




作者:RisingWave 创始人 & CEO 吴英骏
相比于去年重金押宝于数据湖仓,Databricks 今年在宣传上可谓是“all in AI”:不仅请了 Eric Schmidt(前任谷歌 CEO )与 Satya Nadella(现任微软 CEO )等大佬为自家 AI 产品布道,更是直接将本届大会的主题定成了“AI 时代”。

更有意思的是,就在峰会开始两天前( 6 月 26 日),Databricks 官方宣布以高达 13 亿美金的估值收购生成式 AI 平台初创公司 MosaicML 。
这笔交易更让人感受到了 Databricks 在 AI 领域方面布局的决心。要知道,MosaicML 从成立到收购仅仅有两年左右的时间,而传闻中他们在被收购前正在进行但主动放弃的 B 轮融资估值“仅”为 4 亿美金。
而当亲身参与到这场盛会之后,我却感概:在 AI 时代,无数据,不 AI!
Databricks 的 AI 新产品
纵观整个 Data+AI 峰会,尽管 Databricks 把宣传的重心放在了 AI 上面,但实际发布的 AI 产品并不多,这让人感到 “AI” 这个词仅仅是组织者的噱头。在这次发布的 AI 相关的产品中,有两个产品很吸引眼球:英文 SDK 与 Lakehouse AI。
英文SDK
“英语是新的 Spark 编程语言”,这是 Databricks 为其新发布的英文 SDK 所给出的宣传标语。
作为一个大数据平台,Apache Spark 有着不低的学习门槛:用户需要学习 Java 或 Scala 等语言并调用 Spark 转有的接口才能进行编程。
尽管 Spark 在这些底层接口上提供了 Python 与 SQL 语言的支持,但许多非技术背景的工作者,如市场、销售等岗位员工,并不理解如何使用这些高级编程语言。英文 SDK 的诞生便是为了进一步降低 Spark 的使用门槛而诞生的。
通过英文 SDK ,用户可以直接在 Databricks 平台内输入英语,而 Databricks 内置的生成式 AI 大模型会将英语直接转化成 PySpark 代码,并通过 Spark 引擎进行执行。
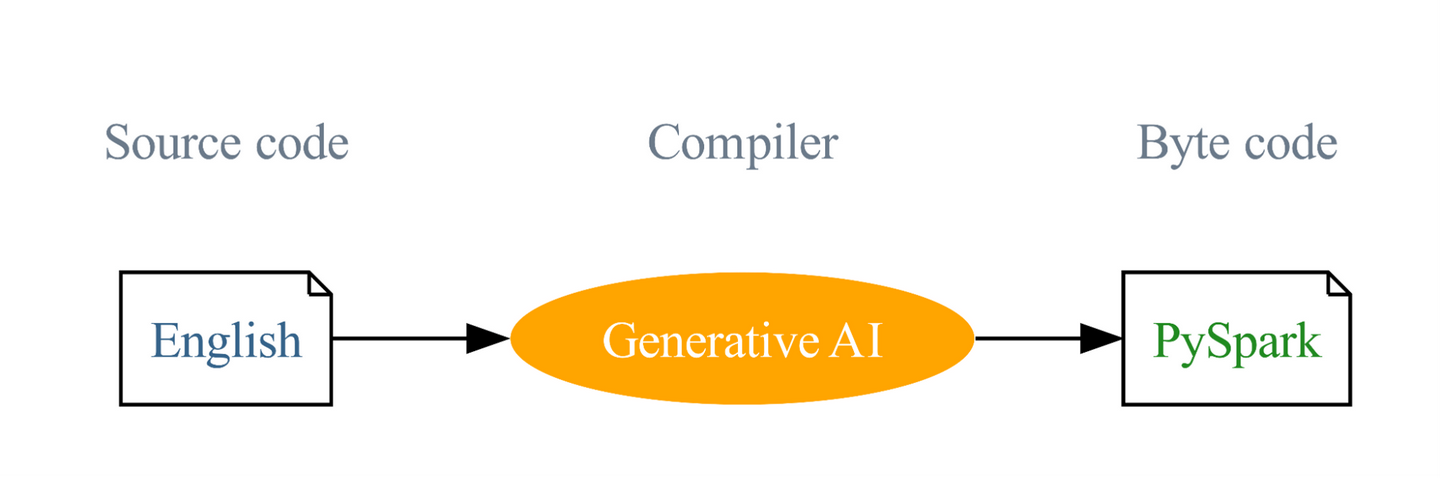
很显然,英文 SDK 这个产品深受 ChatGPT 启发。尽管 ChatGPT 也有一定能力将英文直接翻译成代码,但其对 Spark 接口并没有深入了解,翻译正确率不高。英文 SDK 这个项目通过给大模型更多更准确的提示(prompt),并通过对大模型返回结果进行有效矫正,可以实现更高正确率的翻译。
Lakehouse AI
Lakehouse AI 这个产品可以说是 Databricks 为生成式 AI 应用给出的全家桶解决方案了。
一句话概括,Lakehouse AI 能够帮助用户更高效的构建 AI 应用。而如果我们仔细看Lakehouse AI 这个产品,就不难发现,实质上 Databricks 就是在自己现有机器学习组件(包括 AutoML、MLflow 等)的基础上,添加了向量检索以及特征服务这两个功能。
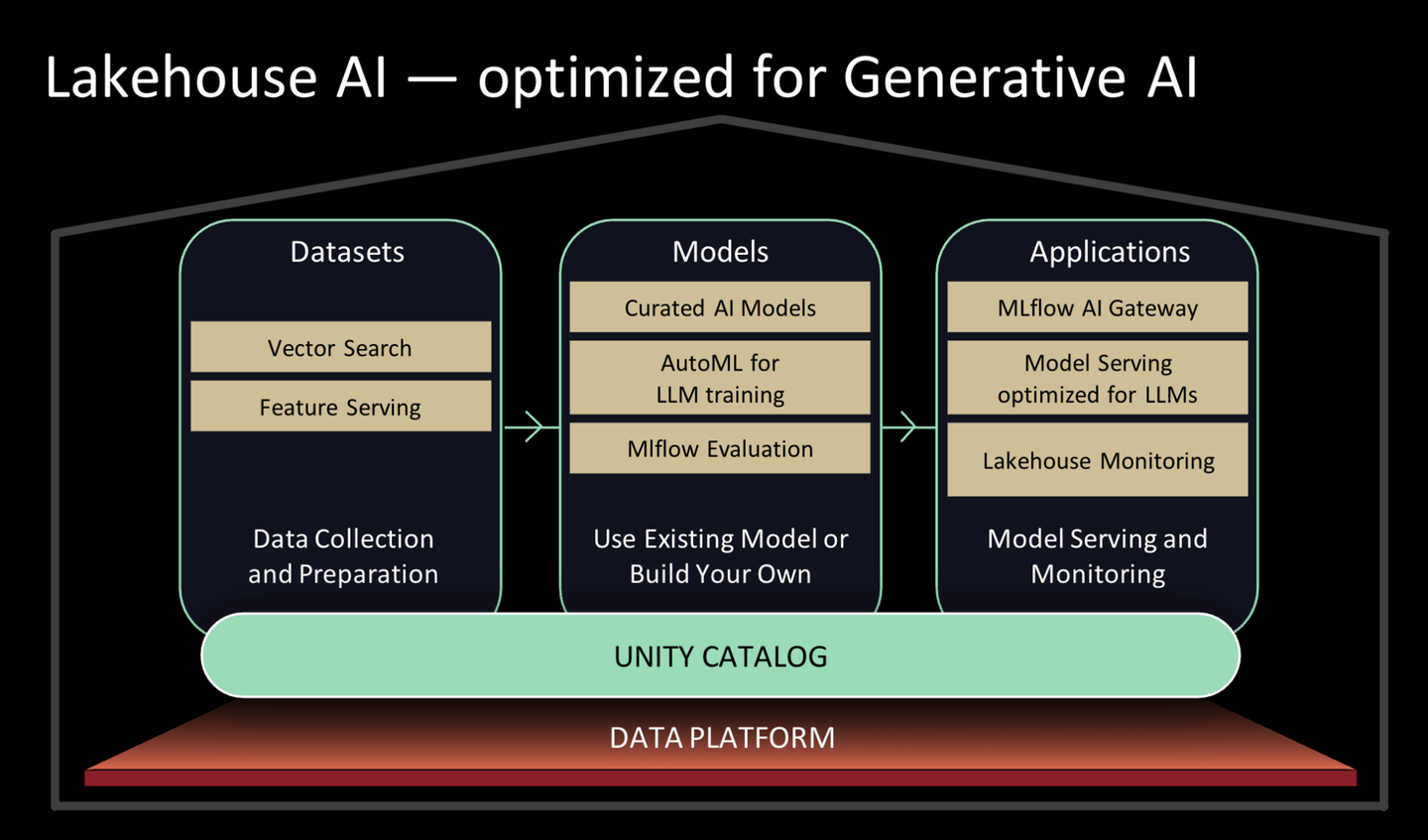
向量数据库想必是今年在数据库领域的一个热点。
Databricks 直接入场做向量检索意味着 Databricks 用户将不再需要使用购买第三方向量数据库便能够进行向量检索操作。
这一产品非常适合 Databricks,毕竟,用户将大量数据存在 Databricks 的数据湖仓中,导出数据到第三方平台构建向量索引十分麻烦。在 Databricks 内部便完成向量索引构建与向量检索,将会大大降低用户开发 AI 应用的成本。
类似于向量检索,特征服务也是一个简化用户开发 AI 应用的极佳功能。不管是用户正准备训练模型还是希望进行机器学习推理,可以直接使用 Databricks 内置的特征服务,而不再使用第三方组件。
Databricks 的数据新产品
尽管并不如 AI 产品那样被大篇幅宣传,但 Databricks 依然实实在在的推出了不少新的数据相关的产品。这些产品让人感到“扎实”与“放心”。毕竟,数据层的产品不应需要被过度商业化包装,而应是直击用户痛点,为用户提供可靠的服务。总的来说,Databricks 在数据方面的所推出的产品可以被三个关键词描述:开放、实时、安全。
开放
作为一家开源商业化数据平台公司,Databricks 相比于其竞争对手 Snowflake 来说,最核心的差异点之一便是开放性。
开放源代码带给用户的是一种值得信任的感觉,而开放源代码并没有解决用户所担心的供应商锁定(vendor lock-in)问题。毕竟,没有用户希望被单一供应商所绑定,因为这意味着用户在使用产品时失去了议价的权利。
Databricks 在今年推出的 Delta Sharing 功能便是针对这一问题提供的解决方案。Delta Sharing 协议可以让用户轻松的使用自己的第三方工具来直接访问 Delta Lake 中的数据。

值得一提的是,Delta Sharing 可以允许用户使用 Iceberg 和 Hudi 来读取 Delta Lake 中的数据。要知道,Hudi、Iceberg 这两个数据湖产品与 Delta Lake 属于直接竞争关系,而Databricks 所发布的 Delta Sharing 实质上是让用户能够使用竞争对手的产品来读取自家数据湖中的数据。
这一做法体现出的是 Databricks 的自信:用户可以无脑选择使用 Delta Lake 存放数据,如果用的不满意,也可以直接迁去其他数据湖中。
实时
本次峰会的一个亮点便是 Databricks 对流处理领域的大幅投入。Databricks 直接发布了两套流处理相关的产品:Delta Live Tables 以及 Project Lightspeed。Delta Live Tables可以被认为是 Databricks 数据湖仓中的实时物化视图。这一功能可以让用户直接在系统中访问到最新的数据计算结果。
相比于 Delta Live Tables,更令人激动的是 Databricks 最新研发的 Project Lightspeed。
这一项目被 Databricks 称之为下一代 Spark Structured Streaming 引擎,而其与 Spark 生态的高度集成可以让用户直接在 Databricks 的数据湖仓上进行数据流处理。很显然,流处理使用量在过去几年间的高速增长让 Databricks 看到了机会。随着 Databricks 的入场,相信这一赛道会变得更加有趣。
安全
数据安全与隐私问题相信已经是近几年的热点话题了。在本次峰会中,Databricks 也在不同场合以不同方式着重强调了他们对数据安全与隐私的重视。尽管没有特别的产品推出,但可以感受到,几乎每个产品的安全性都会被着重提及。例如,Delta Sharing 项目的初衷是让用户共享数据,但 Databricks 着重强调了其开发的产品在安全方面的严格保障。Data lineage 功能也能够使用户观测到数据使用的整个生命周期,让用户对存放在 Databricks 平台上的数据感到更加放心。
数据是AI的基石
数据是 AI 的基石。这是我与诸多参会者深入沟通后得出的结论。
相信所有人都认同一个事实:一切生成式AI大模型的训练都需要海量数据的支持。随着时间的推移,尽管数据越来越多,但是种类也变得越来越复杂。而由于各个网站、平台、地区、国家对自身数据的保护与管控变得愈发严苛,数据不可避免的会变得越来越昂贵。
如何对数据进行很好的组织、管理、使用、与保护,是一个值得深入研究的问题,而这也意味着一个巨大的市场。毕竟,AI的蓬勃发展几乎不可能离开强大的数据支持,只有有了数据这一坚实的基础,我们才能够很好的利用数据进行模型训练、构建AI应用。
Databricks Data+AI峰会用实际的产品证明了:无数据,不AI。

关于 RisingWave
RisingWave 是一款分布式 SQL 流处理数据库,旨在帮助用户降低实时应用的的开发成本。作为专为云上分布式流处理而设计的系统,RisingWave 为用户提供了与 PostgreSQL 类似的使用体验,并且具备比 Flink 高出 10 倍的性能以及更低的成本。了解更多:
