




对数据的洗择过程称之为数据预处理。根据不同类型的数据有不同的数据预处理方法,其中,针对因子研究,最常用的预处理方法就是:去极值、标准化
为啥要去极值?
去极值就是排除一些极端值的干扰 。
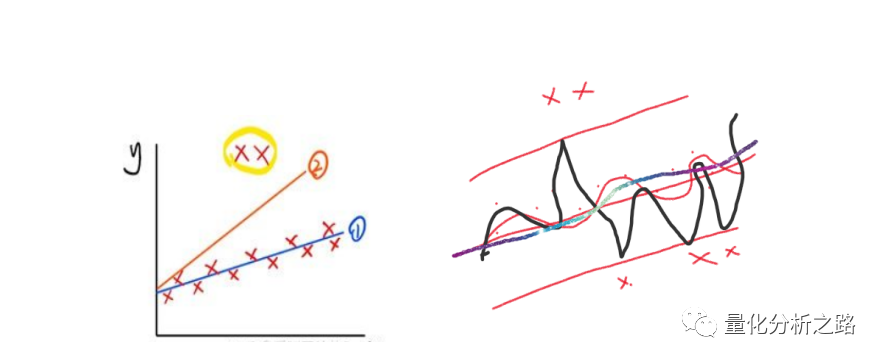
比如上图一 的组上面两个XX 。如果不去除 拟合出来的线可能是线2 而我们发现线1更符合大部分的规律。
还有右图 XX 明显比..的数量少很多 黑线的拟合要比红曲线 波动大很多。
只有排除极端值的干扰,才能更好的发现数据之间的规律。
如何去极值呢?
第一步:找出哪些是极端值
第二步:处理这些极端值
一:极端值的定义方法有很多,一般是先确定一个上下限,超出这个界限的就划为极端值,下面我们介绍经常使用的两种:3σ法和百分位法。
1、3σ法
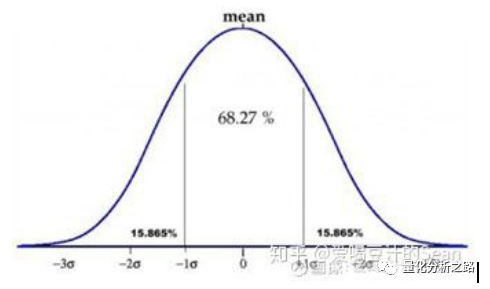
3σ法源于最经典的统计学3σ原则,即正态分布的数分布在(μ-3σ,μ+3σ)中的概率为99.73%,在3σ外的概率是0.27%,也就是图中尾部的那些数。
其中μ代表平均值,σ是标准差,3σ去极值法其实就是把离平均值太远的值算作极端值,那么多远是远呢?距离超过3倍标准差以上的就是远了。
2、百分位法
百分位法是对所有的观察值按从小到大进行排序,最小的百分之X和最大的百分之X的人就是极端值,通常情况下,这个X一般取2.5,最小的2.5%和最大的2.5%相加,一共5%的数值被去除。
二:处理的方法也有两种:截尾和缩尾
截尾:把找出的极端值直接去掉。
缩尾:所有大于上临界值的值全等于上临界值,所有小于下临界值的值全等于下临界值,相当于把超出临界值的点都拽回到边界上。
优矿的去极值函数winsorize进行演示:
优矿winsorize函数支持3σ和百分位法两种去极值方法,可以分别对相关参数进行调整。
universe = set_universe('A')print(type(universe))data_for_winsorize = DataAPI.MktStockFactorsOneDayGet(tradeDate=u"20150227",secID=universe,ticker=u"",field=['secID','LCAP','MFI'],pandas='1').set_index('secID')print(type(data_for_winsorize))data_for_winsorize.dropna(inplace=True)print(data_for_winsorize.describe())print(data_for_winsorize.head())复制
我们以去除 LCAP和MFI 中的极值为例。
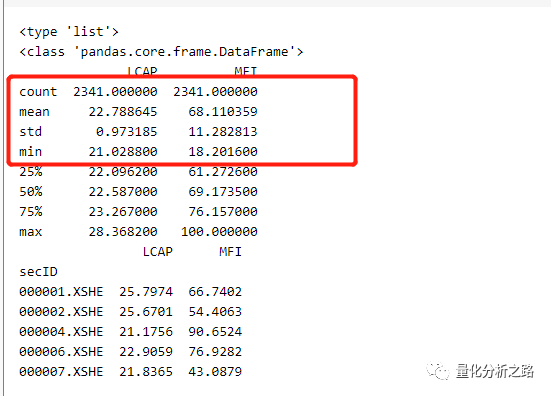
我们可以看到统计了2341个股票
LCAP的平均值为22.78
MFI的平均值为68.11在·
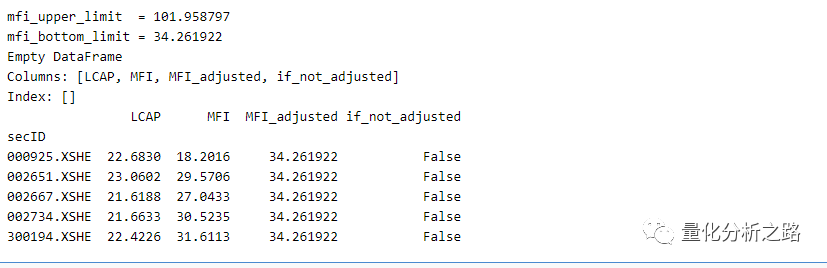
#人工去异常边界值#计算均值mfi_mean = data_for_winsorize['MFI'].mean()#计算标准差mfi_std = data_for_winsorize['MFI'].std()mfi_upper_limit = mfi_mean+3*mfi_stdmfi_bottom_limit = mfi_mean-3*mfi_stdprint('mfi_upper_limit = %f '%mfi_upper_limit)print('mfi_bottom_limit = %f '%mfi_bottom_limit)data_higher_than_upper = data_for_winsorize[data_for_winsorize['MFI']>mfi_upper_limit]data_lowwer_than_bottom = data_for_winsorize[data_for_winsorize['MFI']<mfi_bottom_limit]print(data_higher_than_upper.head())print(data_lowwer_than_bottom.head())复制
data_for_winsorize['MFI'][-50:].plot(color= 'g')data_for_winsorize['MFI_adjusted'][-50:].plot(color = 'r')复制
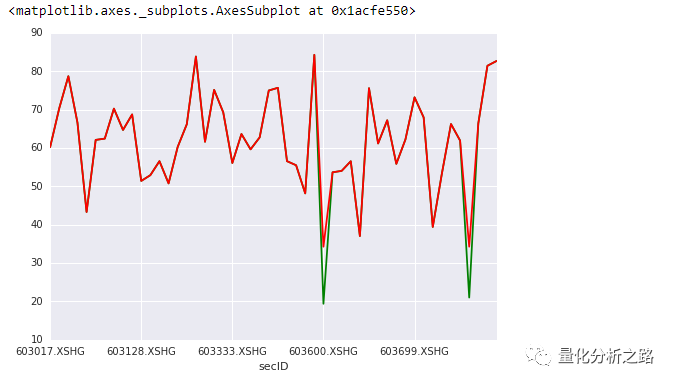
绿色为 极值 红色为缩尾优化后的结果。
