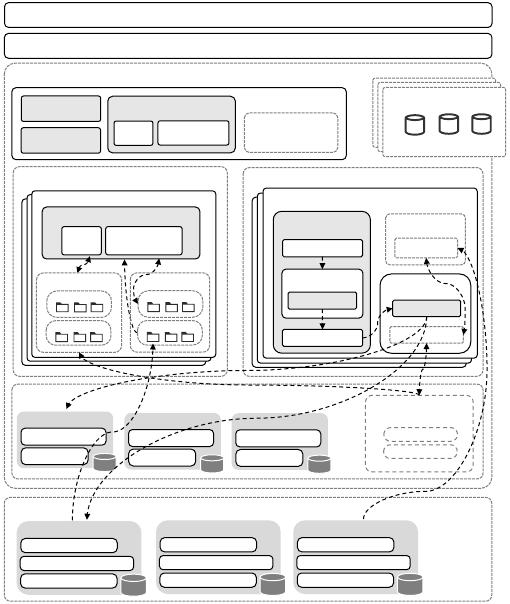
ESTELLE: An Eicient and Cost-eective Cloud Log Engine SIGMOD-Companion ’24, June 9–15, 2024, Santiago, Chile.
each data block. We design a ESTELLE Log Bloom lter to optimize
full-text and prex fuzzy queries and a xed-length Approximate
Inverted Index for optimizing AND queries on low-frequency words
and histogram queries on high-frequency words. Specically, to
enable quick returns of log aggregation results, we set the histogram
query in the progressive query mode. To meet the requirements
of a low-cost engine, we utilize object storage for log storage and
design the index set corresponding to each data block as a cost-
eective, cloud-native-friendly version. Specically, for ESTELLE
Log Bloom lter and the Approximate Inverted Index, we carefully
design I/O-friendly columnar-store formats and provide strategies
and theoretical supports for balancing performance and cost.
Our contributions can be summarized as followed:
1) We implement a cost-eective, cloud-native log engine fea-
turing read-write separation and storage-computation separation.
This design facilitates rapid scaling in response to burst write and
query scenarios. Furthermore, we propose an near-lock-free writ-
ing process based on this framework to accommodate the demands
of massive log data ingestion.
2) We propose a low-cost pluggable log index framework pri-
marily composed of ESTELLE Log Bloom lter and Approximate
Inverted Index. Both are tailor-made, I/O-friendly index structures
specically designed for cloud-native architectural log engines.
The former is employed for eective word ltering, while the latter
optimizes histogram queries for high-frequency words and AND
queries for low-frequency words. To our knowledge, the ESTELLE
Log Bloom lter is the rst Bloom lter variant specically cus-
tomized for this scenario.
3) We report on experiments using a real open-source log dataset,
showing that the ESTELLE Log Engine not only attains exception-
ally high single-core CPU write speeds, but also incurs relatively
low storage expenses. Moreover, when integrated with the complete
index framework, it consistently ensures fairly low query latency
in diverse log scenarios.
The remainder of the paper is organized as follows. Section 2
presents low-cost cloud-native ESTELLE Log Engine. Section 3
introduces a low-cost pluggable log index framework. Section 4 de-
scribes the detailed processes of several types of optimized queries.
Section 5 details the experiments and evalution. Section 6 provides
a brief introduction of related work. Section 7 gives the conclusion.
2 ESTELLE LOG ENGINE
This section introduces the ESTELLE Log Engine, covering its cloud-
native architecture, storage, writing, and querying processes.
2.1 Architecture Overview
Figure 1 shows the architecture of ESTELLE Log Engine. It is a
cloud-native architecture featuring read-write and storage-compute
separation. Below is a brief introduction to some main modules.
Meta Cluster is primarily responsible for mananging system
metadata and the entire cluster. It stores metadata, including data-
base schema, table schema, permissions information, etc. Addition-
ally, it maintains the Retention Policy (i.e., RP) that species the
period data is to be retained. Meta Cluster also monitors the status
of nodes within the entire cluster. It plays a crucial role in fault
Elastic Load Balancer (ELB)
Application (Protocols, e.g., SPL, SQL, HTTP)
Execution Layer
Read Router
Coordinator
Optimizer
Query Executor
DAG
Progressive
Query
Cloud Storage (OBS)
Shard0
Meta data
Log Indexes (C)
Log Blocks
……
Query Executor
Worker
Query Cluster
DAG
Progressive
Query
Local Cache
Online Cache
Offline Cache
Meta Cluster
Schema
RP
Status
Cloud Storage (SFS)
……
High-frequency
Word Hash Tables
Version0
Version1
……
Shard0
Log Indexes (R)
Log Blocks
Shard1
Log Indexes (R)
Log Blocks
Shard2
Log Indexes (R)
Log Blocks
Shard1
Meta data
Log Indexes (C)
Log Blocks
Shard2
Meta data
Log Indexes (C)
Log Blocks
Worker
Write Cluster
Offline Task
Collector
Data Builder
tokenizer
Encoder
Online Write
Task
Data Queue
Memory
memtable
map cache
Memory
Cache
Memory Cache
Online Cache
Offline Cache
Figure 1: The Architecture of ESTELLE Log Engine
detection and failover. Furthermore, it is also in charge of the allo-
cation and takeover of shards, determing, for instance, which write
state nodes are responsible for specic shards. Meta Cluster itself
employs raft algorithm [31] to ensure information consistency.
Execution Layer executes query and write operations, serving
as the computational core of the ESTELLE Log Engine. It is essen-
tially a cluster composed of numerous nodes, where each node
can operate in either a query or write state. When ELB receives a
write request from the upper-level application, it randomly assigns
it to a node, which is then referred to as a write state node. The
query state node is further subdivided into two types: coordinator
and subquery node. The query state node that receives query re-
quests dispatched by the ELB is referred to as the coordinator. The
query state node that receives subquery requests dispatched by a
coordinator is referred to as the subquery node of the coordinator.
Each write state node and subquery node in the cluster contains a
set of workers, which can be understood as threads. Each worker
corresponds to one shard. The log writing process performed by
write state nodes and the query process executed by query state
nodes are introduced in Section 2.3 and Section 2.4, respectively.
Object Storage Service OBS [
12
] (i.e., Object Storage Service) is
a product from Huawei Cloud, oering massive, secure, highly reli-
able, and cost-eective object storage services. OBS provides web
service interfaces based on the HTTP/HTTPS protocol, allowing
multiple cloud servers to access it over the Internet. Moreover, OBS
uses the Erasure Code (EC) algorithm, instead of multiple copies, to
ensure data redundancy. Object storage has a lower cost compared
203
of 13
免费下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
最新上传

相关文档
评论